
هوش مصنوعی PaLM 2 دربرابر GPT-4؛ وقتی گوگل در زمین خودی در جا میزند!
رابطهی گوگل و هوش مصنوعی داستان عجیبی است؛ از آن مدل داستانها که دقیقاً نمیدانی قهرمان قرار بوده از این شخصیتهای بهاصطلاح آندرداگی باشد که باید بهدلیل ضعیفبودنش دربرابر رقبا دل بسوزانی و پیروزی نهاییاش را جشن بگیری یا از این شخصیتهای باابهت دارای قدرتهای ماورائی است که احتمالاً در پایان معلوم میشود که آدمبدهی داستان بوده است!
تاریخچهی تولد هوش مصنوعی به سال ۱۹۵۰، یعنی ۷۳ سال پیش و انتشار مقالهی بسیار معروف آلن تورینگ برمیگردد که با سؤال جنجالی «آیا ماشینها میتوانند فکر کنند؟» شروع میشد؛ اما این روزها اکثر افراد هوش مصنوعی را بیشتر بهلطف چتبات ChatGPT و مولدهای تصویر Dall-E و Midjourney میشناسند.
شرکت مرموز OpenAI که قصد دارد زودتر از هر شرکت دیگری به هوش مصنوعی انسانگونهی شبیه فیلمهای علمیتخیلی برسد، با عرضهی عمومی چتجیپیتی به شهرت جهانی رسید. سپس، مایکروسافت این شرکت را ازآنِ خود کرد و با آوردن مدل زبانی بهکاررفته در ChatGPT به بینگ، جان تازهای به موتور جستوجوی بختبرگشتهی خود بخشید. حالا هم که میخواهد با «کوپایلت»، هوش مصنوعی را به ویندوز بیاورد.
گوگل خیلی دیر به این بازی پیوست. شرکتی که خودش در ایجاد شبکهای که مدلهای زبانی بزرگ نظیر GPT برپایهی آن توسعه یافتهاند، نقش مهمی ایفا و بیشتر از هر شرکت دیگری در حوزهی هوش مصنوعی سرمایهگذاری کرده بود (نزدیک ۴ میلیارد دلار)، حالا چنان از رقیبانش عقب مانده بود که حتی عرضهی چتبات بارد (Bard)، آنهم با جنجالهای خطای علمی و سرقت ادبی، نتوانست اهالی مانتینویو را به گرد پای رقیب ردمونیشان برساند.
گوگل بیش از هر شرکتی در هوش مصنوعی سرمایهگذاری کرده است
تا اینکه چند وقت پیش، کنفرانس Google I/O از راه رسید و فرصتی شد تا گوگل تمام برگهای هوش مصنوعی خودش را یک جا رو کند. گل سرسبد این رونماییها، مدل زبانی PaLM 2 بود که در شماری از سرویسهای گوگل، ازجمله جیمیل و گوگل داکس استفاده میشود؛ هرچند بهنظر نمیآید چتبات بارد هنوز به این نسخه ارتقا یافته باشد.
مدل زبانی PaLM (مخفف Pathways Language Model) سال ۲۰۲۲ معرفی شد؛ اما گوگل آن را در هیچ محصولی بهکار نبرد. پالم ۵۴۰ میلیارد پارامتر داشت و GPT-3 که سال ۲۰۲۰ در فاز بتا عرضه شد و نسخهی کمی بهبودیافته از آن در ChatGPT بهکار رفته بود؛ فقط ۱۷۵ میلیارد پارامتر.
در حوزهی مدلهای زبانی بزرگ، پارامتر به قدری اشاره میکند که مدل میتواند بهصورت مستقل و با دریافت آموزش بیشتر آن را تغییر دهد و تا همین چند وقت پیش، اساس بر این بود که هرچه تعداد پارامترها بیشتر باشد، قدرت و سرعت عمل مدل در تولید پاسخ بیشتر است.
بااینحال، وقتی ChatGPT مبتنیبر GPT-3.5 و بارد مبتنیبر PaLM را روبهروی هم قرار دادم، چتبات OpenAI در بسیاری از تستها عملکرد بهتری از خود نشان داد. حالا هر دو شرکت از اعلام تعداد پارامترهای GPT-4 و PaLM 2 سر باز میزنند؛ اما از بهبودهای چشمگیر درمقایسهبا مدلهای قبلی صحبت میکنند.
