الگوریتم جدید مبتنی بر یادگیری ماشین، کد کپچا را بهراحتی حدس میزند
محققانی از انگلیس و چین، موفق به توسعهی الگوریتم جدیدی مبتنی بر یادگیری ماشین شدهاند که میتواند کدهای امنیتی کپچا (CAPTCHA) را بسیار سادهتر، سریعتر و با دقت بالاتری نسبتبه تمام روشهای قبلی حدس بزند.
الگوریتم جدید مبتنی بر شبکهی رقابتی مولد (GAN)، توسط دانشمندانی از دانشگاه لنکستر انگلیس، دانشگاه نورت وسترن چین و دانشگاه پکینگ چین توسعه یافته است. GANها، کلاس ویژهای از الگوریتمهای هوش مصنوعی هستند که برای مواردی که به مقادیر زیادی از داده برای آموزش دادن الگوریتم، دسترسی وجود ندارد، بهکار برده میشوند. معمولا در الگوریتمهای مبتنی بر یادگیری ماشین، برای آنکه الگوریتم بتواند کار خود را بهدرستی و با دقت بالاتری بهانجام برساند، نیاز به میلیونها داده برای آموزش الگوریتم وجود دارد.
الگوریتم GAN دارای مزیتهای قابلتوجهی است. یکی از مزایای الگوریتم GAN آن است که میتواند با استفاده از دادههای اولیهی بسیار کمتری نسبت به سایر الگوریتمها کار کند. علت آن است که الگوریتم GAN از مولفهی موسوم به «مولد» یا «generative»، برای تولید دادهی شبیه بهیکدیگر استفاده میکند. سپس، دادههای تولیدشده به الگوریتم «حلکننده» یا «solver» تغذیه میشوند. این الگوریتم تلاش میکند تا خروجی را حدس بزند.
وقتی دو عنصر GAN دربرابر یکدیگر قرار میگیرند، قسمت solver یا حلکنندهی الگوریتم، عملکرد بهتری از خودش نشان میدهد و شبیه به این است که با میلیونها داده، آموزش دیده باشد. محققان انگلیسی و چینی، از این ایده برای شکستن کد CAPTCHA استفاده کردند. اکثر قریب به اتفاق مطالعات قبلی انجامشده در این زمینه، از الگوریتمهای یادگیری ماشین کلاسیک استفاده میکردند که نیاز به مقادیر زیادی از دادههای اولیهی آموزشدادهشده به سیستم بود.
محققان معتقدند که در دنیای واقعی، کسی که قصد حمله به یک وبسایت را دارد، نمیتواند میلیونها کد کپچا (CAPTCHA) برای وبسایت یا API تولید کند و شناسایی نشود یا آن وبسایت ممنوعیتی برای ورود وی درنظر نگیرد. بههمین دلیل، محققان در تحقیق خود، تنها از ۵۰۰ کد متنی کپچا از هر یک از ۱۱ سرویس کد متنی CAPTCHA برای ۳۲ وبسایت برتر از نظر الکسا استفاده کردند. محققان معتقدند:
برای جمعآوری ۵۰۰ کپچا، کمتر از ۲ ساعت زمان (کمتر از ۳۰ دقیقه برای بیشتر طرحها)، و کمتر از ۲ ساعت برای برچسبگذاری آنها برای یک کاربر زمان صرف شد. این بدان معنی است که تلاش و هزینهی کمتری برای شکستن کد کپچا صرف شده است.
در جدول ذیل، فهرستی از دادههای آموزشی دیده میشود که شامل کد متنی CAPTCHA از سایتهایی همچون ویکیپدیا، مایکروسافت، eBay، بایدو، گوگل، Alipay، JD، Qihoo360، سینا، ویبو و Sohu است. محققان پس از جمعآوری و آموزش حلکنندههای GAN با استفاده از ایجاد بیش از ۲۰۰٫۰۰۰ کد متنی کپچای مصنوعی، توانستند الگوریتمهای خود را در مقایسه با سایر سیستمهای کد متنی کپچا که در اینترنت استفاده میشوند، مورد آزمایش قرار دهند که پیش از این توسط محققان دانشگاهی دیگری مورد آزمایش قرار گرفته بودند. محققان اعلام کردند:
جدول، مقایسهی خوبی بین روشهای حمله قدیمی با روش الگوریتم جدید نشان میدهد. در این آزمایش، رویکرد جدید در مقایسه با تمام روشهای قبلی، عملکرد بهتر و نتایج قابلتوجه بهتری را نشان میدهد.
