متا: هوش مصنوعی Llama 3 حتی از گوگل جمنای هم بهتر است

متا در بیانیهای مطبوعاتی اعلام کرد مدل زبانی بزرگ Llama 3 که بهزودی ازطریق ارائهدهندگان سرویسهای ابری مانند AWS منتشر میشود، عملکرد بهتری نسبت به اکثر مدلهای فعلی هوش مصنوعی دارد.
Llama 3 درحالحاضر دارای دو نسخه با هشت میلیارد پارامتر و ۷۰ میلیارد پارامتر است که فعلاً فقط پاسخهای مبتنیبر متن ارائه میدهند. Llama 3 تنوع بیشتری در پاسخ به درخواستها نسبتبه مدلهای زبانی بزرگ رقیب نشان میدهد.
Llama 3 در مواردی که از پاسخ دادن به سؤالات خودداری میکند، امتناع کاذب کمتری دارد و میتواند بهتر استدلال کند. متا میگوید Llama 3 دستورالعملهای بیشتری را میفهمد و کدهای بهتری را نسبت به قبل مینویسد.
متا ادعا میکند که دو نسخهی اولیهی Llama 3 در بنچمارکهای معین نسبتبه مدلهای هماندازه مانند جما و جمنای و میسترال و Claude 3 برتری دارد. در معیار MMLU که معمولاً دانش عمومی را اندازهگیری میکند، نسخهی هشت میلیارد پارامتری Llama 3 به طور قابل توجهی بهتر از نسخهی هفت میلیارد پارمتری جما و میسترال عمل کرد. نسخهی ۷۰ میلیارد پارامتری Llama 3 رقابت تنگاتنگی با جمنای پرو ۱٫۵ داشت.
نکتهی جالب اینجاست که مدل زبانی بزرگ GPT-4 در مقایسههای متا به چشم نمیخورد. باید توجه داشت که بنچمارک مدلهای هوش مصنوعی اگرچه برای درک میزان قدرتمند بودن آنها مفید واقع میشود، اما ناقص است. دیتاستهای مورد استفاده برای سنجش مدلها بخشی از آموزش آنها هستند؛ به این معنی که یک مدل زبانی بزرگ از قبل پاسخ سؤالات را میداند.
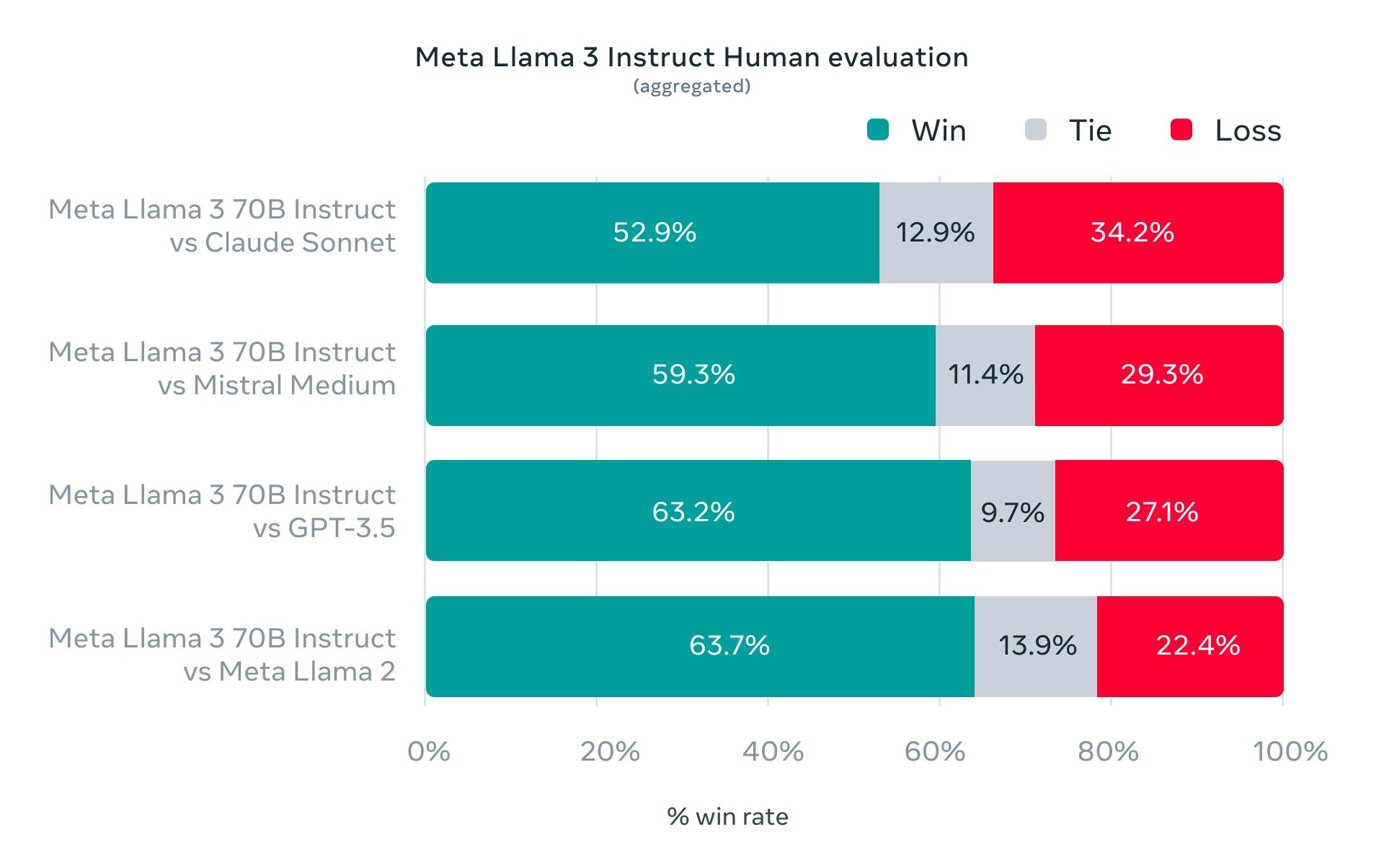
متا میگوید که ارزیابهای انسانی، Llama 3 را بالاتر از مدلهای دیگر از جمله GPT-3.5 رتبهبندی کردند. این شرکت دیتاستهای جدیدی را برای ارزیابهای انسانی ایجاد کرده تا سناریوهای دنیای واقعی را که ممکن است در آنها از Llama 3 استفاده شود، تقلید کند.
دیتاستهای یادشده شامل مواردی مانند درخواست مشاوره، خلاصهنویسی و نوشتن خلاقانه میشود. متا میگوید تیمی که روی این مدل کار میکردند به دادههای ارزیابی جدید دسترسی نداشتند و در نتیجه بر عملکرد مدل تأثیری نگذاشته است.
Llama 3 نسخهی ۴۰۰ میلیارد پارامتری هم خواهد داشت که میتواند رشتههای طولانیتری از دستورالعملها و دادهها را درک کند و مدلی چندحالته است که میتواند برای تولید تصویر یا رونویسی یک فایل صوتی بهکار رود.
نسخهی ۴۰۰ میلیارد پارامتری Llama 3 میتواند الگوهای پیچیدهتری را نسبتبه نسخههای کوچکتر یاد بگیرد و فعلاً درحال آموزش است.