صنعت دیجیتال و چالشهای فردای آن در پیوند ناگسستنی کامپیوتر با انسان

در ادامهی عصر ارتباطات چه آیندهای در انتظار صنعت دیجیتال است؟ احتمالاً در پایان این مقاله بتوانیم پاسخ درخوری برای این پرسش در ذهن خود داشته باشیم. انقلاب دیجیتال علاوه بر رباتهای شطرنجباز، خودروهای خودران و عصر نوین اطلاعات، چالشهای اخلاقی بزرگی نیز با خود به ارمغان آورده است.
مقالهای که در حال خواندن آن هستید در یک لپتاپ نوشته و نگارش [و روی یک کامپیوتر رومیزی به فارسی ترجمه] شده است. اگر چند دهه پیش چنین وسیلهی تاشدنی، سبک و قابلحملی را به دانشمندان نشان میدادید سر جای خود میخکوب میشدند، و اگر چند دهه بیشتر در زمان به عقب برگردید لپتاپ به چشم آنان یک محصول کاملاً جادویی به نظر میرسید. میلیاردها واحد پردازشی کوچک وظیفهی پردازش میلیونها خط کدهای دستوری را که حاصل تلاش افراد بیشماری در سراسر جهان است، برعهده دارند. این پردازندهها در یک فضای کوچک در کنار یکدیگر بهصورت فشرده قرار گرفتهاند تا وسیلهای مانند لپتاپ ساخته شود. کامپیوترها با سرعت غیرقابلتصوری کار میکنند، شما کافی است کلیک کنید یا چیزی تایپ کنید یا حرفی بزنید تا نتیجهی کارتان را بهصورت لحظهای در نمایشگر ببینید.
زمانی کامپیوترها چنان سنگین و بزرگ بودند که برای جابهجایی آنها از جرثقیل استفاده میشد و یک اتاق را بهطور کامل اشغال میکردند؛ اما اکنون کامپیوترها همه جا حضور دارند، آنها را میتوان در ساعتها، موتور خودروها، دوربینهای عکاسی، تلویزیون و اسباببازیها پیدا کرد. در کنترل شبکههای برق، تحلیل دادههای علمی و پیشبینی آبوهوا از کامپیوترها استفاده میشود. تصور یک دنیای مدرن بدون کامپیوتر ممکن نیست.
دانشمندان همواره در تلاشند کامپیوترهای سریعتر و برنامههای هوشمندتری بسازند و همزمان از فناوری خود با احترام به ارزشهای اخلاقی استفاده کنند. تلاشهای دانشمندان امروزی مرهون بیش از یک قرن ابداعات و نوآوری در حوزههای مختلف فناوری و علوم محض است.
در سال ۱۸۳۳ یک ریاضیدان انگلیسی به نام چارلز بابج طرحهای اولیهی یک ماشین قابلبرنامهریزی را در ذهن خود میپروراند. این وسیله با داشتن یک محل ذخیره برای نگهداری و یک واحد عملیاتی برای پردازش اعداد و معرفی یک واحد خوانش و چاپ، اولین سنگ بنای فناوری معماری کامپیوتر را بر جا نهاد. این وسیله با نام موتور تحلیلگر قادر به انجام عملیات منطقی (اگر X پس Y) بود. بابج تنها موفق به ساخت بخشی از ماشین محاسباتی خود شد، اما یکی از همکارانش به نام آدا لاولیس متوجه شد اعدادی که ماشین روی آنها کار میکند میتوانند بیانگر هر نوع اطلاعاتی همچون موسیقی باشند. لاولیس در جایی نوشته بود:
یک زبان جدید، وسیع و قدرتمند برای به پیش بردن آیندهی پردازش متولد شده است.
لاولیس تبدیل به یکی از اولین کارشناسان استفادهکننده از ماشین تحلیلگر شد. اغلب از او بهعنوان اولین برنامهنویس تاریخ یاد میشود. در سال ۱۹۳۶ یک ریاضیدان انگلیسی دیگر به نام آلن تورینگ ایدهی ساخت کامپیوتری را مطرح کرد که میتوانست دستورالعملهای خود را بازنویسی کند، بهعبارت دیگر یک کامپیوتر قابلبرنامهریزی که میتوانست استفادههای مختلفی از آن کرد. مفهوم ریاضی معرفی شده توسط تورینگ با استفاده از واژگان عملیاتی محدود میتوانست کارکرد ماشینهای محاسباتی با هر پیچیدگی را تقلید کند. برخلاف خود تورینگ که سرنوشت غمانگیزی داشت، کامپیوتر مکانیکی او به شهرت جهانی رسید و نام آن ماشین جهانی تورینگ گذاشته شد.
ساخت اولین کامپیوتر الکتریکی قابلاطمینان جهان به نام کلوسوس در سال ۱۹۴۳ به پایان رسید. انگلستان از این کامپیوتر برای رمزگشایی کدهای زمان جنگ استفاده میکرد. در ساخت این کامپیوتر به جای قطعات مکانیکی مانند چرخدندههای موتور تحلیلگر، از تیوبهای خلأ استفاده شده بود؛ لولههایی که میتوانستند حرکت الکترونها را کنترل کنند. این کار باعث شد کلوسوس نسبت به کامپیوترهای پیشین بسیار سبکتر باشد اما مهندسان برای استفاده از آن جهت انجام یک وظیفهی دیگر باید به صورت دستی سیمکشی آن را تغییر میدادند.
اولین کامپیوتر الکتریکی ایالات متحده آمریکا به نام انیاک (ENIAC) سی تن وزن داشت و در ساخت آن از ۱۹ هزار عدد لامپ خلأ استفاده شده بود، انیاک ۱۳۰ هزار وات انرژی مصرف میکرد؛ برای مقایسه در نظر بگیرید مصرف انرژی لپتاپهای متداول امروزی که احتمالاً خود شما هم یکی از آنها را دراختیار دارید، فقط ۵۰ وات ساعت است. تیم سازندهی انیاک احتمالاً با الهام از ایدهی تورینگ در مورد ساخت یک کامپیوتر قابل برنامهریزی، طرح ساخت یک کامپیوتر دیگر به نام ادواک (EDVAC) را توسعه دادند. در ساخت ادواک از یک معماری جدید استفاده شده بود. جان نیومن ریاضیدانی که در سال ۱۹۴۵ ادواک را طراحی کرده بود از سیستمی سخن گفت که میتوانست علاوه بر دادهها، برنامهها را نیز در حافظهی خود ذخیره کرده و آنها را تغییر دهد. این کامپیوتر برخلاف انیاک که از سیستم دسیمال یا دهدهی استفاده میکرد، از سیستم اعداد باینری یا دودویی بهره میبرد. ستاپ ابداعی نیومن که معماری نیومن نامیده میشود اساس الگوی عملکرد کامپیوترهای امروزی است.
اولین کامپیوتر تاریخ ایالات متحده ۱۳۰ هزار وات برق مصرف میکرد
در سال ۱۹۴۷ محققان آزمایشگاه بل (آزمایشگاهی که مؤسس آن گراهام بل مخترع تلفن بود) موفق به اختراع وسیلهای شدند که آیندهی ساخت کامپیوترها را برای همیشه دستخوش تغییر کرد. این وسیله که به نام ترازیستور شناخته میشد، مداری الکتریکی بود که با استفاده از ولتاژ (همان فشار الکتریکی) میتوانست جریان الکتریکی یا حرکت الکترونها بین دو نقطه را کنترل کند. ترانزیستورها در نهایت جایگزین تیوبهای خلأ کمبازده و کند شدند.
در سالهای ۱۹۵۸ و ۱۹۵۹ دو شرکت آمریکایی تگزاس اینسترومنتس و صنایع نیمههادی فیرچایلد بهصورت مستقل موفق به اختراع مدارهای مجتمع شدند، وسیلهای که ترانزیستورها و مدارهای پشتیبانی در فرآیندی روی یک تراشه سوار میشوند.
از زمان ساخت کامپیوترهای الکتریکی فقط کارشناسان میتوانستند کامپیوترها را برنامهریزی کنند. اما در سال ۱۹۵۷ شرکت آیبیام محصول فورترن را معرفی کرد. فورترن یک زبان برنامهنویسی است که فهم و نوشتن برنامههای کامپیوترای را بسیار راحت میکند. برنامهی فورترن پس از گذشت ۶۵ سال هنوز هم در مراکز آموزشی و علمی مورد استفاده قرار میگیرد. در سال ۱۹۸۱ آیبیام از کامپیوتر شخصی IBM PC رونمایی کرد و همزمان شرکت مایکروسافت اولین سیستم عامل خود به نام اماس داس را روانه بازار کرد. نتیجهی معرفی این محصولات ترویج استفاد از کامپیوترهای شخصی در محیطهای کاری و خانگی بود. اپل با معرفی سیستم عامل خود که ابتدا در سال ۱۹۸۲ در کامپیوتر لیسا و سپس در ۱۹۸۴ در مکینتاش استفاده شده بود عصر شخصیسازی در دنیای صنعت کامپیوتر را شروع کرد. این دو محصول شرکت اپل باعث محبوبیت استفاده از رابط کاربری تصویری یا GUI شدند، سیستمهایی که به جای خطهای دستوری از نشانگر ماوس استفاده میکردند.

