چرا فریب دادن سیستمهای هوش مصنوعی مبتنی بر یادگیری عمیق بسیار آسان است

اتومبیل خودرانی به یک علامت توقف نزدیک میشود اما بهجای اینکه از سرعت خود کم کند، با سرعت زیاد وارد تقاطع شلوغ میشود. بعدا، گزارش تصادف نشان میدهد که چهار مستطیل کوچک روی علامت توقف چسبیده بود و موجب شد که سیستم هوش مصنوعی اتومبیل، کلمهی توقف را با علامت حداکثر سرعت مجاز ۴۵ کیلومتر اشتباه بگیرد. اگرچه چنین رویدادی درواقعیت اتفاق نیفتاده، اما پتانسیل خرابکاری هوش مصنوعی کاملا واقعی است.

پژوهشگران قبلا نشان دادهاند که وقتی برچسبهایی روی برخی از قسمتهای تابلوی توقف چسبانده شود، سیستم هوش مصنوعی بهراحتی فریب میخورد. آنها سیستمهای تشخیص چهره را نیز با چسباندن الگوهای چاپی روی عینک یا کلاه فریب دادند. آنها همچنین با واردکردن الگوهای صدای سفید موجب شدند که سیستم هوش مصنوعی تشخیص گفتار، عبارتهای خیالی بشنود. این موارد تنها چند مثال است که نشان میدهد شکستن تکنولوژی تشخیص الگو در هوش مصنوعی که با عنوان «شبکههای عصبی عمیق» شناخته میشوند، چقدر ساده است. این سیستمها در طبقهبندی صحیح انواع ورودیهای مختلف شامل تصاویر، گفتار و دادههای مربوط به اولویتهای خریداران بسیار موفق عمل کردهاند. آنها بخشی از زندگی روزمرهی ما هستند و هرچیزی، از سیستمهای تلفن خودکار گرفته تا توصیههای کاربران را روی سرویس سیال نتفلیکس اجرا میکنند. با این حال، ایجاد تغییر در ورودیها (به شکل تغییرات ناچیزی که معمولا برای انسان غیرمحسوس است) میتواند بهترین شبکههای عصبی موجود را هم گیج کند.
دن هندریکس، دانشجوی دکتری علوم کامپیوتر دانشگاه کالیفرنیا نیز مانند بسیاری از دانشمندان، شبکههای عصبی عمیق را اساسا شکننده تصور میکند: این شبکهها تا زمانیکه به قلمرو ناشناختهها وارد نشوند، عملکرد درخشانی دارند اما وقتی در شرایط غیرمنتظرهای قرار میگیرند، بهشدت شکننده هستند. این امر میتواند منجر به بروز مشکلات قابلتوجهی شود. سیستمهای یادگیری عمیق در حال خارج شدن از آزمایشگاه و وارد شدن به جهان واقعی هستند. این سیستمها در حوزههای مختلفی مانند هدایت اتومبیلهای خودران، نقشهیابی جرم و تشخیص بیماریها مورد استفاده قرار میگیرند اما نتایج مطالعهای که امسال منتشر شد، نشان میداد که افزودن چند پیکسل به اسکنهای پزشکی موجب میشود که این سیستمها در تشخیص سرطان اشتباه عمل کنند. برخی کارشناسان هم میگویند یک هکر میتواند از نقاط ضعف سیستم استفاده کرده و الگوریتمهای مهاجم خود را روی آن اجرا کند. پژوهشگران در تلاش برای پی بردن به اشتباهات ممکن، اطلاعات زیادی درمورد علت ناکامی شبکههای عصبی عمیق به دست آوردهاند. فرانسوا چولیت، مهندس هوش مصنوعی گوگل در مانتین ویو میگوید:
راهحلی برای ضعفهای اساسی شبکههای عصبی عمیق وجود ندارد.
او و برخی دیگر از کارشناسان معتقدند که برای برطرف کردن این نقایص لازم است قابلیتهای دیگری نیز به این شبکهها افزوده شود؛ برای مثال، سیستمهای هوش مصنوعی طراحی شود که خود بتوانند جهان را کشف کنند، کدهای خود را بنویسند و خاطرات را حفظ کنند. برخی از کارشناسان بر این باورند که این نوع سیستمها موضوع پژوهشهای هوش مصنوعی دههی آینده هستند.
