مارک زاکربرگ شیپور رقابت با هوش مصنوعی ChatGPT را به صدا درآورد

متا لحظاتی پیش ضمن وارد کردن دستیار هوش مصنوعی Meta AI به بخش جستوجوی اینستاگرام، واتساپ، فیسبوک و مسنجر، از مدلهای زبانی بزرگ خانوادهی Llama 3 پردهبرداری کرد.
دو نسخهی کوچک از Llama 3 هماکنون در قالب دستیار Meta AI و پلتفرم مخصوص توسعهدهندگان دردسترس هستند و نسخهی اصلی که مدلی چند حالته محسوب میشود، در ماههای آینده از راه میرسد.
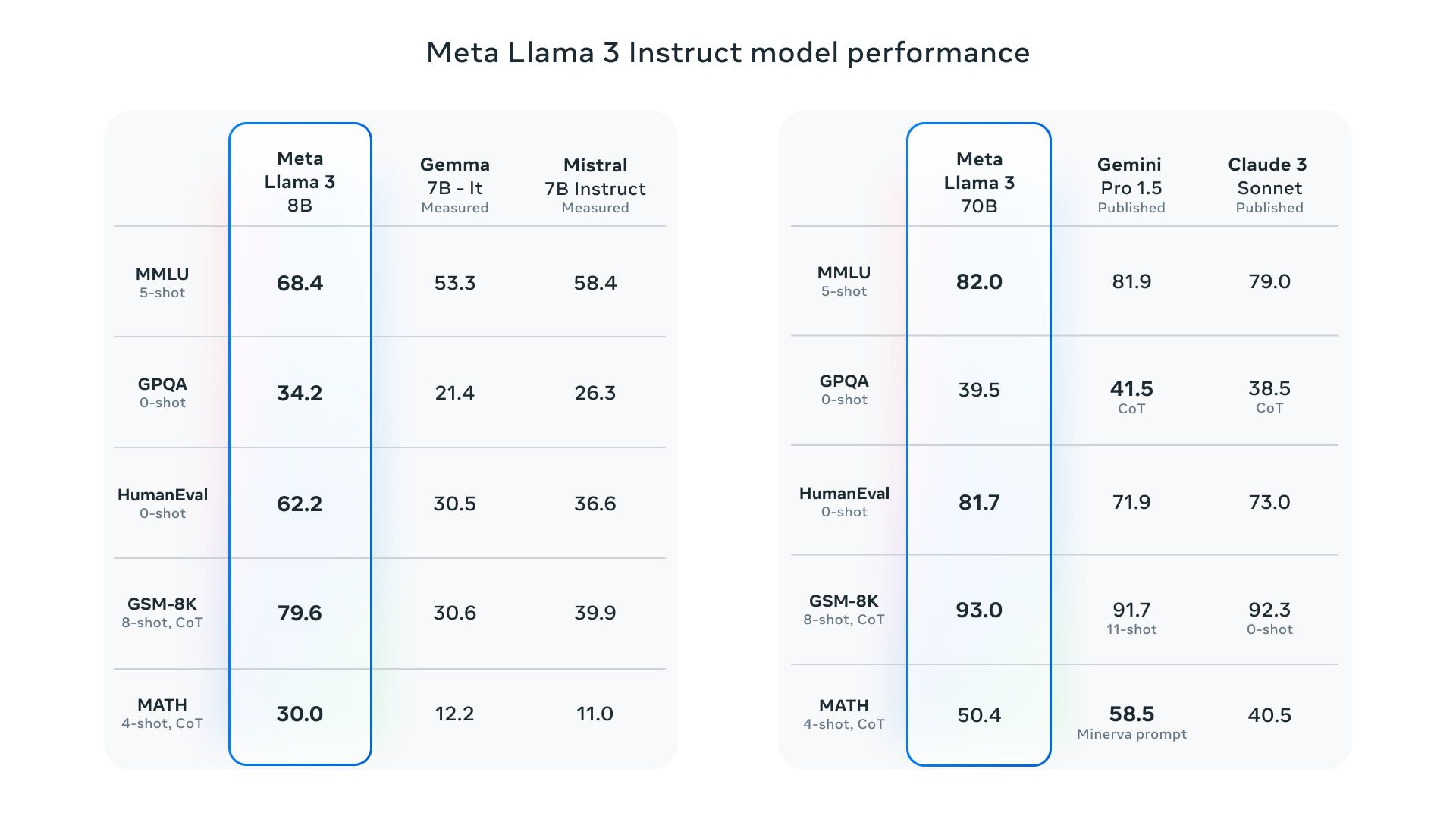
بر اساس بیانیهی مطبوعاتی متا، Llama 3 توانمندترین مدل زبانی متنباز در دنیا است. دو مدل کوچکتر Llama 3 که هماکنون بهصورت رایگان قابل دسترس هستند، شامل مدلی هشت میلیارد پارامتری و مدلی ۷۰ میلیارد پارامتری است.
بزرگترین نسخهی مدل زبانی Llama 2 که سال گذشته منتشر شد، ۷۰ میلیارد پارامتر داشت؛ با اینحال بزرگترین نسخهی Llama 3 بیشاز ۴۰۰ میلیارد پارامتر دارد. این به وضوح نشان میدهد که سرعت پیشرفت هوش مصنوعی چقدر زیاد است.
Llama 3 توانمندترین مدل زبانی متنباز در دنیا است
بر اساس گفتهی مارک زاکربرگ، مدل زبانی Llama 2 بر پایهی دو تریلیون توکن تعلیم داده شد، با اینحال برای توسعهی بزرگترین مدل Llama 3 از بیشاز ۱۵ تریلیون توکن استفاده شده است. فعلاً نمیدانیم که بزرگترین رقیب Llama 3 یعنی GPT-4 از چه تعداد توکن بهره میگیرد.
متا میگوید یکی از اهداف اصلیاش در توسعهی Llama 3، کاهش تعداد دفعاتی است که این هوش مصنوعی توانایی پاسخدادن به سؤالها را ندارد. متا فعلاً نگفته است که نسخهی ۴۰۰ میلیارد پارامتری Llama 3 را هم متنباز میکند یا نه؛ چون این هوش مصنوعی همچنان در حال تعلیمدیدن است.
نسخهی اصلی Llama 3 مدلی چند حالته است، به این معنی که افزونبر ورودی متنی، از ورودی تصویری هم پشتیبانی میکند. به احتمال زیاد Llama 3 در نهایت توانایی تولید ویدیو را نیز خواهد داشت، درست مثل هوش مصنوعی جنجالی Sora.
متا ترجیح داده است که دربارهی دادههای مورد استفاده برای تعلیم هوش مصنوعی Llama 3 چیزی نگوید. دیتاست مورد استفاده برای تعلیم این هوش مصنوعی، هفت برابر بزرگتر از Llama 2 است و چهار برابر کد بیشتر در آن استفاده شده.
زاکربرگ صراحتاً میگوید برای تعلیم Llama 3 از دادههای شخصی کاربران متا استفاده نشده است. او تأیید کرد که بخشی از دادههای مورد استفاده برای تعلیم Llama 3 توسط هوش مصنوعی ساخته شدهاند.