بررسی فناوریهای بهکاررفته در نسل جدید پردازندههای گرافیکی انویدیا؛ RTX 2080 Ti

زمان آن رسیده که نگاهی عمیق به پردازندههای سری RTX-20، نسل جدید پردازندههای گرافیکی انویدیا بیندازیم تا ببینیم شرکت تایوانی برایمان چه چیز به ارمغان آورده است.
این پردازندهها اولین سری هستههای گرافیکی هستند که توانایی اجرای رهگیری پرتو (یک فناوری که با دنبال نمودن خط نور تأثیر نور بر اشیاء و محیط را بهصورت دقیق رندر میکند) را به صورت بلادرنگ (Real-Time) دارا هستند. این قابلیت با بهرهگیری از هستههای جدید RT و Tensor امکانپذیر شده است. اما علاوه بر اینها پردازندههای گرافیکی جدید انویدیا بهگونهای طراحی شدهاند که کارایی و گرافیک بازیهای کنونی را نیز بهصورت محسوسی بهبود ببخشند تا لذت بازی با نرخ فریم تصویرهای بالا و رزولوشن 4K را به کابران هدیه دهند.

انویدیا در مراسم رونمایی از GeForce RTX 2080 Ti اعداد و ارقام متنوعی از بهبودهای صورتگرفته روی این پردازنده ارائه داد که شامل افزایش پهنای باند حافظه، فرکانس کاری، تعداد هستههای CUDA و... میشود. ما میخواهیم در این بررسی به اعماق پردازنده گرافیکی جدید انویدیا برویم و تغییرات معماری نسل Turing نسبت به Pascal را بررسی کنیم. همچنین به امکانات و ابزارهای جدید انویدیا میپردازیم که قدرت پردازندههای جدید را باز هم بیشتر میکند و میتواند توانایی پردازش هوش مصنوعی ابررایانه Saturn V را به کارتهای گرافیک بیاورد.
مرور کلی پردازندههای Turing انویدیا
ابتدا با هم مشخصات کلی پردازنده گرافیکی TU102 بهکاررفته در GeForce RTX 2080 Ti را از زبان خود انویدیا مرور کنیم:
پردازنده TU102 از ۶ خوشه پردازش گرافیکی (GPCs)، ۳۶ خوشه پردازشی بافت (TPCs)، ۷۲ پردازنده چندگانه استریمینگ (SMs) تشکیل شده است. هر یک از خوشههای پردازش گرافیکی از یک موتور شطرنجی (Raster Engine) جانبی و ۶ پردازنده بافت - که هریک دو پردازنده استریمینگ دارند - تشکیل شده است. هر موتور استریمینگ نیز دارای ۶۴ هسته CUDA، هشت هسته Tensor با ۲۵۶ کیلوبایت ثبات (Register)، چهار واحد بافت و ۹۶ کیلوبایت حافظه مشترک سطح یک (L1) است که البته این حافظه میتواند با توجه به میزان فشار پردازشی مورد نظر روی مقادیر بیشتر یا کمتر تنظیم شود.
در کنار هر پردازنده استریمینگ یک هسته پردازشی RT وجود دارد که مجموعا میشود ۷۲ هسته. هر چه به سمت مدلهای پایینتر پردازندههای سری ۲۰ برویم، تعداد این هستهها کمتر میشود. برای مثال در RTX 2080 تعداد ۴۶ و در RTX 2070 تعداد ۳۶ هسته RT خواهید یافت.
حالا که این اعداد و ارقام را خواندید، اندازه و قدرت پردازندههای جدید گرافیکی انویدیا باید برایتان قابل توجه باشد. مساحت سیلیکون بهکاررفته در این پردازنده ۷۵۴ میلیمتر مربع است که نسبت به نسل قبلی یعنی RTX 1080 Ti با مساحت ۴۷۱ میلیمتر مربع بسیار بزرگ به حساب میآید.
بهبود حافظه و Shading
میخواهیم قبل از اینکه به بررسی هستههای Tensor و RT برسیم، به بهبودهای صورتگرفته در عملکرد حافظه نسل جدید بپردازیم.