گوگل میگوید PaLM 2 براساس دادههای چندزبانهی متشکل از بیش از ۱۰۰ زبان آموزش دیده است و میتواند معنی اصطلاحات و اشعار و معماهای زبانی را در زبانهای مختلف ازجمله فارسی متوجه شود.
برای مثال، میتواند معنی ضربالمثل «نابرده رنج گنج مسیر نمیشود» را به همان زبان فارسی توضیح دهد (بینگچت مبتنیبر GPT-4 هم میتواند همین کار را انجام دهد). این در حالی است که PaLM اولیه فقط با دادههای انگلیسی آموزش داده شده بود و اگر همینحالا به بارد سر بزنید، میبینید که از درک زبان فارسی ناتوان است.

گوگل همچنین میگوید توانایی استدلال منطقی PaLM 2 بیشازپیش شده و چون با بیش از ۲۰ زبان برنامهنویسی آموزش دیده است، مهارت کدنویسیاش بهطرز چشمگیری بهبود یافته است. ازلحاظ قدرت پردازشی هم بهینهتر شده و مثلاً کوچکترین نسخهی این مدل به نام Gecko آنقدر سبک است که میتواند حتی در حالت آفلاین روی گوشیهای هوشمند اجرا شود.
بهگفتهی گوگل، PaLM 2 قویتر از GPT-4 نیست
تمام این ادعاها در گزارش فنی ۹۲ صفحهای PaLM 2 آمده است؛ گزارشی که قدرت بهترین مدل زبانی گوگل را در حوزههای ترجمه، کدنویسی، استدلال، خلاقیت و پاسخ به پرسشهای مختلف بهرخ میکشد. در اینکه PaLM 2 در تمام حوزهها از نسخهی قبلی خود بهتر است، شکی نیست؛ اما آیا این مدل توانسته است GPT-4 را هم کنار بزند؟
راستش را بخواهید، نه آنطورکه گوگل دوست دارد باور کنیم و نه آنطورکه از شرکتی در حدواندازهی گوگل انتظار داریم.
اگر فرصت داشتید، نگاهی به گزارش گوگل بیندازید. با نگاهی گذرا به جدول نتایج، اینطور بهنظر میرسد که PaLM 2 توانسته است در برخی تستها، عملکرد بهتری از رقیب اصلی خود، GPT-4، نشان دهد؛ اما چقدر میتوان به این نگاه گذرا اطمینان کرد؟
PaLM 2 دربرابر GPT-4؛ رقابت در کدنویسی
بیایید عملکرد این دو چتبات را در بخش کدنویسی بررسی کنیم. برای مثال، در تست HumanEval که مربوط به تست کد پایتون است، میبینیم مدل PaLM 2-S که حتی مدل پایه هم نیست و با پلاگینهای مخصوص کدنویسی بهبود یافته، امتیازهای ۳۷٫۶ و ۸۸٫۴ را بهدست آورده است.
بالای امتیاز ۳۷٫۶، عبارت pass@1 را میبینیم. این یعنی اولین پاسخ مدل به سؤال درست بوده است؛ اما برای امتیاز ۸۸٫۴ که درادامه خواهیم دید از امتیاز GPT-4 در این آزمون بهمراتب بیشتر است، عبارت pass@100 نوشته شده است. این یعنی از بین ۱۰۰ پاسخی که مدل به سؤال داده، یکی از آنها درست بوده است.

وقتی امتیاز ۸۸٫۴ مدل زبانی گوگل را دربرابر امتیاز ۶۷ مدل زبانی GPT-4 قرار میدهیم، بهنظر میرسد PaLM 2 مدل بهتری برای کدنویسی است؛ اما امتیازی که واقعاً باید در این مقایسه در نظر گرفته شود، ۳۷٫۶ است؛ یعنی تنها زمانیکه مدل در اولین تلاش به پاسخ درست میرسد. البته بازهم یادآوری میکنم که این امتیاز برای PaLM 2-S است که با توکنهای مربوط به کدنویسی بازطراحی شده است.
حالا بیایید نگاهی به امتیاز کدنویسی به زبان پایتون این مدلها در وبسایت paperswithcode بیندازیم که درواقع بنچمارکی از امتیاز عملکرد مدلهای زبانی مختلف است.