Colossus، اولین کامپیوتر قابلبرنامهریزی الکترونیکی قابل اعتماد جهان، به نیروهای اطلاعاتی بریتانیا در رمزگشایی کدها در جنگ جهانی دوم کمک کرد.
در این حین محققان در تلاش برای کشف راههای سریعتری برای برقراری ارتباط انسانها و کامپیوترها با همدیگر بودند. در سال ۱۹۴۸ ریاضیدان پرآوازهی آمریکایی به نام کلاد شانون با انتشار مقالهای با عنوان تئوری ریاضی ارتباطات، پایه و اساس نظریهی اطلاعات را بنا گذاشت و باعث محبوبیت استفاده از کلمهی بیت در دنیا شد. ایدههای شانون باعث شکلدهی به فناوری محاسبات و البته به اشتراک گذاشتن اطلاعات ازطریق سیم و هوا شد.
در سال ۱۹۶۹ آژانس پروژههای تحقیقاتی پیشرفتهی ایالات متحده متعلق به وزارت دفاع این کشور از یک شبکهی ارتباطی کامپیوتری به نام آرپانت ARPANET رونمایی کرد. پس از ادغام دیگر شبکههای ارتباطی با آرپانت اینترنت متولد شد. در سال ۱۹۹۰ دانشمندان در آزمایشگاه سرن در نزدیکی شهر ژنو، برای اولین بار قوانین انتقال اطلاعات را معرفی کردند، قوانینی که شالودهی شبکهی جهانی وب را تشکیل داد.
پیشرفتهای فناوری در دهههای گذشته راه را برای ارتباط سریعتر و بهتر انسانها با یکدیگر هموار کرده است. صنعت دیجیتال با سرعت سرگیجهآوری به رشد خود ادامه میدهد. اما پردازندهها چقدر میتوانند سریعتر و قویتر شوند؟ الگوریتمها چقدر میتوانند هومشمندانهتر شوند؟ و با پیشرفت بیشتر فناوری باید انتظار چه دستاوردها و تهدیداتی را داشته باشیم؟ استوارت راسل، دانشمند علوم کامپیوتر از دانشگاه کالیفرنیا میگوید پیشرفت صنعت ساخت پردازنده نوید فرصتهای جذابی را به ما میدهد. او میگوید:
کامپیوترها در آینده میتوانند به گسترش خلاقیت هنری، سرعتبخشیدن به تحقیقات علمی، توسعه دستیارهای شخصی دیجیتال و ساخت خودروها خودران کمک کنند؛ و البته امیدوارم ما را نکشند.
در تعقیب سرعت
گویی کامپیوتر به زبان بیتها سخن میگویند. آنها اطلاعات گوناگون از جمله موسیقی، برنامه یا پسووردها را بهصورت رشتهای از اعداد ۰ و ۱ ذخیره میکنند. این اطلاعات بهصورت باینری پردازش میشوند، یعنی ترانزیستورها بین دو حالت روشن و خاموش تغییر وضعیت میدهند. هر قدر تعداد ترانزیستور بیشتری در پردازندهی یک کامپیوتر وجود داشته باشد، سرعت آن در پردازش بیتها بیشتر خواهد بود و نتیجهی آن اجرای سریعتر برنامه یا انجام بازیهای کامپیوتری بهصورت واقعیتر یا دستیابی به کنترل ترافیک هوایی ایمنتر خواهد بود.
ترکیب ترانزیستورها باعث تشکیل یکی از اجزای سازندهی مدار مجتمع به نام گیت منطقی میشود. نوعی از گیت منطقی که هر دو ورودی آن مثبت باشند گیت منطقی AND و اگر یکی از ورودیها مثبت باشد گیت منطقی OR نامیده میشود. با قرار دادن مقدار زیادی از گیتهای منطقی در کنار یکدیگر میتوان الگوی پیچیدهی ترافیک الکترونها را کنترل کرد. گیتهای منطقی به نوعی تجسم فیزیکی عمل محاسبه است. یک چیپ کامپیوتر از میلیونها گیت منطقی تشکیل شده است.
گیت منطقی تجسم فیزیکی عمل محاسبه است
بنابراین هرچه تعداد گیتهای منطقی بیشتر باشد ترانزیستورهای بیشتری در ساخت کامپیوتر به کار رفته و به همان اندازه قدرت و سرعت پردازش آن بیشتر خواهد بود. در سال ۱۹۶۵ گوردن مور یکی از بنیانگذاران صنایع نیمههادی فیرچایلد، که بعدا شرکت اینتل را تأسیس کرد، مقالهای در مورد آیندهی تراشههای کامپیوتری با عنوان کارگذاشتن اجزای بیشتر در مدارهای مجتمع به نگارش درآورد. او با اشاره به این موضوع که از سال ۱۹۵۹ تا ۱۹۶۵ تعداد اجزای سازندهی مدارهای مجتمع (اغلب ترانزیستورها) در هر سال دو برابر شده است، پیشبینی کرد که این روند در سالهای آینده نیز ادامه یابد.
گوردن مور در سال ۱۹۷۵ در یک سخنرانی به سه مولفهی اصلی رشد تصاعدی صنعت ساخت کامپیوتر اشاره کرد؛ ترانزیستورهای کوچکتر، چیپهای بزرگتر و در پیش گرفتن روشهای هوشمندانهتر در ساخت مدارها و سایر تجهیزات مانند کاهش حجم فضای تلف شده در ساخت پردازندهها. مور گفت انتظار دارد پیچیدگی مدارهای مجتمع یا در واقع تعداد تزانزیستورهای بهکاررفته در ساخت تراشهها هر دو سال یکبار دو برابر شود. به این روند که برای چند دهه ادامه داشته است، قانون مور میگویند.
قانون مور بیشتر ناظر به جنبهی اقتصادی ساخت کامپیوترها بوده است. برای ساخت کامپیوترهای سریعتر و ارزانتر همواره انگیزههای اقتصادی وجود داشته است؛ چراکه شرکتهای سازنده همواره بهدنبال سود بیشتر ازطریق افزایش فروش محصولات بودهاند. اما از یک نقطه به بعد محدودیتهای علم فیزیک وارد صحنه میشود. روند توسعهی ساخت چیپ نمیتواند تا ابد از قانون مور پیروی کند، چراکه رفتهرفته ساخت ترانزیستورهای کوچک سختتر میشود. طبق موضوعی که بهشوخی از سوی برخی قانون دوم مور نامیده شده است، هزینهی توسعه تراشههای جدید هر چند سال یکبار دو برابر میشود. طبق گزارشها بزرگترین شرکت سازندهی محصولات نیمههادی در دنیا یعنی TSMC قرار است یک کارخانهی ۲۵ میلیارد دلاری تأسیس کند. TSMC یک شرکت تایوانی است و کمپانیهای بزرگی مانند AMD، اپل، انویدیا و مدیاتک از جمله مشتریان محصولات این شرکت هستند.
اما امروزه قانون مور دیگر معتبر نیست، روند دو برابر شدن اکنون با سرعت آهستهتری اتفاق میافتد. ما در هر نسل جدید از پردازندهها میتوانیم ترانزیستورهای بیشتری در تراشه کار بگذاریم اما نسلهای جدید سختافزاری با سرعت کمتری از راه میرسند. بااینحال محققان بهدنبال روشهای نوینی برای ساخت تراشههای جدید هستند، روشهایی مانند ساخت ترانزیستورهای بهتر یا ساخت چیپهای مخصوص، توسعه مفاهیم پایهای جدید برای ساخت تراشهها و البته برنامههای نرمافزاری کاربردیتر.
سانجی ناتاراجان، مدیر بخش طراحی تراشه در شرکت اینتل میگوید:
ما معتقدیم در معماری فعلی ترانزیستورها یعنی فینفت (FinFET) تا آنجایی که جا دارد اجزا را در داخل فضای محدود جای دادهایم.
ناتاراجان بر این باور است که در سالهای آینده سازندگان تراشهها به ساخت نوع جدیدی از ترانزیستورها روی خواهند آورد: ترانسیزتورهایی که یکی از اجزای اصلی آن به جای داشتن شباهت به بال مالی شبیه روبان خواهد بود. این تغییر ساختاری باعث افزایش سرعت ترانزیستورها و کاهش نیاز به انرژی و فضا خواهد شد.
حتی اگر سخن ناتارجان درست باشد و ما به حد نهایی کوچک کردن ترانزیستورها رسیده باشیم، طبق اصل سوم مور در مورد هوشمند کردن مدارهای مجتمع، راهی طولانی برای افزایش کارآمدی کامپیوترها در پیش داریم. در ساخت تجهیزات الکترونیکی امروزی از چیزی به نام شتابدهنده استفاده میشود. از شتابدهندهها برای انجام یک وظیفهی مشخص مانند توسعهی هوش مصنوعی، کارهای گرافیکی یا ارتباطات استفاده میشود. شتابدهندهها نسبت به واحدهای پردازشی چند منظوره در انجام یک وظیفهی مشخص بسیار سریعتر بوده و استفاده از آنها بهصرفهتر است.