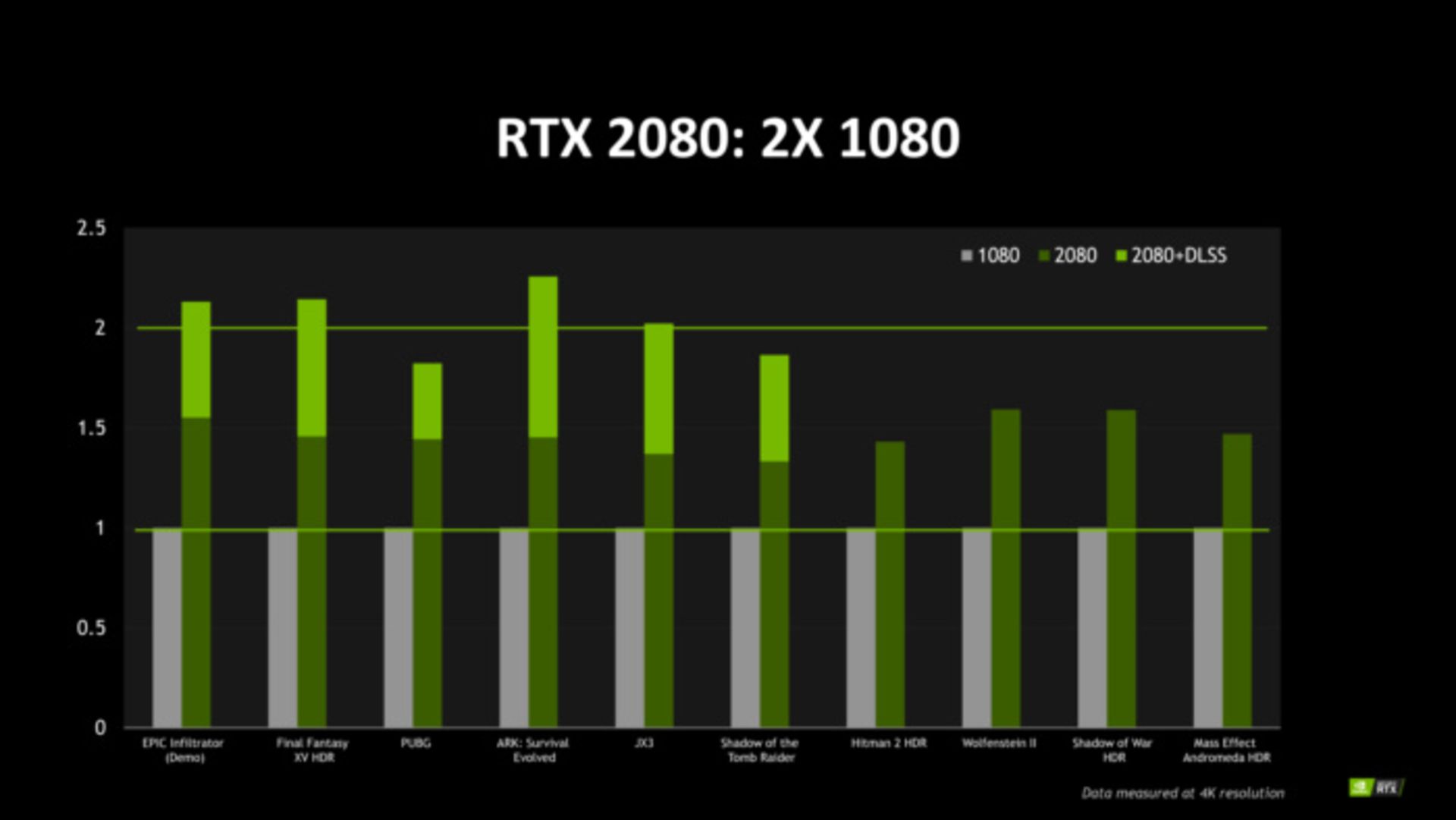
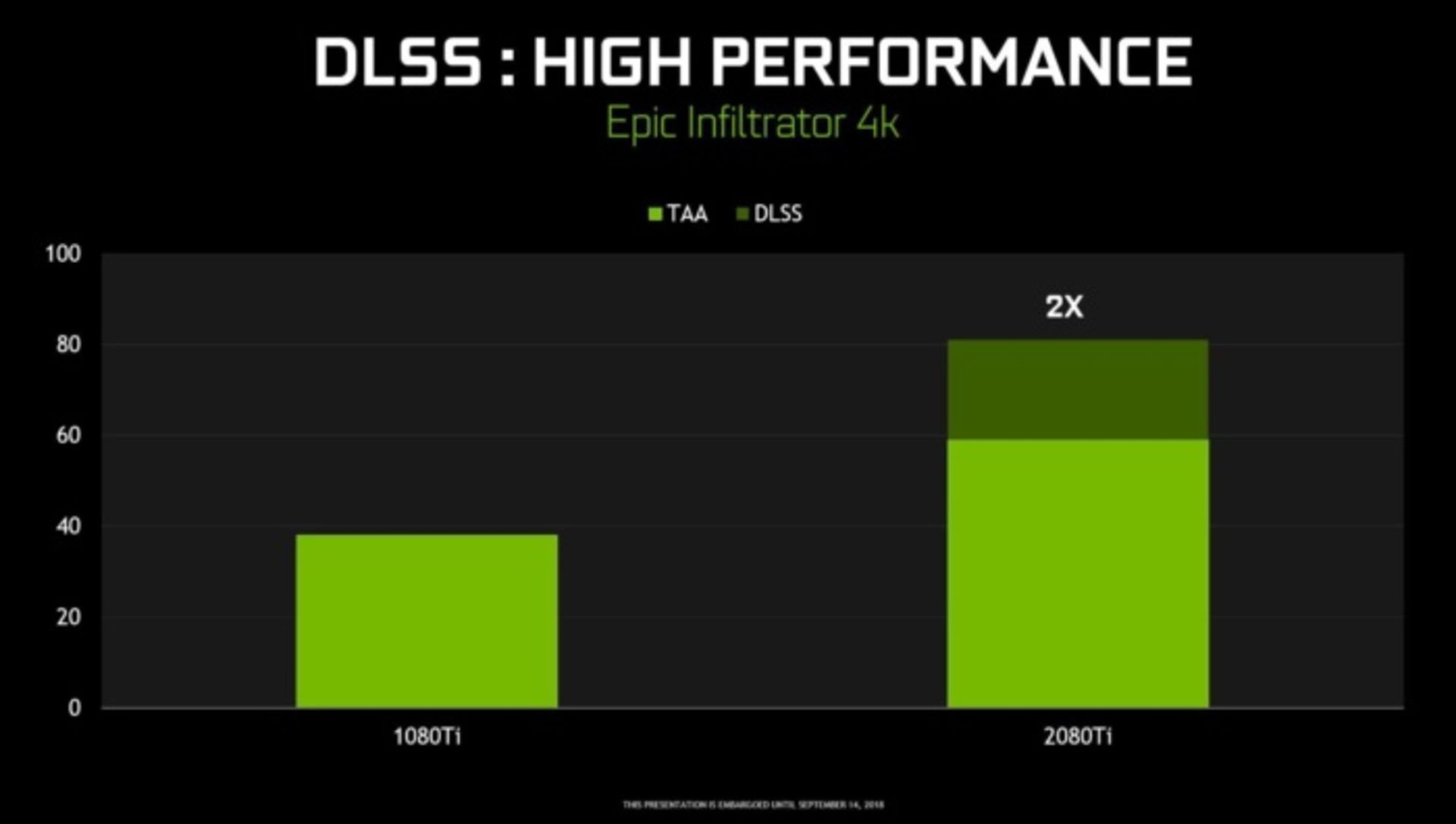
انویدیا مدعی است که GeForce RTX 2080 میتواند در بازیهای معمولی تا ۵۰ درصد بهتر از GTX 1080 عمل کند. بسیاری از مقایسهها درمورد بازیهایی انجام شده که دارای HDR هستند و پردازندههای سری GTX 10 را به زحمت میاندازند. انویدیا میگوید پردازندههای جدید RTX 2080 در بازیهایی که از فناوری DLSS پشتیبانی میکنند، عملکردی تا دو برابر بهتر از خود نشان میدهند و میتواند تا ۶۰ فریم بر ثانیه را برای بهترین بازیها با رزولوشن 4K و HDR خروجی بدهد.

البته باید این ادعا را در عمل نیز مورد آزمایش قرار داد. این شرکت مقایسهای در مورد برتری نسل جدید با نسل قبلی در بازیهایی که HDR ندارند انجام نداده است و معلوم نیست در شرایط عادی پردازندههای سری RTX 20 چقدر نسبت به نسل قبلی خود برتری داشته باشند. همچنین انویدیا مشخص نکرده در آزمایشهای انجام داده برای نشان دادن قدرت پردازشی کارت گرافیک جدید تنظیمات گرافیکی بازیها را در چه وضعیتی قرار داده است.
از آنجایی که میدانیم احتمالا سری جدید RTX 20 در شرایط معمولی کاراییاش حداقل برابر با نسل قبلی خواهد بود در حالی که ۲۰ درصد هستههای CUDA کمتری دارد، بنابراین هستههای CUDA بهبودهایی در عملکرد خود داشتهاند.