همانطورکه میبینید، جایگاه نخست با بیشترین امتیاز به مدل زبانی Reflextion تعلق دارد که مبتنیبر GPT-4 است؛ اما با دادهها و قابلیتهای بیشتری آموزش دیده است. حتی Parsel که در جایگاه دوم قرار دارد، مبتنیبر مدل زبانی GPT-4 و CodeT است که هر دو را OpenAI توسعه داده است. خودِ مدل GPT-4 هم با امتیاز ۶۷ در جایگاه سوم قرار گرفته است. نکتهی عجیب اینکه جایگاه GPT-3.5 که در چتجیپیتی بهکار رفته، هم از PaLM-2 (نسخهی آموزشدیده با توکنهای کدنویسی) بالاتر است.
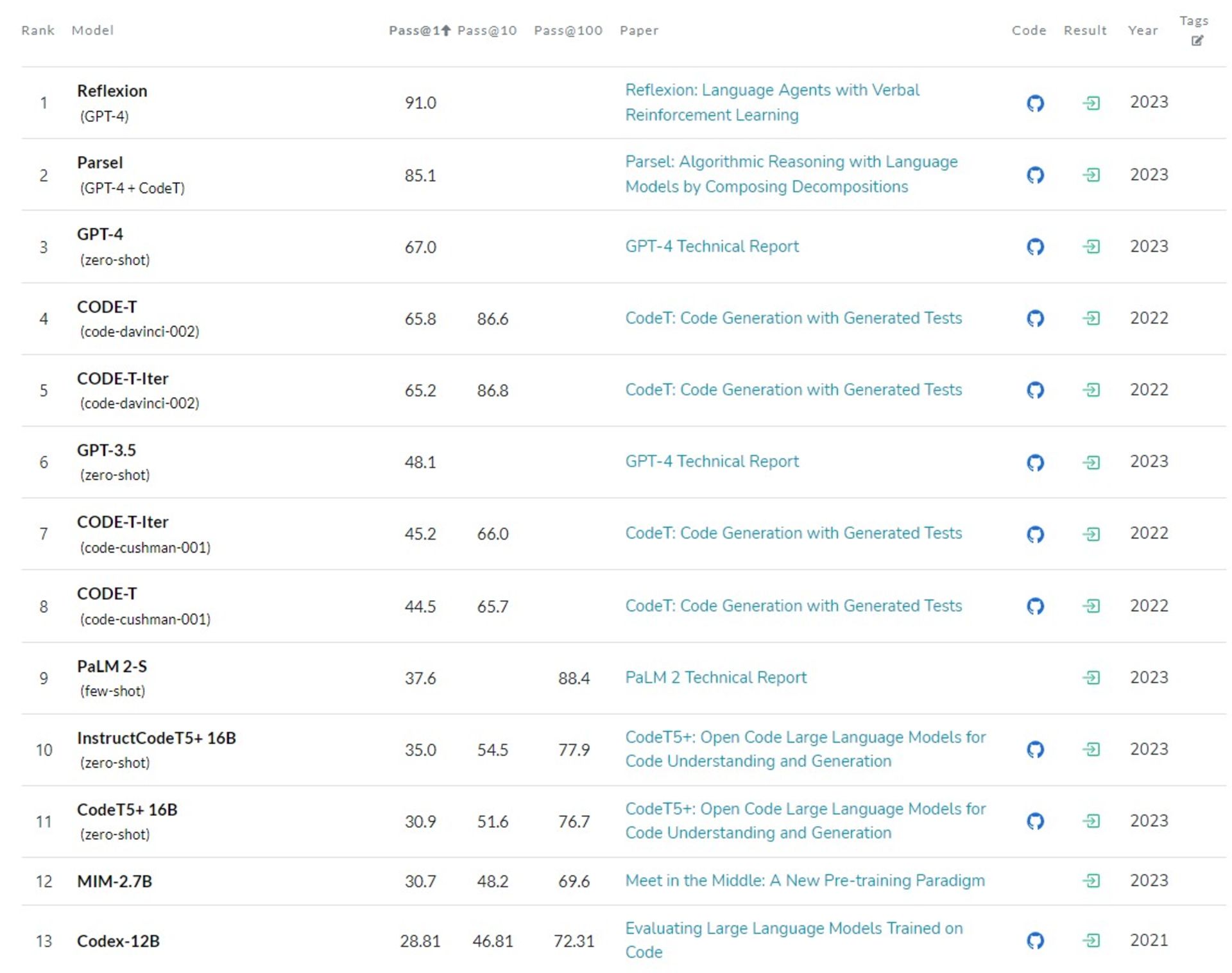
شاید برایتان سؤال شده است که چرا رتبهی PaLM 2-S با امتیاز ۸۸٫۴ از GPT-4 با امتیاز ۶۷ کمتر است. نکته اینجا است که امتیاز GPT-4 در شرایط «pass@1» و «zero-shot» بهدست آمده است؛ یعنی در شرایطی که هیچ نمونه و مثالی به مدل نشان داده نشده و باید خودش بدون هیچ کمکی به جواب درست میرسیده است. این در حالی است که امتیاز PaLM 2-S در شرایط «pass@1» و «few-shot» (مدل با چند نمونه برای رسیدن به جواب آشنا شده)، ۳۷٫۶ است و فقط در حالت «pass@100» توانسته است به امتیاز ۸۸٫۴ برسد.