برخی از انواع شتابدهندهها ممکن است در آینده از فناوری محاسبات کوانتومی استفاده کنند. در محاسبات کوانتومی از دو اصل دنیای زیراتمی بهره برده میشود:
- اصل اول: برهمنهی
- اصل دوم: درهمتنیدگی
برهمنهی به این معنی است که ذرهها ممکن است در یک لحظه نه در یک حالت بلکه در ترکیبی از چند حالت مختلف قرار داشته باشد، تا این که وضعیت ذره بهطور صریح مورد اندازهگیری قرار بگیرد؛ در آنصورت ذره در یک حالت مشخص ظاهر میشود. بنابراین یک سیستم کوانتومی اطلاعات را به صورت کیوبیت ذخیره و پردازش میکند و احتمالات مربوط به وضعیت الکترون را در هنگام اندازهگیری به صورت ۰ یا ۱ نشان میدهد. اصل دوم یعنی درهمتنیدگی درمورد ارتباط مرموز بین دو عنصر کوانتومی فارغ از فاصلهی بین آن دو ذره است. طبق اصل درهمتنیدگی رفتار یک ذره بهصورت همزمان روی رفتار یک ذرهی دیگر تأثیر میگذارد، درحالیکه ممکن است دو ذره در فواصل کهکشانی مانند چند سال نوری از یکدیگر قرار گرفته باشند. سرعت این نوع ارتباط هرچه که باشد بسیار بیشتر از سرعت نور است. یک سیستم متشکل از کیوبیتها با استفاده از این دو ویژگی مکانیک کوانتوم با سرعت تصاعدی میتواند ترکیبی از احتمالات صفر و یک متعلق به مقدار زیادی از اطلاعات را ارزیابی و پردازش کند.
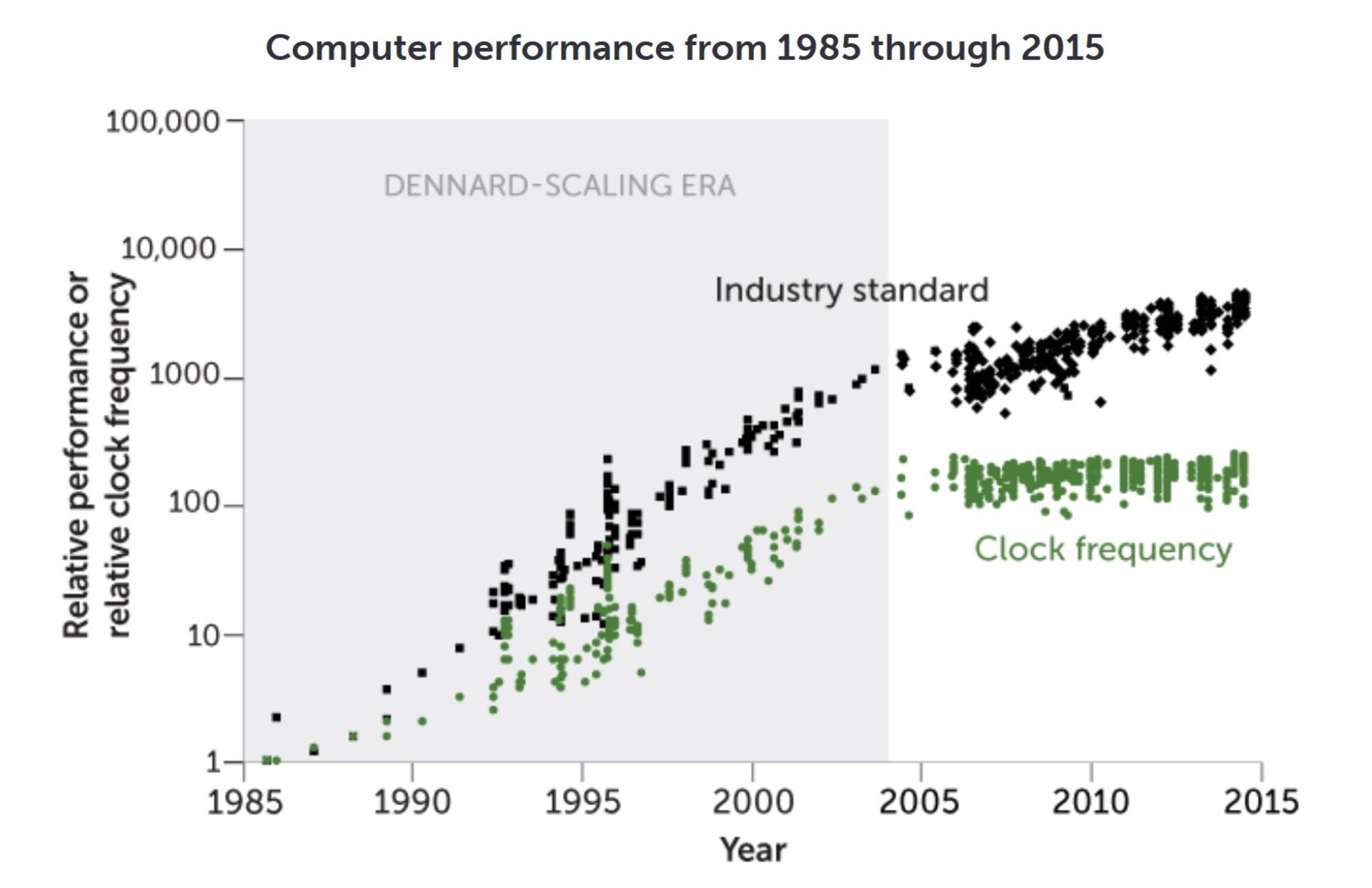
تا حدود سال ۲۰۰۴، کوچک شدن ترانزیستورها با بهبود عملکرد کامپیوتر (رنگ سیاه نشانگر استاندارد صنعی است) و فرکانس ساعت (تعداد چرخههای عملیات انجامشده در ثانیه به رنگ سبز) همراه بود.از جایی به بعد، «مقیاس بندی دنارد» دیگر برقرار نبود و ترانزیستورهای کوچکشونده مزایای مشابه و متناسب با گذشته را نداشتند.
کیوبیتها میتوانند اشکال مختلفی داشته باشند اما یکی از محبوبترین آنها در میان محققان جریان در سیمهای ابررسانا است. این سیمها باید در دمای نزدیک به صفر مطلق یعنی منفی ۲۷۳ درجه سلسیوس نگهداری شوند تا میزان نوسان اتمها به حداقل ممکن برسد. حرکت اتمها میتواند در برهمنهی و درهمتنیدگی کیوبیتها اختلال ایجاد کند. همچنین در کامپیوترهای کوانتومی باید از کیوبیتهای فیزیکی زیادی برای ساخت یک کیوبیت منطقی یا مؤثر استفاده شود، چراکه کیوبیتهای اضافی بهعنوان عامل تصحیح خطا عمل میکنند.
کامپیوترهای کوانتومی که به عرصهی رقابت کشورهای ابرقدرت تبدیل شده است، دارای کاربردهای علمی و صنعتی متنوعی است، از یادگیری ماشین و تنظیم بهتر برنامه زمانبندی حرکت قطارها گرفته تا شبیهسازی مکانیک دنیای واقعی کوانتوم و علم شیمی، و البته کاربردهای پردازش اطلاعات نظامی. بااینحال بعید است که از کامپیوترهای کوانتومی چندمنظوره بهصورت گسترده و خانگی استفاده شود. مشخص نیست که آیا روزی با کامپیوتر کوانتومی خود بتوانید در خانهی خود نرمافزار ورد را اجرا کنید یا خیر!
ایدههای مفهومی جدید برای ساخت تراشهها
راههای جدیدی برای افزایش سرعت شتابدهندههای مخصوص و بهصورت کلی پردازندههای چندمنظوره وجود دارد. تام کونته دانشمند علوم کامپیوتر از مؤسسهی جورجیاتک در آتالانتا و رهبر گروه تحقیقاتی IEEE Rebooting به دو الگوی جدید اشاره میکند. مورد اول ابررسانایی است، شرایطی که در آن تراشهها در دماهای بسیار پایین کار میکنند تا مقاومت الکتریکی ترانزیستورها به حداقل ممکن برسد. مورد دوم محاسبهی معکوس است، یعنی استفادهی مجدد از بیتها قبل از اینکه بهصورت حرارت از سیستم دفع شوند. در سال ۱۹۶۱ رولف لاندوئر فیزیکدان شرکت آیبیام با ترکیب نظریهی اطلاعات و ترمودینامیک به این نتیجه رسید وقتی که گیت منطقی دو بیت بهصورت ورودی دریافت کرده و یک بیت خروجی تحویل میدهد، بیت دیگر را از بین میبرد و آن را به صورت حرارت و افزایش آنتروپی به محیط دفع میکند. وقتی میلیاردها ترانزیستور بهطور همزمان میلیونها پردازش در هر ثانیه انجام میدهند، میزان حرارت تلفشده به رقم قابلتوجهی میرسد، و درنتیجه کامپیوتر برای پردازش بیشتر و سرد کردن خود به الکتریسیتهی بیشتری نیاز پیدا میکند که نتیجهی آن تولید حرارت بیشتر است. مایکل فرنک دانشمند علوم کامپیوتر از آزمایشگاه ملی ساندیا در نیومکزیکو در مقالهای در سال ۲۰۱۷ نوشت:
یک کامپیوتر معمولی در اصل یک هیتر الکتریکی گرانقیمت است که در کنار تولید حرارت زیاد کمی هم کار پردازشی انجام میدهد.