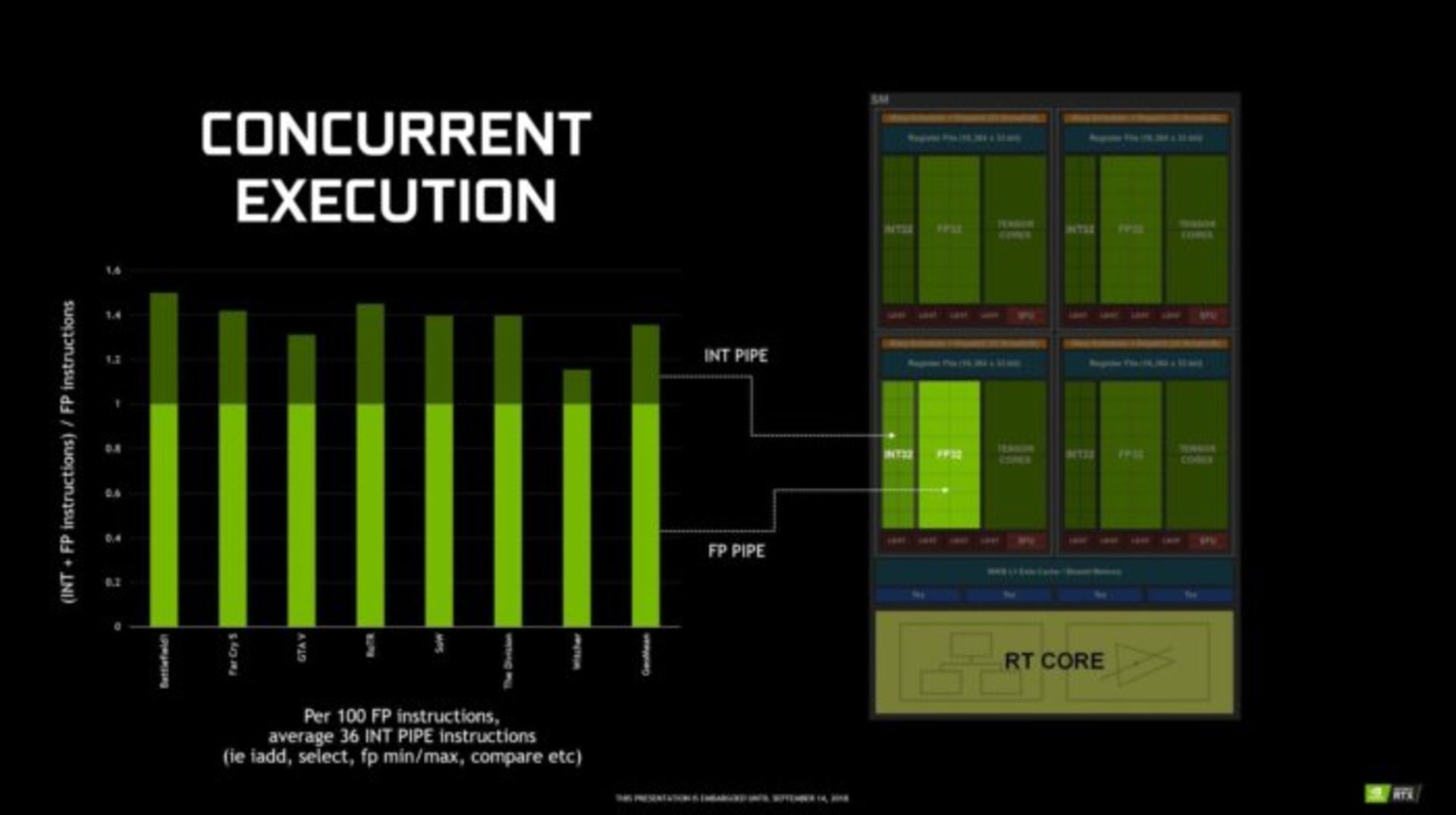
همهچیز آنقدرها هم جدید نیست. انویدیا در سری جدید پردازندههای گرافیکیاش از همان پردازندههای چندگانه (MultiProcessor) به کار رفته در نسل قبلی (با اندکی بهبود) استفاده کرده است. در پس این پردازنده، این شرکت همچنین یک پایپلاین اعداد صحیح جدید (از نوع INT32) را در کنار پایپلاین قبلی از نوع اعداد شناور (FP32) که برای Shading مورد استفاده قرار میگیرید اضافه کرده است.
آنطور که انویدیا میگوید هنگام اجرای بازیها، به ازای هر ۱۰۰ عمل اعداد شناوری به صورت میانگین ۳۶ و گاهی تا ۵۰ عمل اعداد صحیح پردازش میشود. بنابراین اضافه کردن یک خط پردازشی اعداد صحیح میتواند مسئولیت پردازش این عملیات به صورت موازی با خط پردازش شناور بر عهده بگیرد. بنا به گفته Jonah Alben معاون مهندسی پردازندههای گرافیکی انویدیا، این امر موجب میشود بهبود بزرگی در سرعت پردازش اتفاق بیفتد.