بررسی واقعیت
در سال ۲۰۱۱، گوگل سیستمی را ارائه داد که میتوانست گربههای موجود در ویدئوهای یوتیوب را تشخیص دهد و بالافاصله پس از آن، موجی از سیستمهای طبقهبندی مبتنی بر شبکههای عصبی عمیق ارائه شد. جف کلون از دانشگاه وایومینگ میگوید:
همه میگفتند این سیستم چقدر شگفتانگیز است، کامپیوترها سرانجام میتوانند جهان را درک کنند.
اما پژوهشگران هوش مصنوعی میدانستند که شبکههای عصبی عمیق درواقع جهان را نمیفهمند. این ساختارهای نرمافزاری که تقلیدی ساده از معماری مغز هستند، از تعداد زیادی نورون دیجیتالی ساخته شدهاند که در لایههای زیادی مرتب شدهاند. هر نورون به نورونهای لایههای بالا و پایین خود وصل میشود. ایده این است که ویژگیهای ورودی خام که وارد لایههای زیرین میشود (مانند پیکسلهای یک تصویر) موجب برانگیختگی برخی از نورونها میشود و سپس این نورونها طبق قوانین سادهی ریاضی، سیگنالی را به نورونهای موجود در لایهی بالایی منتقل میکنند.
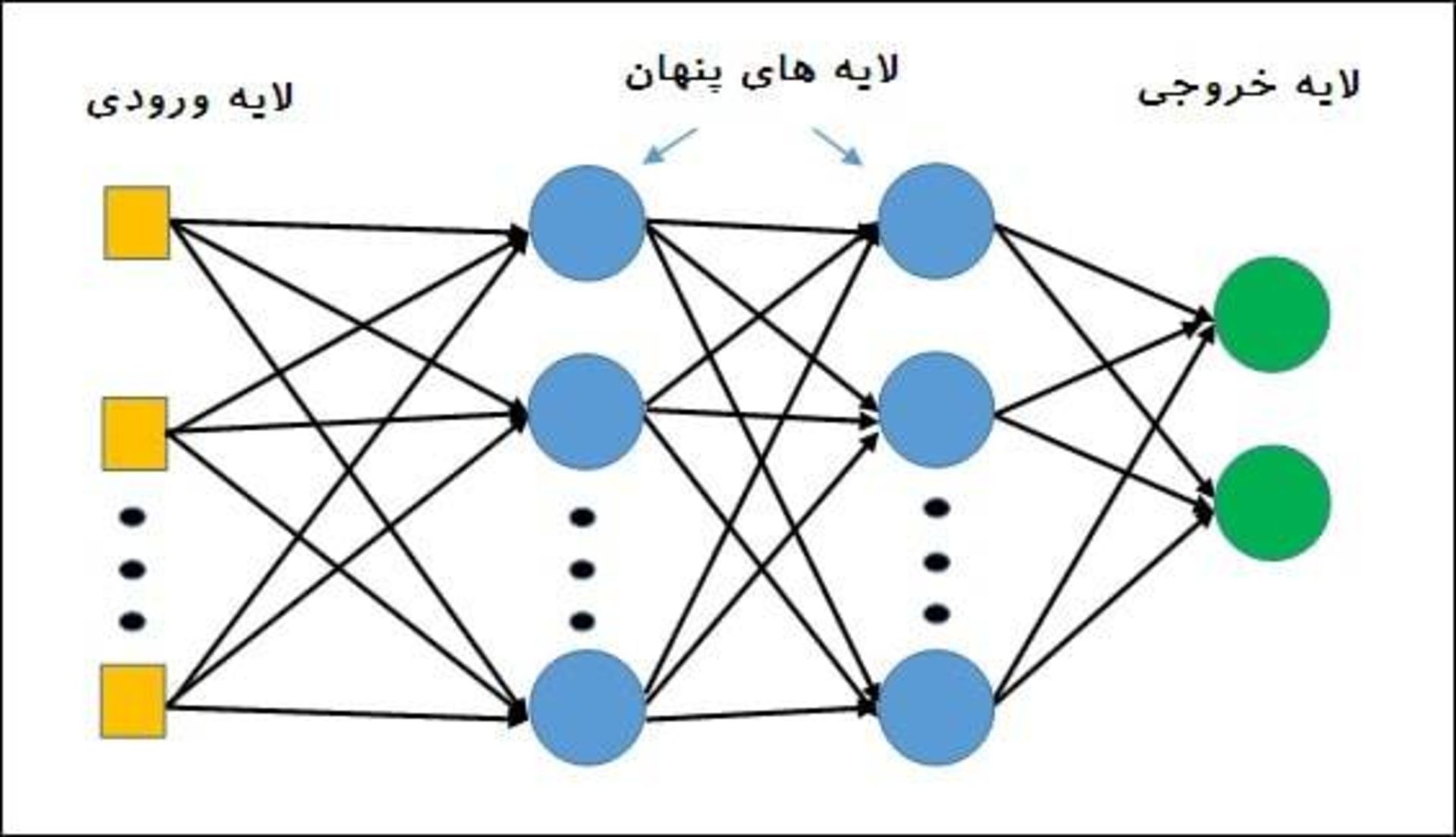
برای آموزش یک شبکهی شبکههای عصبی عمیق، آن را در معرض مجموعهی عظیمی از مثالهای مختلف قرار میدهند. طی فرایند آموزش، هر بار، روش اتصال نورونها به هم تغییر میکند تا درنهایت پاسخ مورد نظر در لایهی بالایی ایجاد شود، طوری که تصویر یک شیر همیشه بهعنوان یک شیر تفسیر شود؛ حتی اگر قبل از آن، این تصویر به سیستم ارائه نشده باشد.