اما در فرایند محاسبهی معکوس تعداد خروجی گیتهای منطقی به اندازهی ورودی آنها است؛ یعنی اگر از یک گیت منطقی بهصورت معکوس استفاده کنید، برای مثال میتوانید از سه بیت خروجی، سه بیت ورودی بگیرید. برخی از محققان در حال کار روی گیتهای منطقی هستند که نهتنها از اتلاف بیتهای اضافی جلوگیری میکنند بلکه از این بیتها برای انجام محاسبات بیشتر استفادهی مجدد میکنند. فیزیکدان نامآشنا ریچارد فاینمن اینطور نتیجهگیری میکند که به جز اتلاف انرژی در انتقال دادهها، هیچ محدودیت تئوریک دیگری برای افزایش کارآمدی عمل پردازش وجود ندارد.
کونته معتقد است با ترکیب محاسبهی معکوس و ابررسانایی میتوان با یک تیر دو نشان زد. با روش پردازش کارآمد میتوانید عملیات بیشتری با یک تراشهی مشخص انجام دهید و از طرف دیگر در مورد مصرف انرژی و اتلاف حرارت نگرانی کمتری داشته باشید. کونته میگوید یک یا هر دوی این روشها ستون فقرات صنعت ساخت پردازنده در آینده خواهد بود.
نوآوریهای نرمافزاری
محققان مشغول کار روی چند فناوری جدید در ارتباط با ساخت ترانزیستورها و دیگر اجزای پردازنده، طراحی تراشهها و الگوهای جدید ساخت سختافزار هستند. فوتونیک، اسپکترونیک، مولکولهای زیستی و نانوتیوبهای کربنی از جمله این فناوریها هستند. بااینحال تنها بهوسیلهی تغییر در کدهای دستوری میتوان از نسل فعلی پردازندهها و معماری تراشهها استفادهی بیشتری به عمل آورد.
برای مثال در سال ۲۰۲۰ در مقالهای که در مجلهی ساینس منتشر شده بود، محققان به مطالعهی یک مسئلهی سادهی ریاضی یعنی ضرب دو ماتریس، یا همان شبکههای عددی، پرداختند. محققان با استفاده از یک زبان برنامهنویسی جدید و تغییر کدهایی در نرمافزاری که کامپیوتر از آن استفاده برای پردازش اطلاعات استفاده میکرد، موفق شدند سرعت پردازش حاصلضرب دو ماتریس را تا ۶۰ هزار برابر نسبت به زبان برنامهنویسی محبوب و کاربرپسند پایتون افزایش دهند.
نیل تامپسون محقق مؤسسهی تکنولوژی ماساچوست و یکی از نویسندگان این مقاله بهتازگی مطالعهی جدیدی درمورد تاریخچهی بهبود الگوریتمها انجام داده است. الگوریتم دستهای از دستورالعملها است که براساس قوانین تنظیمشده توسط کاربر به انجام وظیفهی محولهای همچون طبقهبندی اطلاعات میپردازد. تامپسون در مورد الگوریتمها میگوید:
برای یک دسته از الگوریتمها، سرعت تقویت و افزایش کارآمدی آنها طبق قانون مور و حتی بیشتر از آن بوده است.
افراد زیادی از جمله خود مور پایان اعتبار قانون مور را بعد از چند دهه پیشبینی کرده بودند. شاید سرعت پیشرفت کند شده باشد، اما نوآوری دانشمندان باعث شده همچنان فناوری ساخت پردازنده با سرعت چشمگیری به مسیر خود ادامه دهد.
در مسیر هوش
از اولین روزهای ظهور علوم کامپیوتر دانشمندان همواره در تلاش برای پیدا کردن جایگزینی برای قوهی تفکر انسان بودهاند. آلن تورینگ در سال ۱۹۵۰ مقالهی خود با عنوان ماشینهای محاسبهگر و هوش را با این جمله آغاز کرد:
من پیشنهاد میکنم این پرسش مطرح شود که آیا ماشینها میتوانند فکر کنند؟
او برای پاسخ به این سؤال یک آزمایش طراحی کرد و نام آن را بازی تقلید گذاشت. در این آزمایش که اکنون آزمایش تورینگ نام گرفته است، یک شخص با یک انسان دیگر و یک کامپیوتر ازطریق سؤالهای کتبی تعامل میکند. آن شخص با ردوبدل کردن سؤال و جوابهای کتبی باید تصمیم بگیرد که کدام یک از طرفهای مقابلش کامپیوتر و کدام یک انسان است. اگر شخص موفق به تشخیص کامپیوتر از انسان نشد، میتوان این طور فرض کرد که ماشین عملا توانایی فکر کردن دارد.
عبارت هوش مصنوعی برای اولین بار در سال ۱۹۵۵ در جریان یک کمپ علمی تابستانه در کالج دارتموث مورد استفاده قرار گرفت. در پروپوزال این گردهمایی علمی آمده بود:
در تلاشیم راهی پیدا کنیم تا ماشینها بتوانند فکر کنند، دارای مفهومی انتزاعی بوده و ایده داشته باشند و به حل مسائلی بپردازند که پاسخ به آنها فقط از دست انسان برمیآید و در طول این فرایند خود را بهبود ببخشند.
سازماندهندگان این همایش امیدوار بودند در طول دو ماه، ده شرکتکنندهی برجسته به نتایج قابلقبولی پیرامون این موضوع برسند.
بعد از گذشت نزدیک به شش دهه و صرف میزان زیادی نفر-ساعت، مشخص نیست که آیا پیشرفتهای بهدستآمده در جواب به این مسئله میتواند ذهنهای پرسشگر برگزارکنندگان آن همایش را قانع کند یا خیر. هوش مصنوعی زندگی روزمرهی انسانها را بهصورت محسوس و نامحسوس احاطه کرده است، از فیلتر کردن ایمیلهای اسپم گرفته تا خودروهای خودران و شکست دادن انسان در شطرنج. اما همهی اینها جنبههای سادهای از تواناییهای هوش مصنوعی است. انجام دادن یک یا دو وظیفهی مشخص با آنچه تورینگ و دیگران از هوش جامع مصنوعی یا AGI در ذهن داشتند فاصلهی بسیار زیادی دارد. هوش جامع مصنوعی، بسته به تعریف افراد، تقریباً تمام کارهایی را که انسان قادر به انجام آن است، میتواند انجام دهد.
ما شاید هیچگاه به هوش جامع مصنوعی دست پیدا نکنیم، اما در مسیر رسیدن به آن نوآوریهای مفید زیادی دست پیدا کردهایم. دوینا پریکاپ، دانشمند علوم کامپیوتر از دانشگاه مونترال و رئیس تیم تحقیقاتی مونترال شرکت دیپمایند در این مورد میگوید:
من فکر میکنم به پیشرفتهای بزرگی دست پیدا کردهایم. اما به نظر من یکی از تکههای گمشده بیشتر به موضوع اصول اساسی مربوط به هوش مصنوعی و بهطور کلی خود هوش بازمیگردد.
هوش مصنوعی در دهههای گذشته پیشرفت زیادی را تجربه کرده است که بخش بزرگی از آن مرهون روشی به نام یادگیری ماشین است. در گذشته کامپیوترها بیشتر براساس هوش مصنوعی نمادین کار میکردند، نوعی از هوش مصنوعی که براساس قوانین نوشتهشده توسط انسانها توسعه داده شده بود. برخلاف هوش مصنوعی نسل قبلی، برنامههای یادگیری ماشین با پردازش اطلاعات، خود به جستجوی الگوریتمها میپردازند. یکی از انواع سیستمهای یادگیری ماشین از روشی به نام شبکههای مصنوعی عصبی استفاده میکند که در واقع برنامهای با لایههای مختلف پردازشی است و مبنای عملکرد آن تا حدی شبیه برخی از اصول مغزهای بیولوژیکی است. در سالهای گذشته استفاده از نوعی از شبکههای عصبی چند لایه، و در برخی مواقع صدها لایه، در بین محققان محبوب شده است. به این نوع از یادگیری ماشین اصطلاحاً یادگیری عمیق گفته میشود.
سیستمهای یادگیری عمیق اکنون میتوانند در برخی از بازیها مانند شطرنج و بازی گو انسانها را شکست دهند. چنین سیستمهایی احتمالاً بهتر از انسانها میتوانند نژاد سگها را از روی عکس تشخیص دهند. برنامههای هوش مصنوعی بر مبنای یادگیری عمیق میتوانند یک نوشته را از یک زبان به زبان دیگر ترجمه کنند، کنترل حرکت رباتها را به دست بگیرند، ترانه بنویسند و نحوهی تاشدگی پروتئینها را پیشبینی کنند.