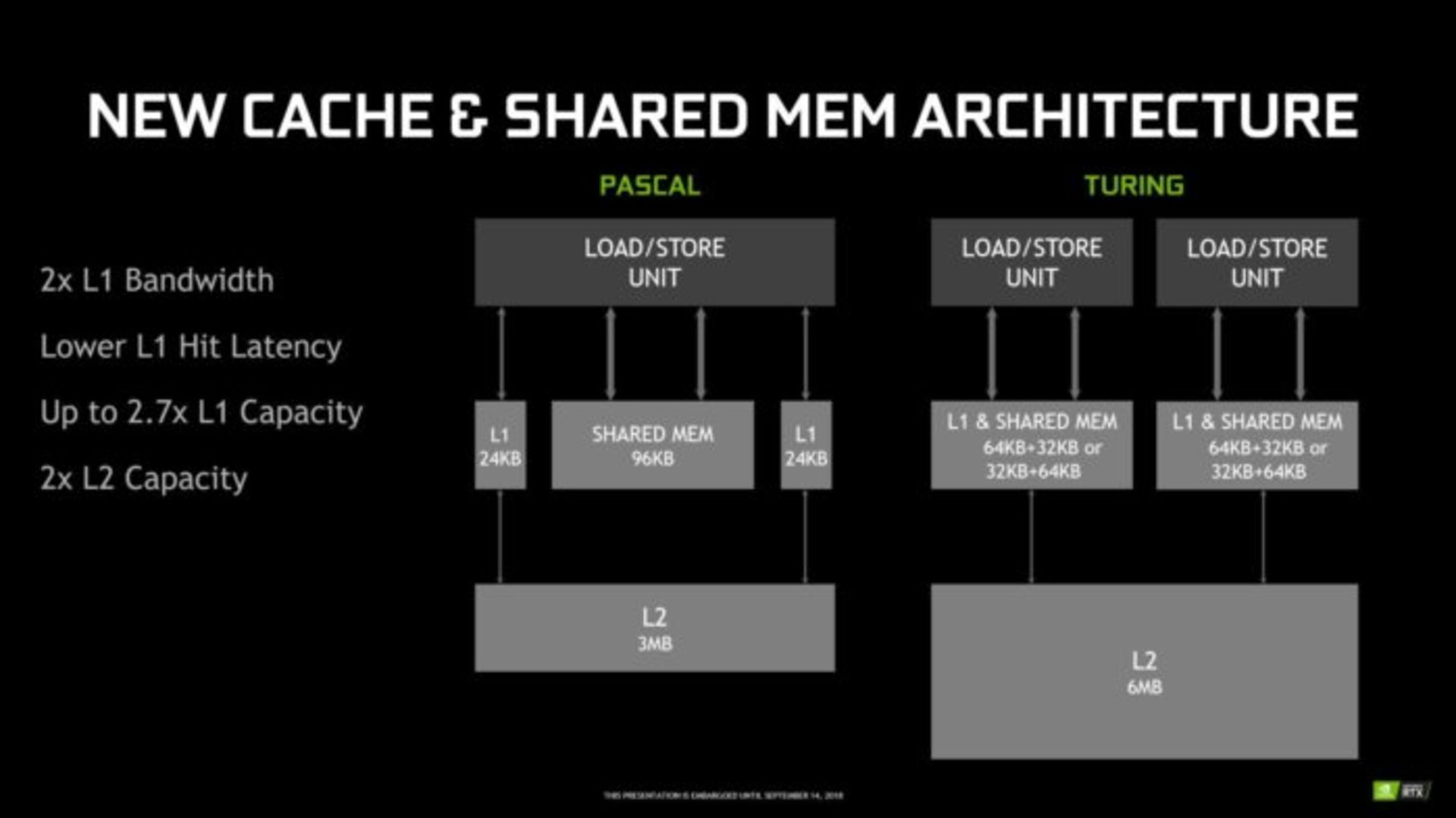
انویدیا همچنین نحوه ارتباط و بهکارگیری پردازندههای چندگانه با حافظههای کش را دگرگون کرده است. در معماری تورینگ، SMها از یک حافظه یکنواخت کش سطح ۱ (L1) و به صورت اشتراکی استفاده میکنند که توسط یک حافظه کش سطح ۲ با ظرفیت دو برابر معماری پاسکال پشتیبانی میشود. این به معنی داشتن حافظه کش سطح یک با ظرفیت سه برابری و پهنای باند دو برابری نسبت به نسل قبلی GTX 10 است.