جالب است مدل CODE-T شرکت OpenAI که در سال ۲۰۲۲ توسعه یافته، در شرایط «pass@10»، یعنی تنها با ۱۰ بار تلاش، توانسته است امتیازی را بهدست آورد که PaLM 2-S با ۱۰۰ بار تلاش به آن رسیده است.
PaLM 2 دربرابر GPT-4؛ قابلیت پرسش زنجیره فکر
بیایید سراغ مقایسهی دیگری برویم؛ چیزی که احتمالاً گوگل دوست دارد بیشتر روی آن تمرکز کنیم. در این مقایسه، گوگل نشان میدهد که PaLM 2 در سه تست MATH (مسائل ریاضی چالشی المپیادی)، GSM8K (مسائل ریاضی دبستانی به انگلیسی) و MGSM (مسائل ریاضی دبستانی به زبانهای مختلف) پیشرفت چشمگیری درمقایسهبا نسخهی اولیه کرده و حتی در یکیدو مورد امتیاز بیشتری از GPT-4 بهدست آورده است؛ هرچند از قراردادن امتیاز MGSM رقیب، خودداری کرده است.
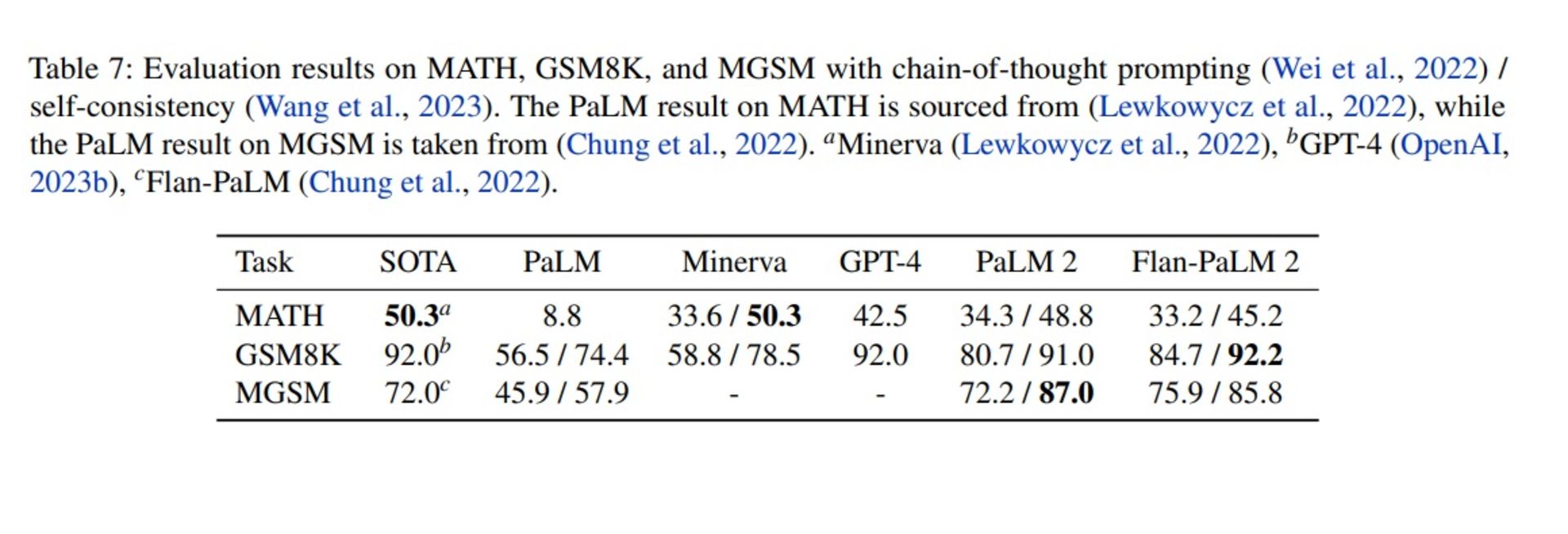
این جدول دقیقاً مقایسهی یکبهیک را ارائه نمیدهد. در این گزارش، میخوانیم که گوگل برای بهبود عملکرد PaLM 2 از دو قابلیت خاص استفاده کرده است: یکی پرسش زنجیرهی فکر (chain-of-thought prompting) و دیگری خودسازگاری (self-consistency).