اولین بررسی مهم در ارتباط با این مسئله در سال ۲۰۱۳ انجام شد، زمانیکه کریستین سزگدی و همکارانش گزارش مقدماتی را با عنوان «ویژگیهای عجیب شبکههای عصبی» منتشر کردند. این پژوهشگران نشان دادند که میتوان مثلا تصویری از یک شیر گرفت که سیستم هوش مصنوعی آن را بشناسد و سپس با تغییر چند پیکسل ماشین را متقاعد کرد که در حال دیدن چیز دیگری مانند یک کتابخانه است. پژوهشگران این تصاویر را «مثالهای خصمانه» نامیدند. یک سال بعد، کلون و آنه نیگوین بههمراه جیسون یوسینسکی در دانشگاه کرنل نشان دادند که میتوان کاری کرد که شبکههای عصبی عمیق چیزهایی را ببینند که در آنجا وجود ندارند (مانند پنگوئنی در الگویی از خطوط مواج). یوشوا بنگیو از دانشگاه مونترال، یکی از پیشگامان یادگیری عمیق است. او میگوید:
هرکسی که با یادگیری ماشین کار کرده باشد، میداند که این سیستمها گاهی اشتباهات احمقانهای میکنند... چیزی که عجیب بود، نوع اشتباه بود. این نوعی اشتباه است که تصور نمیکردیم، پیش آید.

حتی تصاویر طبیعی میتواند موجب فریب شبکههای عصبی عمیق شود زیرا ممکن است شبکه بهجای انتخاب ویژگیهای برجستهای که انسان قادر به تشخیص آن است، روی رنگ، بافت یا پسزمینهی تصویر تمرکز کند.
پژوهشگران انواع مختلفی از اشتباهاتی را که در این سیستمها پیش میآید، نشان دادهاند. سال گذشته، نیگوین نشان داد که برخی از بهترین سیستمهای طبقهبندی تصاویر، حتی با چرخش سادهی اشیاء دچار اشتباه میشوند. امسال، هندریکس و همکارانش گزارش کردند که حتی تصاویر طبیعی میتوانند موجب به اشتباه افتادن سیستمهای پیشرفتهی طبقهبندی شود. در مثالهای آنها، سیستم اشتباها یک قارچ را بهعنوان پرتزل (نوعی نان پختهشده به شکل گره) یا یک سنجاقک را بهعنوان یک دریچهی منهول شناسایی میکرد.
این نوع اشتباهات مختص تشخیص اشیاء نیست: هر سیستم هوش مصنوعی که برای طبقهبندی ورودیهایی مانند گفتار از شبکههای عصبی عمیق استفاده میکند، ممکن است فریب بخورد. سیستمهای هوش مصنوعی که بازی میکنند نیز میتوانند خرابکاری کنند: در سال ۲۰۱۷، سندی هوآنگ، دانشجوی دکتری دانشگاه کالیفرنیا به اتفاق همکارانش شبکههای عصبی عمیقی را که به روش یادگیری تقویتی آموزش دیده بودند تا بازیهای ویدئویی آتاری را ببرند، مورد بررسی قرار دادند. در این رویکرد، برای هوش مصنوعی یک هدف تعریف میشود و سیستم در پاسخ به طیف وسیعی از ورودیها و ازطریق آزمون و خطا یاد میگیرد که برای رسیدن به آن هدف باید چه کاری انجام دهد. این همان تکنولوژی پشتصحنهی قهرمانان برنامههایی مانند آلفازیرو و ربات پوکر پلوریبوس است. با این حال، گروه هوآنگ توانست با افزودن یکی دو پیکسل تصادفی به صحنه موجب شکست بازیهای هوش مصنوعی شود.