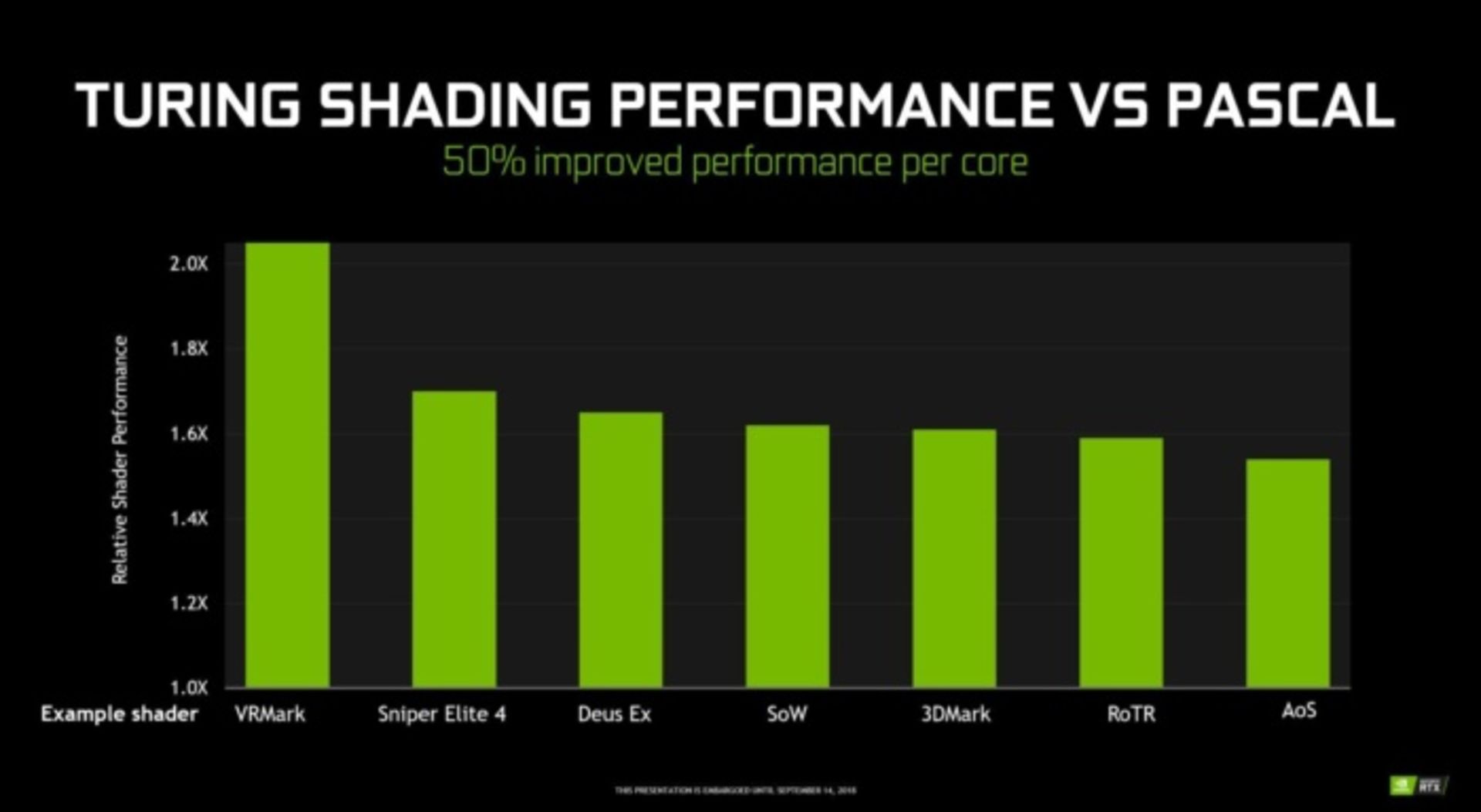
به همه اینها، ادعای انویدیا مبنی بر اینکه پردازندههای تورینگ عملیات معمول Shading را ۵۰ درصد بهتر از معماری پاسکال انجام میدهند را نیز اضافه کنید. این امر یک دستاورد بسیار عظیم در معماری جدید به حساب میآید. البته همانطور که در نمودار دیده میشود بهبود صورت گرفته در هر بازی ممکن است بسته به نوع و نحوه استفاده از منابع متفاوت باشد.
در بازیها فقط حجم عملیات Shading نیست که سرعت اجرا را تعیین میکند. پهنای باند حافظه نیز میتواند به صورت مستقیم روی کیفیت اجرای بازی تأثیر بگذارد. معماری تورینگ فناوری فشردهسازی حافظهی پاسکال را بهبود داده و همچنین برای اولین بار در RTX 2080 و RTX 2080 Ti از حافظههای GDDR6 شرکت مایکرون استفاده شده است که دارای پهنای باند ۱۴ گیگابیت در ثانیه بوده و نسبت به نسل قبلی یعنی GDDR5X حدود ۲۰ درصد مصرف توان کمتری دارد. همچنین انویدیا در معماری تورینگ تداخل اطلاعات را ۴۰ درصد کاهش داده است.