اما این سیستمها در شرایطی که مستلزم استفاده از استدلال (یا آنچه که ما به آن عقل سلیم از آن یاد میکنیم) باشند، با مشکل روبهرو میشوند. هوش مصنوعی از اصول اساسی که دنیا بر آن استوار است، چه بهصورت فیزیکی و چه از منظر اجتماعی، آگاه نیستند. تغییر جزئی تصویر یک شی بهصورتی که ما بهعنوان انسان بهراحتی متوجه آن میشویم، میتواند بهطرز عجیبی نحوهی نگرش کامپیوتر به آن را تغییر دهد. محققان متوجه شدهاند که چسباندن برچسبهای بیضرر و نامربوط به تابلوی ایست میتواند نرمافزارهای هوش مصنوعی را دچار اشتباه کند، بهنحوی که آن را تابلوی محدودیت سرعت تفسیر کند، موضوعی که بهطور مشخص ضعف سیستم خودروهای خودران را نشان میدهد.
انواع یادگیری
شاید بپرسید هوش مصنوعی را چطور میتوان ارتقا داد؟ دانشمندان علوم کامپیوتر در حال توسعهی انواع مختلفی از یادگیری ماشین هستند، از جمله یادگیری عمیق و غیرعمیق. نوعی از یادگیری ماشین، یادگیری نظارتشده نام دارد که در آن مدلها ازطریق دادههای ورودی برچسبزده شده آموزش داده میشوند؛ مانند آموزش نژاد سگها به سیستم ازطریق نشان دادن تصاویر سگها به همراه نام نژادهای آنان. اما توسعهی چنین سیستمی دشوار است چون اطلاعات زیادی باید توسط انسانها برچسب زده شود. یک روش دیگر یادگیری ماشین نظارتنشده یا یادگیری خودنظارتی نام دارد، روشی که در آن کامپیوترها بدون اتکا به هیچگونه برچسب بیرونی آموزش میبینند، درست مانند روشی که ما برای پیشبینی شکل یک شی مانند صندلی از زوایای مختلف وقتی به دور آن میگردیم، استفاده میکنیم.

یک انسان این تابلو را حتی با وجود برچسبهای نشاندادهشده، بهعنوان علامت توقف تشخیص میدهد. اما زمانی که یک الگوریتم خودروی خودران برای تشخیص همین تابلو آزمایش شد، از پس انجام آن برنیامد.
یادگیری تقویتشده نوع دیگری از یادگیری ماشین است که در آن مدلها با تعامل مستمر با محیط اطراف خود به کشف توالی اقدامات و بررسی رابطهی علت و معمولی میپردازند تا وظیفهی تعیین شدهی خود را انجام دهند. استفاده از یادگیری تقویتشده باعث شده است تا هوش مصنوعی در انجام بازی گو و بازی کامپیوتری استارکرفت به مهارت بالایی دست پیدا کند.
برای یادگیری مؤثر، ماشینها و البته انسانها باید مهارت تعمیم دادن داشته باشند، یعنی مفاهیم و اصول انتزاعی را از تجربههای خود و دیگران استخراج کرده و در رفتارهای آتی خود به کار گیرند. ملانی میچل از مؤسسهی سانتافه در نیومکزیکو در این مورد میگوید:
بخش بزرگی از هوش به توانایی در استفاده از دانش دیگران و اعمال آن در شرایط مختلف باز میگردد.
بخشی از کار میچل در حوزهی هوش مصنوعی درمورد مطالعهی تشابهات، یعنی پیدا کردن شباهتها بین رشتهای از حروف است. در سال ۲۰۱۹ یکی از محققان گوگل به نام فرانسوا شوله نوعی تست هوش برای ماشینها با نام مجموعه آزمایشهای استدلال و انتزاع طراحی کرد. در این آزمایش کامپیوترها بر مبنای اصولی که از الگوهای نمونه برداشت میکنند، باید الگوهای تصویری دیگری را تکمیل کنند. حل چنین پازلهایی برای انسانها راحت اما برای کامپیوترها چالش برانگیز است.
نکتهی کنایهآمیز این است که بخشی از تفکر انتزاعی ما ریشه در تجربیات فیزیکی دارد. انسانها براساس تجربیات فیزیکی خود به توسعه و استفاده از استعارههای مفهومی مانند مهم یعنی بزرگ یا بحث به معنی رویارویی نظرات متضاد میپردازند، پس شاید اگر بخواهیم هوش جامع مصنوعی نیز از چنین قابلیتی برخوردار باشد باید یک جسم فیزیکی مانند ربات برای هوش مصنوعی مهیا کنیم. محققان پیش از این با ترکیب روشهای یادگیری گفتار و علم رباتیک توانستهاند جهانهای مجازی ایجاد کنند، جایی که در آن رباتهای مجازی با پیروی از دستورالعملها باید یاد بگیرند برای مثال چطور در داخل یک خانه حرکت کنند.
GPT-3 نام یک مدل گفتاری آموزش داده شده است که در سال ۲۰۲۰ توسط آزمایشگاه تحقیقاتی Open AI معرفی شد. عملکرد این ماشین هوش مصنوعی به خوبی نشان میدهد که چرا توسعه توانایی گفتار بدون داشتن جسم فیزیکی و تجریبات فیزیکی ناشی از آن دارای نواقص بنیادی است.
این مدل کامپیوتری میتواند محتواهای معناداری شبیه ادبیات انسانی مانند مقالهها، داستان کوتاه یا شعر تولید کند. اما در یک پیشنمایش سیستم GPT-3 جملهی عجیبی سرهمبندی کرد:
برای پریدن از (شهر) هاوایی به (عدد) هفده به دو رنگینکمان نیاز است.
میچل در این مورد میگوید:
من خیلی با این مسئله کلنجار رفتهام، این ماشین کارهای فوقالعادهای انجام میدهد، اما گاهی اشتباهات احمقانهای هم میکند.
هوش جامع مصنوعی اگر بخواهد به روش طبیعی با انسانها تعامل کند به توسعهی ابعاد حیوانی دیگری از طبیعت انسان مانند احساسات نیز نیاز دارد. احساسات صرفاً واکنشهای غیرمنطقی نیستند. انسانها به منظور پیشبرد انگیزهها و رفتارهایشان در طول تاریخ به ابراز احساسات روی آوردهاند. آنطور که ایلیا سوتسکور، دانشمند ارشد مؤسسهی Open AI میگوید، احساسات نوعی جاذبهی انسانی به منطق میدهد. حتی اگر هوش مصنوعی مانند انسانها احساسات خودآگاهانهای نداشته باشند، ممکن است کدهایی برای ابراز احساساتی شبیه به خشم یا ترس در الگوریتم آنها گنجانده شده باشد. هم اکنون محققان در روش یادگیری تقویتشده عنصری با ماهیت اکتشافی شبیه حس کنجکاوی انسانها را در مدلهای خود میگنجانند.
انسانها در بدو تولد همچون صفحات سفید نیستند، ما در هنگام تولد دارای یک استعداد ازپیشگنجاندهشده در مغزمان برای تشخیص چهره، یادگیری زبان و بازی کردن با اشیا هستیم. سیستمهای یادگیری ماشین نیز باید نوعی ساختار درونی و اولیه برای یادگیری سریع برخی موضوعات مخصوص داشته باشند. اما چه نوع و چه اندازه از این ساختار موضوع بحث داغ بین دانشمندان است. سوتسکور معتقد است:
نحوهی تفکر ما از لحاظ هوشی اغواکننده است، بااینحال ما باید سفیدترین صفحهی ممکن را برای شروع کار داشته باشیم.
بهطور کلی نوعی از ساختار شبکهی عصبی که مورد پسند سوتسکور است ترانسفورمر نام دارد، روشی که در آن هوش مصنوعی بیشتر توجه خود را به روابط مهم بین عناصر ورودی سیستم معطوف میکند. روش ترانسفورمر روی سیستمهایی مانند GPT-3 پیاده شده و برای پردازش تصاویر، موسقی و ویدئو نیز به کار رفته است.

ربات انساننمای iCub به یک ابزار تحقیقاتی در آزمایشگاههای سراسر جهان برای مطالعهی شناخت انسان و هوش مصنوعی تبدیل شده است.
تفکر در مورد تفکر
خود هوش مصنوعی ممکن است به ما در کشف انواع جدیدی از هوش مصنوعی کمک کند. مجموعهای از تکنیکهایی به نام AutoML وجود دارند که در آن از الگوریتمها برای بهینهسازی معماری شبکههای عصبی یا ابعاد دیگر هوش مصنوعی استفاده میشود. هوش مصنوعی همچنین به محققان کمک میکند تا مدارهای مجتمع بهتری طراحی کنند. سال پیش محققان گوگل در ژورنال نیچر گزارش دادند که مدل یادگیری تقویتشدهی آنها در طراحی برخی از ویژگیهای تراشهی شتابدهندهی از خود تیم طراحی گوگل بهتر عمل کرده است.