اوایل سال جاری، آدام گلیو، دانشجوی دکتری هوش مصنوعی در دانشگاه کالیفرنیا نشان داد که میتوان عاملی را به محیط هوش مصنوعی وارد کرد که برای ایجاد سردرگمی در پاسخهای هوش مصنوعی، سیاستهای خصمانهای را اجرا کند. برای مثال، یک فوتبالیست هوش مصنوعی که آموزش دیده است در محیط شبیهسازی شده توپ را از اطراف دروازهبان عبور دهد، وقتی که دروازهبان رفتار غیرمنتظرهای مانند افتادن روی زمین را از خود نشان میدهد، توانایی گلزنی خود را از دست میدهد.

یک فوتبالیست هوش مصنوعی در محیط شبیهسازیشده، هنگام زدن ضربات پنالتی، وقتی که دروازهبان رفتار پیشبینینشدهای مانند افتادن روی کف زمین را از خود نشان میدهد، گیج میشود
آگاهی از نقاط ضعف شبکههای عصبی عمیق موجب میشود هکر بتواند بر هوش مصنوعی تسلط پیدا کند. سال گذشته گروهی از پژوهشگران گوگل نشان دادند که استفاده از مثالهای خصمانه نهتنها موجب میشود که شبکههای عصبی عمیق اشتباه کنند، بلکه این کار میتواند حتی موجب برنامهریزی مجدد و تعیین اهداف دیگری برای سیستم شود.
بسیاری از شبکههای عصبی مانند سیستمهایی که درک زبان را یاد میگیرند، میتوانند برای رمزگذاری دیگر برنامههای کامپیوتری مورد استفاد قرار گیرند. کلون میگوید ازنظر تئوری، شما میتوانید یک چتبات را به هر برنامهای که میخواهید تبدیل کنید. او وضعیتی را در آیندهی نزدیک تصور میکند که در آن هکرها شبکههای عصبی را ربوده و الگوریتمهای اسپمبوت خود را اجرا میکنند. ازنظر داون سونگ، دانشمند کامپیوتر دانشگاه کالیفرنیا، شبکههای عصبی عمیق بسیار آسیبپذیر هستند. او میگوید روشهای بسیار مختلفی برای حمله به یک سیستم وجود دارد و دفاع دربرابر آنها بسیار دشوار است.

چرخاندن اشیاء موجود در یک تصویر موجب گیج شدن شبکهی عصبی عمیق میشود، احتمالا به این علت که این تصویرها از تصاویری که برای آموزش شبکه مورد استفاده قرار گرفته است، بسیار متفاوت هستند
شبکههای عصبی عمیق قدرتمندند زیرا داشتن لایههای زیاد به این معنا است که آنها در هنگام تلاش برای طبقهبندی یک ورودی میتوانند الگوها را براساس ویژگیهای بسیار مختلفی انتخاب کنند. یک سیستم هوش مصنوعی آموزشدیده برای شناسایی هواگرد ممکن است فکر کند، ویژگیهایی از قبیل لکههای رنگ، بافت یا پسزمینه درست به اندازهی خصوصیاتی مانند بالها، پیشبینیکنندههای قدرتمندی هستند. اما این امر همچنین بدین معنا است که تغییر بسیار کوچکی در ورودی میتواند باعث شود سیستم هوش مصنوعی آن شی را به شکل متفاوتی درک کند.
یک راهحل ممکن این است که دادههای بیشتری در اختیار هوش مصنوعی قرار داده شود، بهخصوص بهمنظور مواجههی مکرر هوش مصنوعی با موارد مشکلساز و تصحیح خطاهای آن. در این شکل از آموزش، همانطور که یک شبکه یاد میگیرد اشیاء را شناسایی کند، سیستم دوم سعی میکند ورودیهای شبکهی اول را بهگونهای تغییر دهد که موجب اشتباه شود. به این ترتیب، مثالهای خصمانه بخشی از دادههای آموزشی شبکههای عصبی عمیق میشوند.
هندریکس و همکارانش پیشنهاد کردهاند که باید قاطعیت شبکههای عصبی عمیق دربرابر ایجاد خطا، با آزمون چگونگی عملکرد آنها دربرابر طیف وسیعی از مثالهای خصمانه مورد آزمایش قرار گیرد. اگرچه بهعقیدهی این دانشمندان، آموزش شبکه برای ایجاد مقاومت دربرابر یک نوع حمله میتواند آن را در برابر دیگر حملات تضعیف کند.