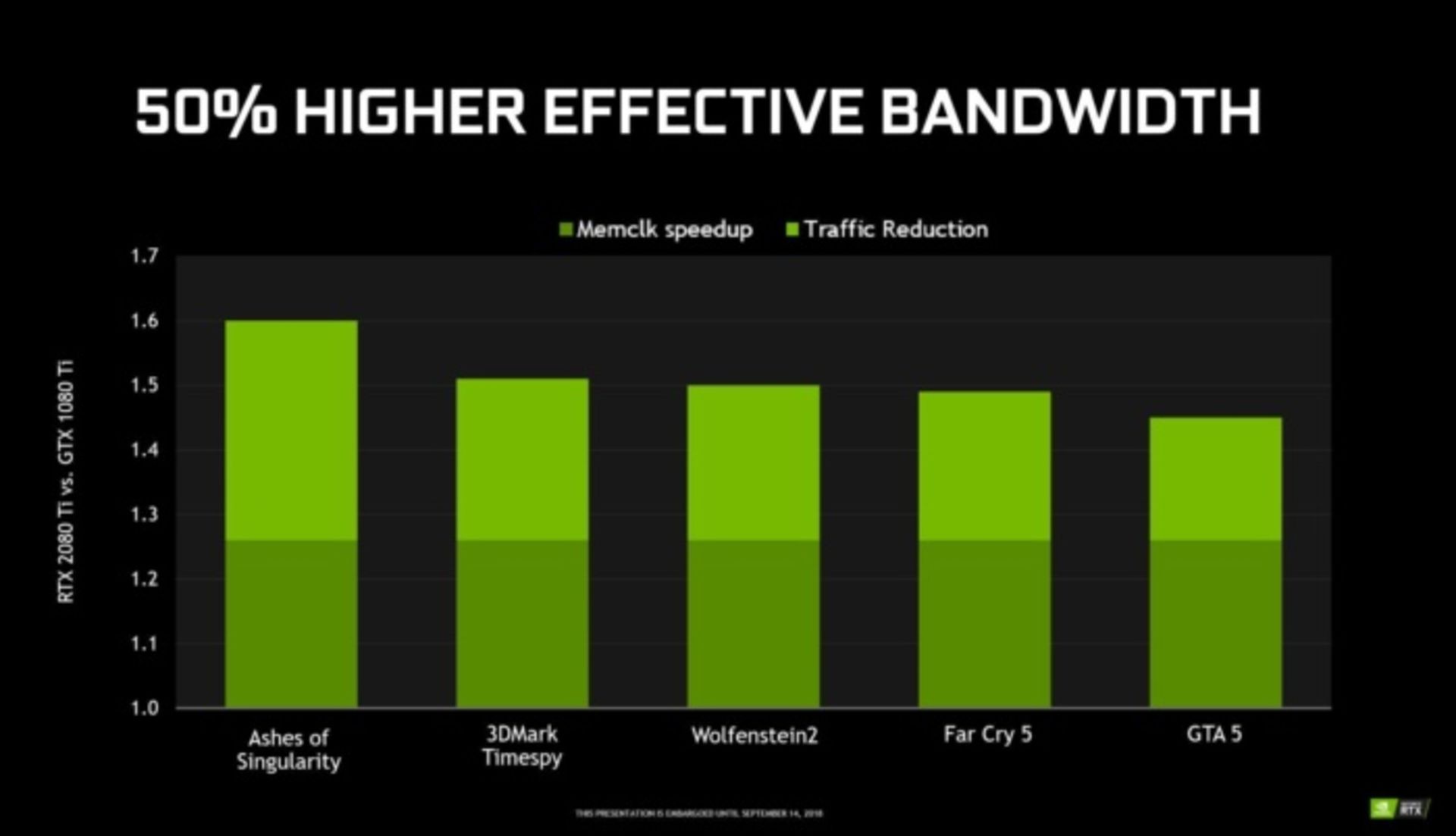
همه اینها در کنار هم، بهبودی ۵۰ درصدی در پهنای باند حافظه را برای پردازنده RTX 2080 Ti نسبت به GTX 1080 Ti به ارمغان آورده است. در دنیای واقعی این بهبود موجب میشود پهنای باند کارتهای حافظه جدید به ۶۱۶ گیگابایت بر ثانیه برسد که نسبت پردازندههای قبلی با پهنای باند ۴۸۴ گیگابایت بر ثانیه در همان اسلات یک پیشرفت بزرگ به حساب میآید. این قدرت را مدیون حافظههای نسل جدید GDDR6 هستیم.