عصر هوش جامع مصنوعی شاید چند دههی بعد از راه برسد؛ چراکه هنوز ناشناختههای زیادی درمورد هوش مصنوعی و مفهوم هوش بهصورت کلی وجود دارد. میچل در این مورد میگوید:
ما حتی هوش خودمان را بهطور کامل درک نکردهایم، چراکه بخش بزرگی از آن ناخودآگاه است. بههمیندلیل، نمیدانیم که چه کاری برای هوش مصنوعی میتواند سخت یا آسان باشد.
در واقع چیزی که میتواند برای انسانها آسان باشد شاید برای کامپیوترها سخت باشد و برعکس، پدیدهای که به آن پارادوکس موراوک میگویند. مواروک، دانشمند فناوری رباتیک در سال ۱۹۸۸ نوشت:
در مقام قیاس بهراحتی میتوان نشان داد که کامپیوترها در انجام کارهایی مانند حل مسئله یا انجام آزمایش هوش یا شطرنج بازی کردن که تنها از دست انسانهای بالغ برمیآید مهارت بالایی از خود نشان میدهند، اما آموزش مهارتهای یک کودک یک ساله مانند تواناییهای ادراک و حرکتی به آنها بینهایت دشوار یا غیرممکن است.
در واقع میتوان گفت نوزادان بالفطره به نوعی باهوش هستند. پریکاپ در این مورد معتقد است:
برای دستیابی به هوش جامع مصنوعی ما باید به درک بیشتری از هوش انسانی و بهطور کلی مفهوم هوش دست پیدا کنیم.
تورینگ در زمان خود نیز بین مفهوم هوش بهطور کلی و هوش انسانی تفاوت قائل میشد. او در سال ۱۹۵۰ در مقالهی خود در مورد آزمایش تقلید نوشت:
ممکن است ماشینها کاری را که ما از آن بهعنوان فکر کردن نام میبریم، انجام ندهند؛ اما به چه کاری میتوان گفت عمل غیرانسانی؟
منظور تورینگ بهتعبیر سادهتر این بود: لازم نیست مانند یک انسان فکر کنید تا از شما بهعنوان نابغهی باهوش یاد شود. هوشی که انسانها ازطریق تفکر و اعمالشان نشان میدهند تنها یکی از انواع هوش میتواند باشد.
کلنجار با ارزشهای اخلاقی
آیزک آسیموف در داستان کوتاهی که در ۱۹۴۲ نوشته بود از زبان یکی از کارکترهای داستان خود به سه قانون بنیادی که رباتها باید از آن تبعیت کنند اشاره میکند. رباتها باید از آسیب رساندن به انسانها پرهیز یا از رسیدن آسیب به انسانها جلوگیری کنند، باید از دستورها پیروی کنند و باید از خودشان محافظت کنند. رباتها باید این قوانین را با توجه به درجهی اهمیت آنها رعایت کنند به گونهای که عمل به یک قانون ناقض قانونهای مقدم بر آن نباشد.
شاید با خواندن داستانهای علمی تخیلی رباتهای شروری را تصور کنید که به اختیار خود تصمیم به نابودی انسانها میگیرند؛ اما در دنیای واقعی کامپیوترها به شکلهای دیگری روی زندگی انسانها تأثیر میگذارند. به جای رباتهای انساننمای قاتل، ما الگوریتمهایی داریم که اشتباهات آنها تبدیل به تیتر اخبار میشود. اکنون که کامپیوترها وارد جنبههای بیشتری از زندگی انسانها میشوند وقت آن است در مورد نوع سیستمهای کامپیوتری که باید ساخته و به کار گرفته شوند تصمیم بگیریم، و مهمتر از آن، در مورد مرجع تصمیم گیرنده و نظارتکننده بر این موارد نیز فکر کنیم.
در اینجا وارد دنیای اخلاقیات میشویم که شاید از مسیر و هدف اصلی علوم ریاضی و مهندسی دور به نظر برسد. اما تصمیمگیری در مورد سؤالهایی که باید در مورد جهان بپرسیم و ابزارهایی که باید بسازیم همیشه به ایدهها و بایدها و نبایدهای اخلاقی جامعه بستگی داشته است. مطالعه در مورد یک موضوع علمی محض مانند برهمکنشهای ذرات زیراتمی به وضوح تأثیر بسزایی در صنعت تولید انرژی یا ساخت سلاح جنگی دارد. باربارا گروس، دانشمند علوم کامپیوتر از دانشگاه هاروارد میگوید:
این یک حقیقت بنیادی است که سیستمهای کامپیوتری از لحاظ ارزشی بیطرف نیستند، وقتی یک مدل کامپیوتری توسعه داده میشود برخی از ایدههای ارزشی از طرف سازندگان بهطور ناخودآگاه وارد سیستم میشود.
یکی از موضوعاتی که توجه دانشمندان و جامعهشناسان را به خود جلب کرده بحث بیطرفی و تبعیض است. مؤسسه و نهادهای زیادی از الگوریتمها بهطور فزاینده برای اطلاعرسانی یا تصمیمگیری در مورد استخدامهای شغلی، پذیرش در دانشگاه، اعطای وام یا آزادی مشروط استفاده میکنند. حتی اگر یکجانبهگرایی و غرضورزی سیستمهای کامپیوتری از انسانها کمتر باشد، ممکن است بخش مشخصی از جامعه مورد بیعدالتی قرار بگیرد، نه به این دلیل که بیعدالتی و تعصبگرایی در طراحی این سیستمها به صورت عامدانه گنجانده شده است، بلکه به این دلیل ساده که مدلهای کامپیوتری ممکن است با دادههایی از این دست آموزش دیده باشند. برای مثال مدلهای کامپیوتری میتوانند رفتار مجرمانهی یک فرد در آینده را براساس رفتارها و بازداشتهای قبلی او پیشبینی کرده و در مورد آزادی مشروط او تصمیم بگیرند، درحالیکه گروههای مختلفی از جامعه بهمیزان متفاوتی در مورد یک مقدار مشخصی از جرم بازداشت میشوند.
چیزی که باعث سردرگمی بیشتر میشود این است که تعاریف مختلفی برای بیطرفی و عدالت وجود دارد، مانند نرخ مثبت کاذب یا نرخ منفی کاذب بین گروهها. برای مثال چند سال پیش یک محقق در کنفرانسی ۲۱ تعریف مختلف برای عدالت برشمرد. بنابراین جای تعجب نیست که تصمیمگیری در مورد این که چه چیزی عادلانه یا غیرعادلانه است همیشه محل مناقشه باشد. در یک مطالعه محققان نشان دادند که برآورده کردن پیشنیازهای سه تعریف مختلف از عدالت به صورت همزمان از لحاظ ریاضی غیرممکن است.
برآورده کردن سه تعریف مختلف از عدالت به صورت همزمان از لحاظ ریاضی غیرممکن است
موضوع مهم دیگر بحث حریم خصوصی و سیستمهای پایش افراد است، اهمیت این موضوع در سالهای اخیر بیشتر شده؛ چراکه اکنون کامپیوترها نسبت به گذشته به شکل غیرقابل تصوری اطلاعات زیادی را جمعآوری و طبقهبندی میکنند. دادههای مربوط به نحوهی رفتار در فضای اینترنت میتواند به مدلهای کامپیوتری کمک کند تا رفتارهای خصوصی از جمله رفتارهای جنسی ما را پیشبینی کنند. همچنین فناوری تشخیص چهره کامپیوترها را قادر میکند تا افراد را در دنیای واقعی تعقیب کنند، موضوعی که میتواند مزایایی مانند کمک به شناسایی یک مجرم توسط پلیس یا معایبی مانند نقض حقوق شهروندی توسط حکومتهای خودکامه داشته باشد. از طرف دیگر فناوری نوظهور نوروتکنولوژی در حال آزمایش روشهایی برای برقراری ارتباط مستقیم بین مغز و کامپیوترها است. امنیت شخصی و اجتماعی موضوعی است که بهطور مستقیم با حریم خصوصی ارتباط دارد. هکرها اکنون میتوانند دامنهی وسیعتری از سیستمهای کامپیوتری، از ضربانسازهای قلبی گرفته تا خودروهای خودران را هدف حمله قرار دهند.
کامپیوترها همچنین میتوانند موجب افزایش فریبکاری در فضای اینترنت شوند. هوش مصنوعی میتواند محتواهای ساختگی تولید کند؛ از جمله تصاویر و ویدیوهایی که بسیار شبیه به واقعیت هستند. از مدلهای کامپیوتری گفتاری ممکن است برای ساخت اخبار جعلی و محتواهای تهییجکنندهی گروهای تندرو استفاده شود. شبکههای عصبی مولد که نوعی از سیستمهای یادگیری عمیق هستند میتوانند محتواهای صوتی و تصویری شبیه واقعیت یا دیپفیک تولید کنند، فیلمها و تصاویر ساختگی که در بیشتر موارد افراد مشهور را در انجام کارهای عجیب و غریب نشان میدهد.