پژوهشگرانی تحت هدایت پوشمیت کوهلی در دیپمایند گوگل درحال تلاش برای مقاوم کردن شبکههای عصبی عمیق دربرابر اشتباهات هستند. بسیاری از حملات خصمانه با ایجاد تغییرات جزئی در اجزای یک ورودی عمل میکنند (مانند تغییر ظریف در رنگ پیکسلهای یک تصویر). آنها این تغییرات را تا زمانیکه موجب هدایت شبکه بهسوی طبقهبندی اشتباه شود، ادامه میدهند. گروه کوهلی میگوید که یک شبکهی عصبی قاطع نباید خروجی خود را به خاطر تغییرات جزئی در ورودی تغییر دهد و شاید بهتر باشد این ویژگی ازنظر ریاضی در شبکه گنجانده شده و چگونگی یادگیری آن را محدود کند.
البته در حال حاضر کسی راهحلی برای برطرف کردن مشکل کلی شکنندگی سیستمهای هوش مصنوعی ندارد. بنگیو میگوید ریشهی این مسئله آن است که شبکههای عصبی عمیق، مدل خوبی برای چگونگی انتخاب ویژگیهای مهم ندارند. هنگامی که یک هوش مصنوعی تصویر مستندی از یک شیر را بهعنوان یک کتابخانه میبیند، یک انسان آن را هنوز یک شیر میبیند زیرا او دارای یک مدل ذهنی از حیوان بوده که این مدل ذهنی مبتنی بر مجموعهای از ویژگیهای رده بالا است (گوشها، دم، یال و غیره) که به او اجازه میدهد که آن را از ویژگیهای رده پایین یا جزئیات تصادفی جدا کند. بنگیو میگوید:
ما از تجارب گذشته میدانیم که کدام ویژگیها مهم هستند و این از درک عمیق ما درمورد ساختار جهان حاصل میشود.
یک روش برای پرداختن به این مسئله، ترکیب شبکههای عصبی عمیق با هوش مصنوعی سمبلیک است که قبل از یادگیری ماشین، مدل غالب در این زمینه بود. بهکمک هوش مصنوعی سمبلیک، ماشینها با استفاده از قوانین کدنویسی سخت درمورد چگونگی کار جهان استدلال میکنند؛ مانند اینکه این جهان، حاوی اشیاء گسستهای است که به طرق مختلفی با هم در ارتباط هستند.
برخی از پژوهشگران مانند گری مارکوس، روانشناس دانشگاه نیویورک میگوید که مدلهای هوش مصنوعی هیبریدی راهحل این مشکل هستند. مارکوس میگوید :
یادگیری عمیق در کوتاهمدت بهقدری مفید است که مردم بینش بلندمدت خود را درمورد آن از دست دادهاند.
در ماه مه، او همبنیانگذار استارتاپی به نام Robust AI در کالیفرنیا بود که هدف آن تلفیق یادگیری عمیق با تکنیکهای هوش مصنوعی مبتنی بر قانون بود. آنها قصد داشتند رباتهایی بسازند که بتوانند بهطور بیخطر در کنار مردم کار کنند. البته کاری که دقیقا این شرکت در حال انجام آن است، مشخص نیست.
حتی اگر بتوان قوانینی را در شبکههای عصبی عمیق تعبیه کرد، عملکرد آنها وابسته به اطلاعاتی است که براساس آنها آموزش میبینند. بنگیو میگوید که عوامل هوش مصنوعی باید در محیطهای غنیتری آموزش ببینند. برای مثال، بیشتر سیستمهایی بینایی کامپیوتر در تشخیص قوطی نوشیدنی که حالت استوانهای دارد، شکست میخورند؛ زیرا آنها براساس مجموعه دادههای دوبعدی آموزش دیده بودند. نیگوین و همکارانش نیز متوجه شدند که فریب دادن این شبکهها از طریق نشان دادن اشیاء آشنا از نماهای مختلف آسان است. براین اساس، یادگیری در یک محیط سهبعدی (واقعی یا شبیهسازیشده) بهتر است.
نحوهی یادگیری هوش مصنوعی نیز باید تغییر کند. بنگیو میگوید:
یادگیری درمورد علیت باید بهوسیلهی عواملی انجام شود که در جهان واقعی کار میکنند و میتوانند آزمایش و اکتشاف کنند.