خودسازگاری یعنی مدل چندین پاسخ مختلف تولید میکند و بعد میبیند کدام پاسخ بیشتر تکرار شده است تا آن را بهعنوان پاسخ درست انتخاب کند. برای مثال، اگر پاسخ اول بگوید A و پاسخ دوم بگوید B و پاسخ سوم بگوید A، مدل میگوید A فراوانی بیشتری داشته است؛ پس همین را بهعنوان پاسخ درست انتخاب میکنم.
زنجیرهی فکر هم از مدل میخواهد به پاسخهایش قدمبهقدم فکر کند. در بسیاری از پژوهشهای اخیر، تأثیر استفاده از زنجیرهی فکر بر بهبود عملکرد مدلهای زبانی نشان داده شده است. برای مثال، وبسایت Khan Academy که از هوش مصنوعی OpenAI استفاده میکند، برای پاسخ بهتر به سؤالات ریاضی کاربران از همین فرایند زنجیرهی فکر بهره میبرد. به این صورت که حتی قبل از اینکه مربیان هوش مصنوعی این پلتفرم سؤالی از کاربر بکنند، تمام مراحل رسیدن به جواب را یک بار برای خود تولید کردهاند تا وقتی کاربر جواب میدهد، بتوانند با استفاده از «حافظه»ی خود او را مرحلهبهمرحله به رسیدن به جواب درست همراهی کنند.
جدول مقایسهی امتیازهای گزارش گوگل دقیقاً یکبهیک نیست
با این توضیح، برویم سراغ بررسی امتیازها. گوگل میگوید با استفاده از پرسش زنجیرهی فکر توانسته است عملکرد PaLM 2 را درمقایسهبا PaLM در تمام تستها افزایش دهد. این موضوع بهویژه دربارهی امتیاز تست MATH جالب است که افزایش بیش از ۴ برابری عملکرد را در مدل مجهز به پرسش زنجیرهی فکر و افزایش بیش از ۶ برابری را در مدل مجهز به قابلیت خودسازگاری نشان میدهد.
باوجوداین، گوگل در حالی امتیاز PaLM 2 را با رقیب خود مقایسه کرده است که براساس گزراش GPT-4، شرکت OpenAI تنها در تست GSM-8K از قابلیت پرسش زنجیرهی فکر استفاده کرده است و به امتیاز ۹۲٫۲ رسیده که همچنان از PaLM 2 بیشتر است. مقایسهی این امتیاز با مدل Flan-PaLM 2 هم مقایسهی درستی نیست؛ چون این مدل با دادههای تخصصی مربوط به تست آموزش دیده است. بگذریم که گوگل از قراردادن امتیاز تست MGSM برای GPT-4 بهدلایلی خودداری کرده است.
چرا گوگل از برنامههایش برای افزایش امنیت هوش مصنوعی حرفی نمیزند؟
نکتهی جالب دیگر دربارهی گزارش فنی گوگل، صحبتنکردن دربارهی دغدغههای این روزهای مردم و صنایع مختلف دربارهی هوش مصنوعی است؛ دغدغههایی مثل جایگزینشدن انسانها با هوش مصنوعی در محیط کار، استفاده از هوش مصنوعی در جنگافزارها، مسائل مربوط به کپیرایت و کلاً امنیت استفاده از هوش مصنوعی برای نسل بشر.