در محیط شبکههای اجتماعی نیز نگرانیهایی در مورد دوقطبی شدن نظرات سیاسی و اجتماعی افراد جامعه وجود دارد. بهطور کلی الگوریتمهای پیشنهاددهندهی محتوا بهجای گفتمان مدنی بهدنبال درگیری بیشتر افراد در محیط اینترنت هستند تا ازطریق تعامل بیشتر با پلتفرمها، سود تبیلغاتی بیشتری نصیب شرکتها شود. رباتهای مشاور نوعی از چتباتها هستند که برای دادن مشاورهی اقتصادی و پیشنهاد خرید محصولات برای افراد توسعه داده شدهاند. این باتها ممکن است به نحوی از نیازهای ضروری و غیرضروری افراد آگاه شده و آنها را به خرید بیشتر محصولات نامربوط و غیرضروری تشویق کنند.
برخی کشورها به توسعهی سلاحهای خودهدایتشونده روی آوردهاند، این سلاحها که براساس هوش مصنوعی کار میکنند بهصورت بالقوه باعث کاهش تلفات غیرنظامی شده و قدرت تصمیمگیری سریعتری نسبت به انسانها برای شروع مخاصمات مؤثر دارند. قرار دادن اسلحه و موشک در دست هوش مصنوعی نگرانیهایی از جنس فیلمهای علمی تخیلی ترمیناتور با موضوع از بین بردن نسل انسانها ایجاد میکند.
شاید هوش مصنوعی نیت بدی در پشت تصمیمات خود نداشته باشد و فقط به اشتباه اینطور استدلال کند که حذف نوع بشر از روی زمین، بهترین راه برای خلاص شدن از شر رفتارهای سرطانمانندی که انسانها عامل آن هستند؛ رفتارهایی مانند تخریب زمین و به خطر انداختن حیات تمام موجودات زنده یا امکان استفاده ازسلاحهای هستهای. اما آسیبهای کوتاهمدت سیستمهای هوش مصنوعی خودمختار در دنیای واقعی شکل و شمایل آخرالزمانی کمتری دارند، مانند سقوط ناگهانی سهام شرکتها در پی تصادفات خودروهای خودران یا قیمتگذاری عجیب روی کتابهایی که در آمازون به فروش میرسد. اما اگر تصمیمگیری در مورد مسائل مرگ و زندگی برعهدهی هوش مصنوعی گذاشته شود، ممکن است با مسئلهی اخلاقی مشهور تراموا روبهرو شویم، یعنی تصمیمگیری در مورد اینکه چه کسی یا چه چیزی باید قربانی شود، در شرایطی که ممکن نیست هر دو طرف پیروز شوند. در اینجا دوباره وارد حیطهی قوانین آسیموف میشویم.
//
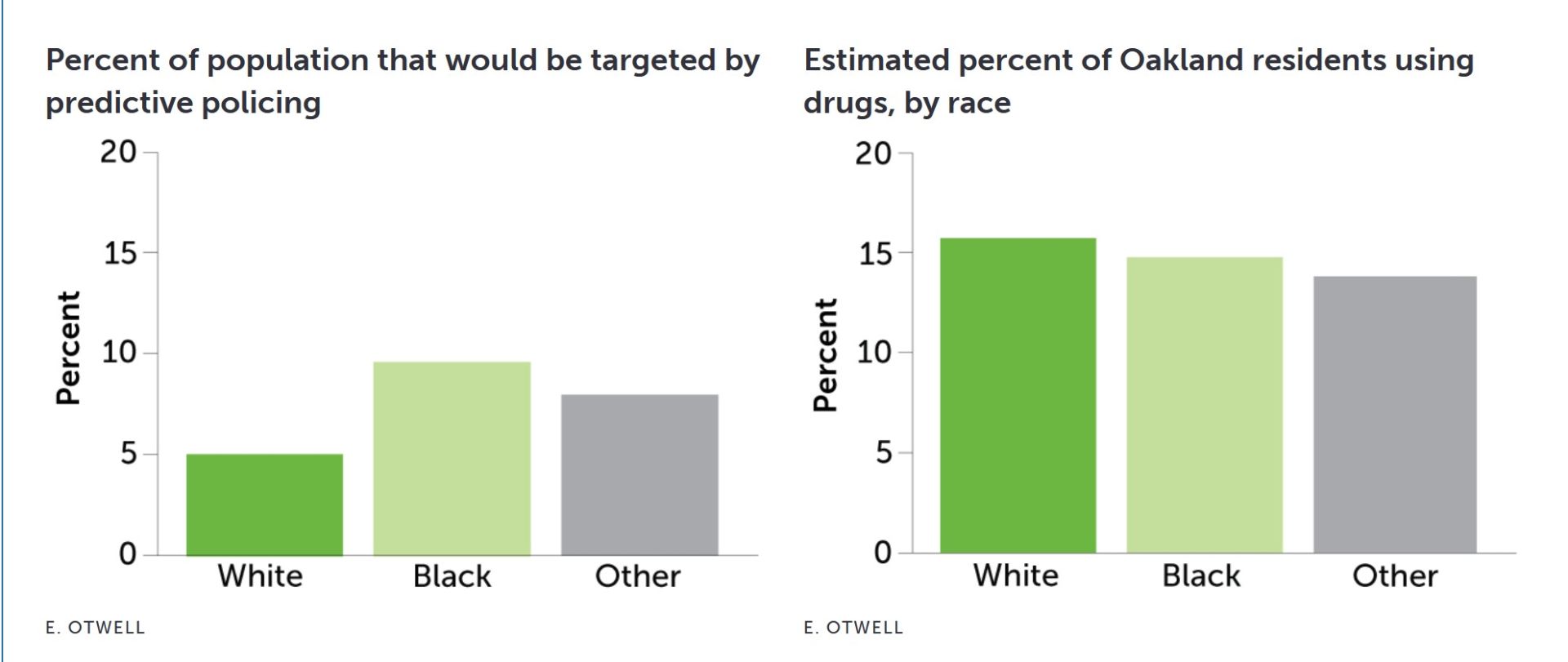
یک الگوریتم پلیسی پیشبینیکننده که در اوکلند کالیفرنیا آزمایش شد، سیاهپوستان را تقریباً دو برابر سفیدپوستان (سمت چپ) هدف قرار میدهد. این در حالی است که حتی دادههای مربوط به همان دورهی زمانی، یعنی سال ۲۰۱۱، نشان میدهد که مصرف مواد مخدر در بین گروههای نژادی تقریباً معادل بوده است (سمت راست) .
بنابراین میتوان گفت در حال حاضر نگرانیهای زیادی در مورد هوش مصنوعی و مسئولیتهایی که باید به آن سپرده شود وجود دارد. راسل از دانشگاه کالیفرنیا میگوید:
سلاحهای خودهدایتشوندهی کشنده موضوعی جدی و عاجل است؛ چراکه ممکن است تاکنون جان مردم به خاطر تصمیمات هوش مصنوعی به خطر افتاده باشد و این طور که از شرایط برمیآید وقوع یک فاجعهی بزرگ حتمی است و تنها مسئلهی زمان وقوع آن مطرح است. بیعدالتی و اعتیاد به شبکههای اجتماعی و گرایش به تندروی در فضای مجازی نیز مثالهای آشکاری از بیتوجهی ما در توجه به ارزشهای اخلاقی هنگام توسعهی الگوریتم هوش مصنوعی است. این مشکلات مانند هشدارهای اولیه هستند که به ما نشان میدهند چطور ممکن است همه چیز بهراحتی و سرعت از کنترل خارج شود.
همچنین درمورد نحوهی مدیریت تکنولوژی در جامعه نیز سوالات قانونی، سیاسی و اجتماعی مطرح است. وقتی سیستم هوش مصنوعی باعث آسیب به افراد میشود چه کسی باید مسئولیت آن را برعهده گیرد؟ چراکه پیش از این در مواردی خودروهای خودران باعث تصادف و مرگ افراد شدهاند. چطور میتوانیم از دسترسی منصفانهی همهی افراد جامعه به ابزار هوش مصنوعی و بهرهمندی عادلانه از فواید استفاده از آن مطمئن شویم و اطمینان حاصل کنیم که الگوریتمهای هوش مصنوعی در تصمیمگیریهای خود علیه هیچ شخص یا گروه جمعیتی تبعیض قائل نمیشوند؟ چگونه ادامهی روند اتوماسیون در محیطهای کاری روی نرخ اشتغال تأثیر خواهد گذاشت؟ آیا قادر به کنترل اثرات مخرب دیتاسنترها بر محیط زیست ازطریق مصرف برق زیاد و به تبع آن تولید مقدار زیادی گازهای گلخانهای خواهیم بود؟ الگوریتمهای توضیحپذیر نسبت به شبکههای عصبی که تنها بر مبنای یادگیری عمیق توسعه داده شدهاند و مانند جعبه سیاه عمل میکنند، سطح عملکرد پایینتر و پیشبینيهای ضعیفتری دارند، بااینحال آیا ما باید به خاطر اعتماد بیشتر و قابلیت اشکالزدایی آنها ترجیحا از چنین الگوریتمهای ضعیفتری استفاده کنیم؟
چه باید کرد؟
مایکل کرنز، دانشمند علوم کامپیوتر در دانشگاه پنسیلوانیا که کتاب الگوریتم اخلاقی را در سال ۲۰۱۹ به رشتهی تحریر درآورده برای توضیح این مشکل از یک طیف مدیریتپذیری استفاده میکند. در یک سمت این طیف روش حریم خصوصی تفاضلی وجود دارد که از آن با نام محرمانگی آماری نیز یاد میشود. در این راهکار میتوان اطلاعات مربوط به افراد مانند اطلاعات پزشکی آنان را با محققان به منظور انجام مطالعات علمی به اشتراک گذاشت بدون این که حریم خصوصی افراد نقض شده و اطلاعات شخصی آنان فاش شود. در این روش میتوان بهصورت ریاضی ضمانتهایی برای حفظ اطلاعات شخصی افراد به هنگام اشتراکگذاری اطلاعات ارائه کرد.