یورگن اشمیدوبر از مؤسسهی پژوهشهای هوش مصنوعی دال مول در مانو نیز در همین راستا میاندیشد. او میگوید تشخیص الگو بسیار قدرتمند است و به آن اندازه خوب است که ارزش بسیار زیادی به شرکتهای جهانی مانند علی بابا، تنسنت، آمازون، فیسبوک و گوگل میبخشد. اما موج بسیار بزرگتری در حال رسیدن است: ماشینهایی که جهان را دستکاری میکنند و با اعمال خود، دادههایی را تولید میکنند. درواقع، سیستمهای هوشهای مصنوعی که از یادگیری تقویتی برای برد در بازیهای کامپیوتری استفاده میکنند، در حال انجام چنین کاری در محیطهای مصنوعی هستند: آنها برای رسیدن به هدف و با آزمون و خطا، به روشهای مجاز، پیکسلهای روی صفحهی نمایش را دستکاری میکنند. اما محیطهای واقعی بسیار غنیتر از مجموعه دادههای شبیهسازیشده یا دادههای سازماندهیشدهای است که امروزه بیشتر شبکههای عصبی عمیق با استفاده از آنها آموزش میبینند.
رباتهایی که ابتکار عمل دارند
در آزمایشگاهی در دانشگاه کالیفرنیا یک بازوی رباتیک در میان اشیاء درهم به جستوجو مشغول است. او یک کاسهی قرمز را برمیدارد و با استفاده از آن یک دستکش آبی را چند سانتیمتر به سمت راست هل میدهد. او کاسه را میاندازد و یک بطری پلاستیکی خالی را برمیدارد. سپس شکل و وزن یک کتاب را بررسی میکند. طی چندین روز مکاشفهی بدون وقفه، ربات درمورد این اشیاء بیگانه و کاری که با استفاده از آنها میتواند انجام دهد، حسی به دست میآورد. این بازوی رباتیک در حال استفاده از یادگیری عمیق درجهت آموزش استفاده از ابزار است. وقتی جعبهای از اشیاء در اختیار او قرار داده میشود، او آنها را به نوبت برداشته و به آنها نگاه میکند، او میبیند که وقتی اشیاء را تکان میدهد و آنها را به هم میکوبد، چه اتفاقی میافتد.

رباتهایی که از یادگیری عمیق برای اکتشاف نحوهی استفاده از ابزارهای سهبعدی استفاه میکنند
هنگامی که پژوهشگران هدفی را برای ربات مشخص میکنند (برای مثال به او تصویری از یک جعبهی تقریبا خالی نشان میدهند تا او اشیاء را به آن شکل مرتب کند)، ربات ابتکار عمل به خرج داده و میتواند با اجسامی کار کند که قبلا اصلا آنها را ندیده است. او میتواند از یک اسنفج برای کنار زدن اشیاء استفاده کند. او همچنین دریافته است که استفاده از یک بطری برای ضربه زدن و کنار زدن اشیاء موجود در مسیر بهتر از برداشتن مستقیم آنها است. چلسی فین که قبلا در آزمایشگاه برکلی کار میکرد و اکنون در حال ادامهی پژوهش خود در دانشگاه استنفورد است، میگوید این نوع یادگیری، درک بسیار غنیتری از اشیاء و جهان در اختیار هوش مصنوعی قرار میدهد. اگر شما یک بطری آب یا اسنفج را فقط در تصاویر میدیدید، شاید میتوانستند آنها را در تصاویر دیگر نیز تشخیص دهید اما واقعا نمیتوانستید درک کنید که آنها چه چیزی هستند یا برای چه کاری میتوان از آنها استفاده کرد. او میگوید:
در این حالت درک شما از جهان بسیار سطحیتر خواهد بود، نسبتبه حالتی که میتوانستید واقعا با آنها تعامل برقرار کنید.
اما این روش یادگیری، فرایند کندی است. در یک محیط شبیهسازیشده، یک سیستم هوش مصنوعی میتواند با سرعت زیادی مثالهای مختلف را بررسی و درک کند. در سال ۲۰۱۷، آلفازیرو، طی یک روز آموزش دید تا در بازیهای گو، شطرنج و شوگی (نوعی شطرنج ژاپنی) پیروز شود. او برای هر رویداد بیش از ۲۰ میلیون بازی آموزشی انجام داد.