بخش زیادی از گزارش گوگل به «هوش مصنوعی مسئولانه» (Responsible AI) اختصاص دارد؛ اما محوریت صحبتهای این غول دنیای فناوری استفاده از ضمایر درست در ترجمه است. این موضوع بهویژه از این جهت نظر مرا به خود جلب کرد که چند وقت پیش، جفری هینتون، پدرخواندهی هوش مصنوعی، پس از ۱۰ سال گوگل را ترک کرد تا از خطرهای هوش مصنوعی برای شغلها و حتی خود انسانها بگوید.
این در حالی است که OpenAI زمانیکه دارد در گزارش GPT-4 دربارهی امنیت مدل زبانیاش میگوید، نمونههایی را نشان میدهد که در آن چتبات به درخواستهای غیرقانونی یا خطرناک مثل ساخت بمب پاسخ نمیدهد.
شرکت OpenAI در پایان گزارش خود میگوید که با پژوهشگران مستقل در حال همکاری است تا تأثیرات احتمالی هوش مصنوعی را بهتر درک و ارزیابی کند و بتواند برای قابلیتهای خطرناکی برنامهریزی کند که ممکن است در سیستمهای آینده بروز کنند. سؤالی که مطرح میشود، این است که گوگل برای امنیت هوش مصنوعی چه برنامههایی دارد؟ چرا فعلاً ترجیح داده است مشکلات هوش مصنوعی را به مسائل مربوط به ترجمه محدود کند؟
آیا گوگل در حوزهی هوش مصنوعی به پای رقیبان خواهد رسید؟
آنچه در این میان عجیب بهنظر میرسد، این است که چطور گوگل با آن همه منابع و میلیاردها دلاری که پای تحقیقوتوسعهی هوش مصنوعی صرف کرده و اینکه حتی زودتر از رقبا به این حوزه وارد شده، همچنان از شرکت بهمراتب کوچکتری چون OpenAI عقب است؟
بدون شبکهی عصبی ترنسفورمر گوگل الان از ChatGPT خبری نبود
این گوگل بود که در سال ۲۰۱۷ با انتشار مقالهی «Attention Is All You Need» (توجه تنها چیزی است که به آن نیاز دارید)، شبکهی عصبی ترنسفورمر را معرفی کرد؛ شبکهای که اصلاً ظهور مدلهای زبانی بزرگ را ممکن کرد و بدون آن ساخت چتبات ChatGPT ممکن نبود.