موضوع عدالت در نگاه هوش مصنوعی برای همیشه محل تضاد و بحثهای نگرشی خواهد بود
در جایی در وسط این طیف موضوع پرهیز از تبعیض در سیستمهای یادگیری ماشین قرار دارد. محققان با تغییر یا حذف دادههای تبعیضآمیزی که برای آموزش شبکههای عصبی به کار میرود موفق به توسعهی روشهایی برای افزایش عدالت و دوری از تبعیض در سیستمهای کامپیوتری شدهاند، بهنحوی که خسارت مالی ناشی از کاهش سوددهی الگوریتمها به حداقل مقدار ممکن برسد. بااینحال برخی از انواع عدالت در جنبههای مختلف یک موضوع برای همیشه در تضاد با یکدیگر خواهند بود و روشهای ریاضی محض نمیتواند به ما در تصمیمگیری کمک کند.
توضیحپذیری در سمت دیگر این طیف قرار دارد. برخلاف عدالت و دوری از تبعیض که تا حد زیادی به روشهای مختلف ریاضی میتوان به تحلیل آن پرداخت، تعریف قابلیت توضیحپذیری به روش ریاضی کاری دشوار است. کرنز در این مورد میگوید:
احساس میکنم تاکنون یک تعریف خوب در این مورد ارائه نشده است. فرض کنید الگوریتمی دارید که براساس شبکهی عصبی آموزش داده شده و در مورد ارائه وام به افراد تصمیم میگیرد. اگر کسی بپرسد چرا به من وام تعلق نگرفته نمیتوانید توضیح دقیقی بدهید یا توضیحی که داده میشود زیاد اصولی به نظر نمیرسد.
در نهایت هرچه که باشد توضیحی که مخاطب شما آن را درک نکند یک توضیح خوب نیست. بنابراین اندازهگیری میزان موفقیت چنین الگوریتمی، به هر شکلی که موفقیت را تعریف کنید، نیاز به مطالعه آماری روی کاربران دارد.

وجود سلاحهای مرگبار خودمختار مانند پهپادهای STM Kargu ساخت ترکیه، باعث شده است تا کارشناسان خواستار ممنوعیت وسایلی شوند که میتوانند بدون دخالت انسانی حملاتی را انجام دهند
چیزی مثل قوانین سهگانهی آسیموف بهتنهایی نمیتواند از ما درمقابل آسیب رباتها حفاظت کند، بهخصوص آسیبهایی که در فرایند تلاش برای کمک به انسانها بهصورت ناخواسته از طرف رباتها وارد میشود. حتی اگر لیست آسیموف میلیونها قانون دیگر را شامل میشد، جملاتی که قانون با آنها نوشته شده هیچگاه بهطور صددرصد حق مطلب را ارائه نمیکند و نمیتواند روح آن را توضیح دهد. یکی از راهحلهای ممکن برای پاسخ به این چالش استفاده از یادگیری تقویتشدهی معکوس است، روشی که کامپیوترها میتوانند با رمزگشایی از رفتار ما به ارزشهای اخلاقی که انسانها به آن پایبندند دست پیدا کنند.
مسیر پیش روی مهندسان برای بهبود مسیر آینده
در سال ۱۹۵۰ آسیموف در داستان کوتاه تخاصم اجتنابپذیر، چیزی نوشت که بعدا به قانون صفرم آسیموف معروف شد، قانونی که پیروی از آن مقدم بر تمام قوانین دیگر است:
یک ربات نباید با اعمال خود به انسانها آسیب برساند یا با بیعملی باعث آسیب رسیدن به انسانها شود.
در دنیای امروزی میتوان این قانون را با جایگزین کردن کلمهی دانشمندان علوم رباتیک به جای کلمهی ربات به کار برد. در بسیاری از موارد دانشمندان علوم کامپیوتر سعی دارند با توسعهی ابزارها و فناوریهای جدید از رسیدن آسیب به انسانها جلوگیری کنند، بااینحال آنها به شکل فعال به تبعات اجتماعی کارهای علمی خود توجه نمیکنند. مارگارت میچل از گردانندگان گروه اخلاق هوش مصنوعی در گوگل که اکنون در زمینهی مشاورهی اخلاقی به شرکتهای فناوری فعالیت میکند، معتقد است انفعال دانشمندان در این زمینه عملا باعث آسیب به انسانها شده است.
گروس از دانشگاه هاروارد میگوید یکی از مشکلات بزرگ پیش روی فناوری هوش مصنوعی این است که بسیاری از دانشمندان در زمینهی اخلاقِ فناوری آموزشهای لازم را ندیدهاند. بااینحال گروس در تلاش برای تغییر شرایط است. او به همراه فیلسوف آلیسون سیمونز برنامهای با نام اخلاق نهادینه را در دانشگاه هاروارد مدیریت میکند که هدف از آن قرار دادن آموزشهای فلسفی در کنار دروس علوم کامپیوتر است. در این برنامهی درسی به دانشجویان علاوه بر مهارتهای کامپیوتری در زمینهی فلسفهی اخلاق، حریم خصوصی، تبعیض و اخبار جعلی نیز آموزشهایی داده میشود. این برنامه اکنون در دانشگاههای استنفورد، تورنتو و مؤسسهی تحقیقاتی ماساچوست نیز ارائه میشود.
گروس در این مورد توضیح میدهد:
ما سعی میکنیم دانشجویان را وادار به تفکر درمورد ارزشهای اخلاقی و مصالحهی اخلاقی کنیم، این که با در نظر گرفتن یک ارزش اخلاقی مشخص در کار خود چه چیزی به دست آورده یا از دست میدهید.
گروس در این مسیر با دو نکتهی قابلتأمل مواجه شده است. نکتهی اول این است که دانشجویان درمورد موضوعاتی که جوابهای ساده و سرراست درست و غلط ندارند و پاسخ دادن به آنها نیازمند بحث درمورد تصمیمات بهخصوصی است به مشکل برمیخورند، و نکتهی دوم این که دانشجویان با وجود سرخوردگی تا چه اندازه به چنین موضوعات چالشبرانگیزی اهمیت میدهند.
راهکاری دیگری که برای آگاهسازی دانشمندان در مورد تأثیرات کارهای علمی آنان وجود دارد توسعهی همکاری بینرشتهای است. میچل معتقد است:
علوم کامپیوتر باید به جای اتکا به ریاضی بهعنوان تنها راهحل لازم و کافی، به رشتههای علمی دیگر نظیر علوم اجتماعی و روانشناسی نیز توجه کند. دانشمندان علوم کامپیوتر باید با کارشناسان این رشتهها نیز همکاری کنند.
از طرف دیگر کرنز میگوید دانشمندان باید مهارتهای فنی خود را با نهادهای قانونی، سیاستمداران و وکیلها در میان بگذارند. در غیر اینصورت سیاستهای اتخاذ شده در این زمینه به اندازهای مبهم خواهند بود که تقریباً بلااستفاده بمانند. در غیاب تعریفهای مشخصی از عدالت و حریم خصوصی که بهطور واضح در متن قانون آمده باشند، شرکتها میتوانند به جای دیگران براساس نیازها و سوددهی خود تصمیمگیری کنند.
وقتی صحبت از تأثیر یک ابزار جدید بر جامعه میشود، بهترین کارشناسانی که میتوانند در مورد معایب و مزایای آن ابزار قضاوت کنند خود افراد جامعه هستند. گروس حامی مشورت با گروههای جمعیتی متنوع است. تنوع نژادی و جمعیتی میتواند به انجام مطالعات رفتار جمعی و همچنین تحقیقات تیمهای علمی کمک کند. گروس اضافه میکند:
اگر در اتاق فردی پیدا نمیکنید که به شکل متفاوتی از شما فکر کند به این معنی نیست که نظرات متفاوتی وجود ندارند، بلکه به این معنی است که شما تفاوتها را نمیبینید. اگر کسی بگوید که شاید همهی افراد بیمار از گوشی هوشمند استفاده نمیکنند، آنوقت در طراحیهای خود مثل گذشته فکر نخواهید کرد.
بهباور مارگارت میچل بزرگترین چالش به موضوع تنوع جمعیتی برمیگردد. او میگوید:
مشکل از آنجا آغاز میشود که از همان شروع کار نمایندهی همهی گروههای جمعیتی دور میز حضور نداشته باشند. همهی مشکلات دیگر از اینجا نشأت میگیرد.