رباتهای هوش مصنوعی نمیتوانند با این سرعت آموزش ببینند. جف ماهلر، همبنیانگذار شرکت هوش مصنوعی و رباتیک آمبیدکستروس میگوید، تقریبا تمام نتایج مهم یادگیری عمیق متکی بر حجم زیادی از داده هستند. جمعآوری دهها میلیون داده نیازمند سالها اجرا روی یک ربات است. از این گذشته، دادهها ممکن است چندان قابل اعتماد نباشند؛ زیرا تنظیم حسگرها طی زمان تغییر کرده و سختافزارها نیز ممکن است تخریب شوند. بههمین دلیل، در بیشتر کارهای رباتیکی که شامل یادگیری عمیق است، برای سرعت بخشیدن به روند آموزش، هنوز از محیط های شبیهسازیشده استفاده میشود. دیوید کنت، دانشجوی دکتری رباتیک مؤسسهی فناوری جورجیا در آتلانتا میگوید:
آنچه شما میتوانید یاد بگیرید، به این موضوع بستگی دارد که شبیهسازها چقدر خوب هستند.
شبیهسازها همواره در حال پیشرفت بوده و پژوهشگران درزمینهی انتقال درسهای آموختهشده در دنیاهای مجازی به دنیای واقعی در حال پیشرفت هستند؛ اگرچه چنین شبیهسازیهایی هنوز هم با پیچیدگیهای موجود در جهان واقعی مطابقت ندارند. فین استدلال میکند که افزایش مقیاس یادگیری با استفاده از رباتها، آسانتر از یادگیری با دادههای مصنوعی است. ربات او که در حال یادگیری استفاده از ابزار است، برای یادگیری یک وظیفهی نسبتا ساده به چندین روز زمان نیاز دارد اما احتیاجی به نظارت سنگین ندارد. او میگوید:
شما ربات را اجرا میکنید و هر چند وقت یک بار آن را چک میکنید.
او روزی را تصور میکند که تعداد زیادی از این رباتها در جهان واقعی بهطور مستقل و بدون وقفه در حال یادگیری هستند. بهعقیدهی او، این کار باید امکانپذیر باشد، چرا که انسانها نیز از همین طریق جهان را درک میکنند. اشمیدوبر میگوید:
یک کودک ازطریق دانلود کردن اطلاعات از فیسبوک چیزی یاد نمیگیرد.

یادگیری با استفاده از دادههای کمتر
کودک میتواند موارد جدید را از روی دادههای کم تشخیص دهد: حتی اگر هرگز قبلا زرافه ندیده باشد، پس از یکی دوبار دیدن، آن را یاد میگیرد. علت این سرعت یادگیری تاحدودی به این موضوع مربوط میشود که اگرچه کودک زرافه ندیده، اما موجودات زندهی دیگری را دیده و با ویژگیهای متمایز آنها آشنا است. یک اصطلاح کامل برای اعطای این نوع قابلیت به هوش مصنوعی، «یادگیری انتقالی» است: ایده انتقال دانش بهدستآمده از دورههای قبلی آموزش به وظیفهی بعدی. یک راه برای انجام این کار، استفادهی مجدد از تمام یا بخشی از شبکهی قبلا آموزشدیده، بهعنوان نقطهی آغاز آموزش برای یک وظیفهی جدید است. برای مثال، استفادهی مجدد از قسمتهایی از شبکههای عصبی عمیق که قبلا برای شناسایی نوعی حیوان استفاده شده است (مثلا لایههایی که شکل اصلی بدن را میشناسند)، میتواند هنگام یادگیری برای شناسایی یک زرافه اطلاعات مقدماتی مفیدی را در اختیار شبکه قرار دهد.
هدفِ یک شکل افراطی از یادگیری انتقالی، آموزش یک شبکهی جدید ازطریق نشاندادن فقط چند مثال و گاهی تنها یک مورد است. این روش که با نام یادگیری یک مرحلهای (one-shot) یا چند مرحلهای (few-shot) معروف است، بهشدت متکی بر شبکههای عصبی عمیقی است که از قبل آموزش دیدهاند. تصور کنید که میخواهید یک سیستم تشخیص چهره بسازید که افراد را در یک پایگاه دادهی جنایی شناسایی کند. یک روش، استفاده از شبکهی عصبی عمیقی است که قبلا میلیونها چهره را دیده است (نه لزوما آنهایی در پایگاه داده هستند)، بهطوری که ایدهی خوبی از ویژگیهای برجستهای نظیر شکل بینی و فک به دست آورده باشد. حال، وقتی که شبکه به چهرهی جدیدی نگاه میکند، میتواند ویژگیهای مفید آن تصویر را استخراج کرده و سپس این ویژگیها را با خصوصیات تصاویر موجود در پایگاه داده مقایسه کند و شبیهترین مورد را پیدا کند. داشتن این نوع حافظهی از پیش آموزشدیده به هوش مصنوعی کمک میکند تا بدون نیاز به دیدن الگوهای زیاد، نمونههای جدید را تشخیص دهد. این کار موجب افزایش سرعت یادگیری با رباتها میشود.