جالب است بدانید از ۸ نویسندهی این مقاله، فقط یک نفر همچنان در گوگل باقی مانده است و بقیه سراغ راهاندازی استارتاپهای هوش مصنوعی خود رفتهاند؛ ازجمله Adept AI Lab و Air Street Capital و البته OpenAI. حتی شایعه شده است که برخی از پژوهشگران هوش مصنوعی گوگل در حال ترک این شرکت هستند؛ چون گوگل متهم شده است که چتبات بارد را بدون اجازه با دادههای ChatGPT آموزش داده است.
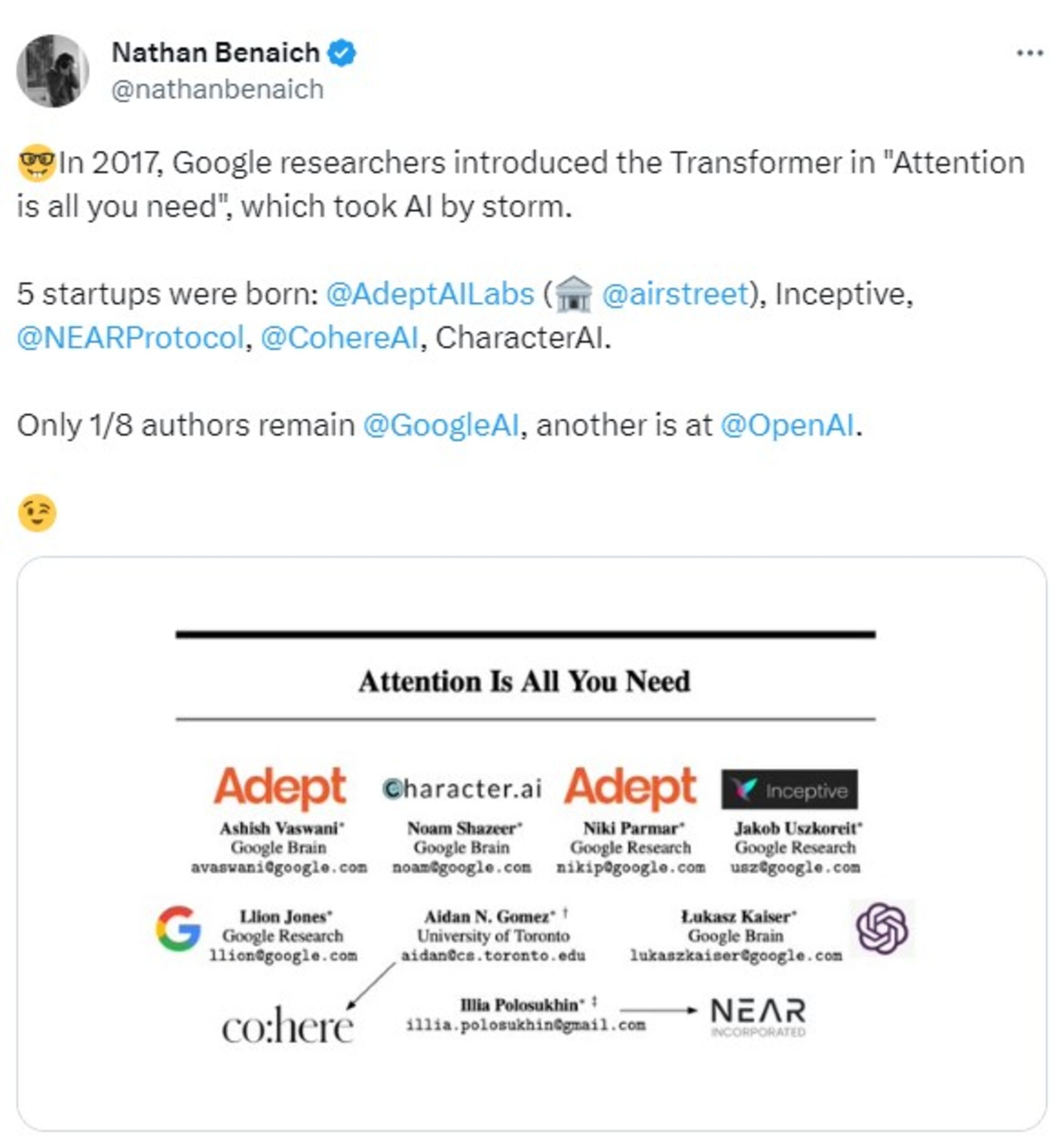
البته حالا گوگل پنهانکارتر شده است و مقالات زیادی دربارهی نوآوریهایش در حوزهی هوش مصنوعی منتشر نمیکند. شاید از انتشار مقالهی Attention Is All You Need پشیمان است و از کجا معلوم، شاید همینحالا در حال توسعهی مدلهای قدرتمندتری است که تا پیش از عرضه، چیزی از آنها نخواهیم فهمید. شاید رؤیای رسیدن به هوش مصنوعی انسانگونه نه در OpenAI و مایکروسافت، بلکه در آزمایشگاههای گوگل بهحقیقت بپیوندد.
بااینحال، تا آن روز و اگر واقعاً داستان اینچنین باشد، چیزی که مشخص است، آن است که PaLM-2 با اینکه مدل زبانی بسیار قدرتمندی است و عملکردش از نسخهی اول بهمراتب قویتر شده، هنوز در بسیاری از تستها از GPT-4 جا میماند.
رویکرد بهشدت محافظهکارانهی گوگل دربرابر استفاده از سیستمهای هوش مصنوعی در سرویسهایش نیز کمکی به جبران این عقبماندگی نمیکند. برای مثال، یکی از مشکلات مهم بارد پشتیبانینکردن از زبانهای دیگر بود؛ ولی حالا که PaLM 2 از ۱۰۰ زبان ازجمله فارسی پشتیبانی میکند، چرا هنوز نمیتوان با این چتبات به زبان فارسی حرف زد؟
بهقول زوبین قهرمانی، معاون پژوهشی گوگل، PalM 2 به پیشرفت چشمگیری درمقایسهبا مدلهای قبلی گوگل دست پیدا کرده است؛ اما هنوز برای حل معضلات هوش مصنوعی «راه درازی در پیش دارد».