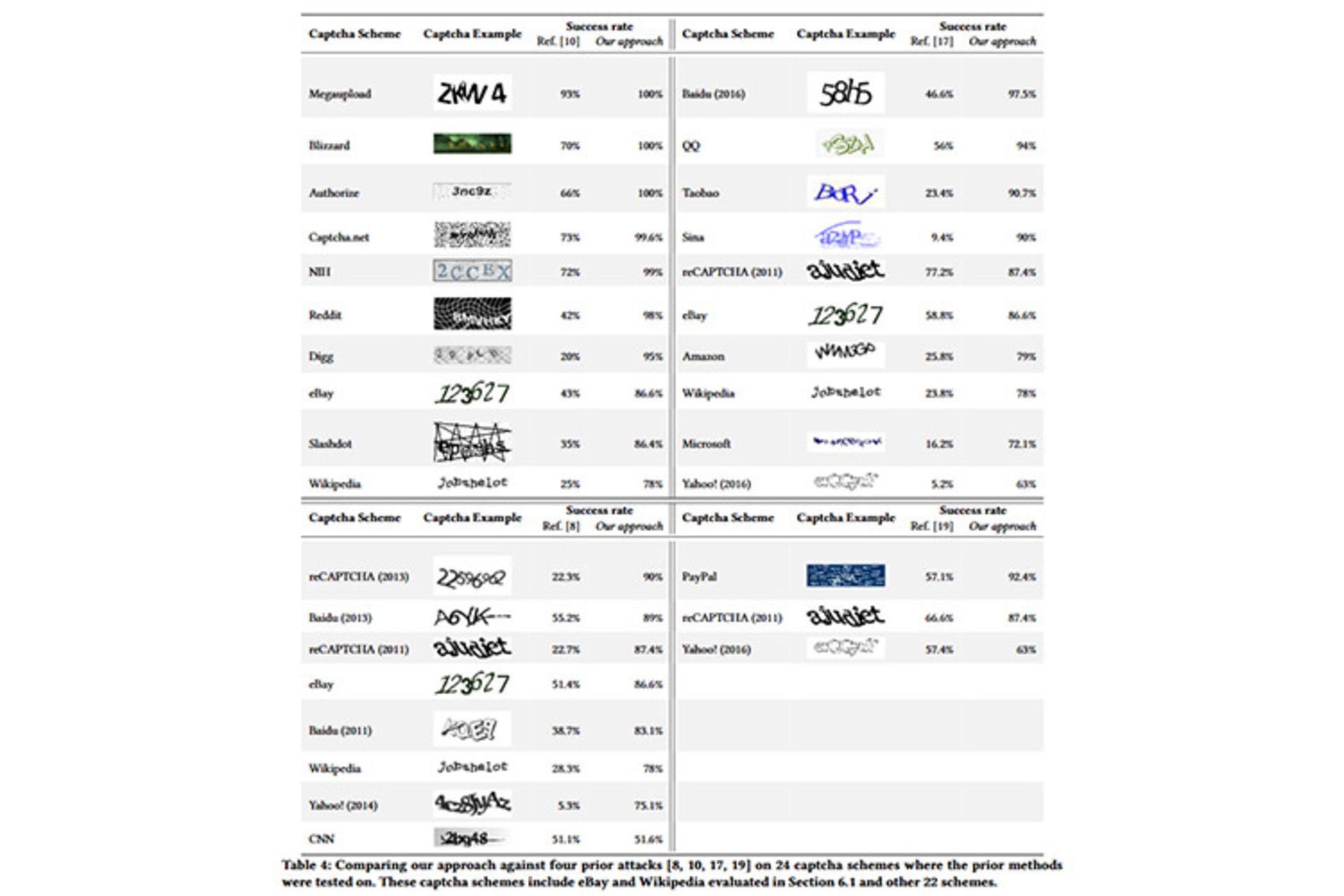
محققان اعلام کردند که روش پیشنهادی آنها میتواند با دقت ۱۰۰ درصد، کدمتنی کپچا را در سایتهایی مانند Megaupload، Blizzard و .NET حدس بزند. باتوجه به آزمایشهای انجامشده روی ۳۰ سایت دیگر، مشخص شد که روش محققان از دقت بالاتری نسبت به تمام روشهای قبلی برخوردار است. در این بررسی، سایتهایی همچون آمازون، Digg، Slashdot، PayPal، یاهو و QQ مورد بررسی قرار گرفتند. محققان اعلام کردند که الگوریتم جدید آنها علاوهبر اینکه از دقت بالاتری نسبت به روشهای قبلی برخوردار است، کارایی بهتر و قیمت پایینتری هم دارد. محققان اعلام کردند:
الگوریتم جدید میتواند با استفاده از یک کامپیوتر دسکتاپ، کد متنی کپچا را در کمتر از ۰.۰۵ ثانیه حدس بزند.

این بدان معنی است که مهاجمان نیازی به خرید و پرداخت هزینه برای سرورهای رایانهای گرانقیمت ندارند تا بتوانند کدهای متنی CAPTCHA را بلادرنگ در وبسایتهای مورد نظرشان حدس بزنند. وقتی مهاجمی، الگوریتم کد متنی کپچا را آموزش داده است، میتواند از این الگوریتم روی دسکتاپ یا وب سرور معمولی استفاده کند و حملات DDoS یا حملات اسپم را روی وبسایتهایی که از سرویس کد متنی کپچا استفاده میکنند، بهانجام برساند. از آنجایی که آموزش دادن الگوریتم بسیار ساده است، چنین افرادی میتونند بهراحتی الگوریتم را آموزش بدهند. دکتر ژنگ وانگ، مدرس ارشد دانشکده محاسبات و ارتباطات دانشگاه لنکستر و همکارانش در این تحقیق اعلام کردند:
چنین وضعیتی واقعا ترسناک است. این بدان معنی است که اولین سد دفاع امنیتی بسیاری از وبسایتها دیگر قابل اعتماد نیست.
دکتر ژنگ و تیم تحقیقاتی او توصیه میکنند که صاحبان وبسایتها اقدامات دیگری را برای تشخیص روباتها و ایجاد چندین لایهی امنیتی مورد توجه قرار بدهند؛ مثلا میتوانند از روشهایی نظیر استفاده از الگوها، موقعیت مکانی یا دادههای بیومتریک استفاده کنند. در اوایل سال جاری میلادی، گوگل چنین سرویسی را تحت عنوان نسخهی ۳ ابزار کپچا معرفی کرد. گوگل اعلام کرد که نسخهی جدید سرویس کپچا با الگوریتمهای مبتنی بر یادگیری ماشین کار میکند تا بتواند روباتها را از کاربران واقعی تشخیص بدهد.