اما چنین شبکههایی هنوز هم ممکن است در مواجهه با موضوعاتی که از تجربهی آنها فاصلهی زیادی دارد، دچار مشکل شوند. هنوز قدرت تعمیم چنین شبکههایی مشخص نیست. حتی موفقترین سیستمهای هوش مصنوعی مانند آلفازیروی دیپمایند نیز محدودیتهایی دارند. الگوریتم آلفازیرو میتواند آموزش ببیند تا هم گو و هم شطرنج بازی کند اما نمیتواند هر دو را بهصورت همزمان بازی کند. آموزش مجدد ارتباطات و پاسخها، به گونهای که بتواند در بازی شطرنج برنده شود، موجب تنظیم مجدد هرگونه تجربهی قبلی درمورد بازی گو میشود. فین میگوید:
اگر شما از منظر یک انسان به این مسئله فکر کنید، خندهدار است. انسانها چیزی که یاد گرفتهاند را بهراحتی فراموش نمیکنند.
یادگیری نحوه یادگیری
موفقیت آلفازیرو در بازیها فقط به خاطر کارآمدی یادگیری تقویتی آن نبود، بلکه همچنین بهعلت استفاده از الگوریتمی بود که به آن کمک میکرد تا انتخابهای خود را محدودتر کند (براساس تکنیکی به نام درخت جستجوی مونت کارلو تعریف شده بود). بهعبارت دیگر، هوش مصنوعی در جهت بهترین حالت یادگیری از محیط خود هدایت میشد. چولیت فکر میکند که مرحلهی مهم بعدی در هوش مصنوعی این است که شبکههای عصبی عمیق بتوانند بهجای استفاده از کدهای تهیهشده بهوسیلهی انسانها، الگوریتمهای خود را بنویسند. او استدلال میکند که تکمیل توانایی تطبیق الگو با تواناییهای استدلال میتواند هوش مصنوعی را در برخورد با ورودیهایی فراتر از تجربهی آنها بهتر کند.
دانشمندان علوم کامپیوتر، مدتها است «سنتز برنامه» را مورد مطالعه قرار دادهاند که در آن یک کامپیوتر بهطور خودکار کد تولید میکند. چولیت فکر میکند که ترکیب این زمینه از علم کامپیوتر با یادگیری ماشین بتواند منجر به توسعهی سیستمهایی شود که به سیستم اندیشهی انتزاعی انسان بسیار نزدیک باشد. در این زمینه، کریستن گرامن، دانشمند علوم کامپیوتر مرکز پژوهشهای هوش مصنوعی فیسبوک و دانشگاه تگزاس درحال آموزش رباتها است تا به بهترین نحو محیطهای جدید را کشف کنند. این کار میتواند شامل انتخاب جهتِ نگاه کردن هنگام دیدن یک صحنهی جدید باشد یا این موضوع باشد که برای دستیابی به بهترین درک درمورد شکل یا هدف یک شی، آن شی را چگونه باید دستکاری کرد. ایده این است که کاری کنیم که هوش مصنوعی بتواند پیشبینی کند که کدام نما یا زاویه، مفیدترین دادهها را برای یادگیری او مهیا میکند.
پژوهشگران میگویند که آنها در حال تلاش درجهت حل نواقص یادگیری عمیق هستند اما در عین حال اعتراف میکنند که هنوز مشغول به جستجوی تکنیکهای جدیدی برای کاهش شکنندگی فرایند هستند. سونگ میگوید تئوری چندانی پشت یادگیری عمیق وجود ندارد. او میگوید:
اگر چیزی کار نکند، درک علت آن دشوار است. کل این حوزه هنوز بسیار تجربی است و شما فقط باید مسائل را امتحان کنید.
اگرچه در حال حاضر، دانشمندان از شکنندگی شبکههای عصبی عمیق و اتکای آنها روی حجم عظیم دادهها آگاهند، اما اکثر آنها معتقدند که فعلا این تکنیک ماندنی است و بهگفتهی کلون: «کسی واقعا ایدهای درمورد چگونگی بهتر شدن آن ندارد.»
نظرات