فناوریهای جدید تورینگ برای Shading
همانطور که از معرفی یک معماری جدید انتظار میرود، انویدیا مجموعهای از فناوریهای جدید رونمایی کرده که توسعهدهندگان و بازیسازها میتوانند از آنها برای بهبود کارایی و جلوههای تصویری استفاده کنند.
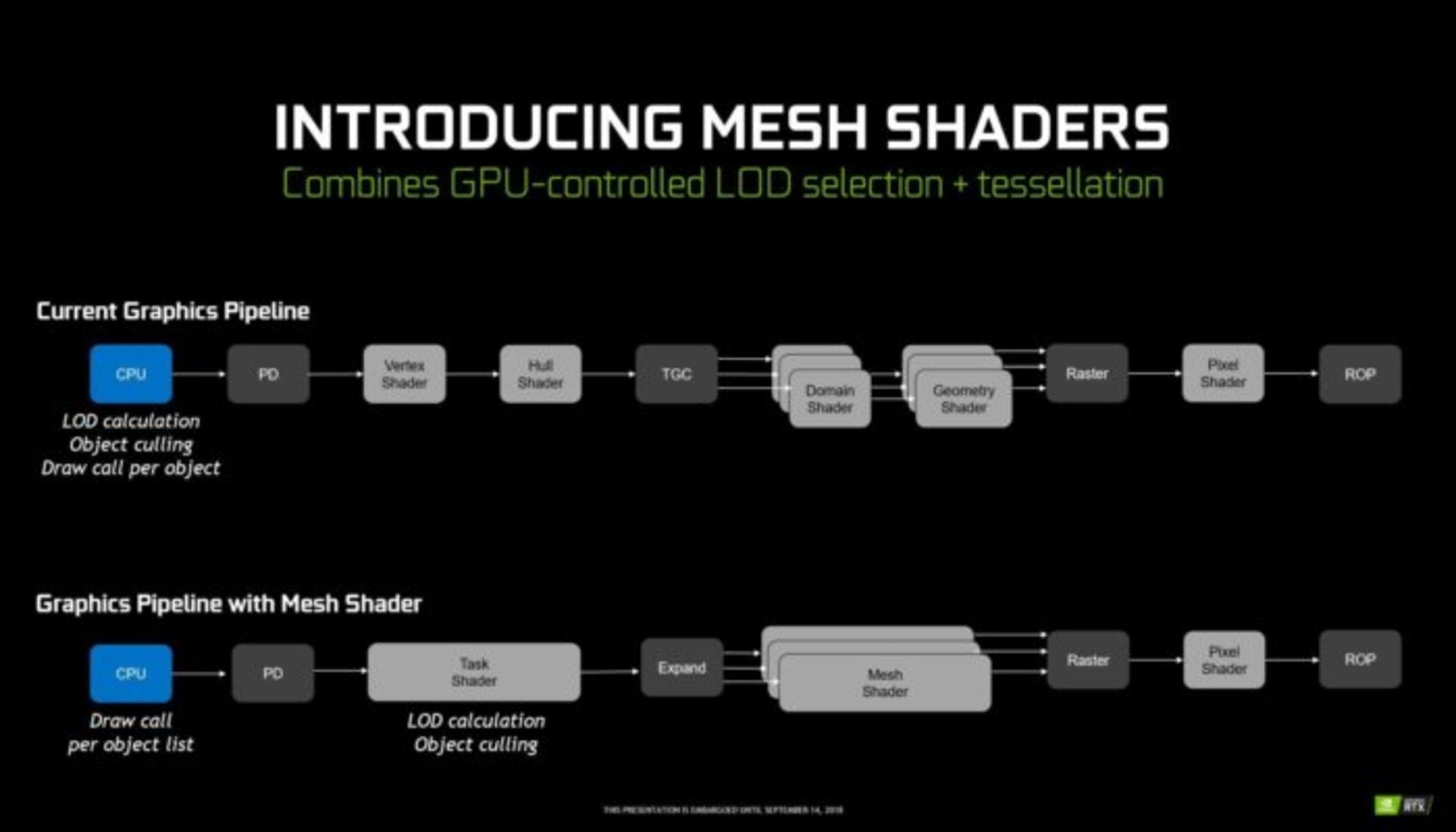
فناوری Mesh Shading میتواند بخشی از بار پردازنده اصلی (CPU) را در حین ساختن تصاویر پیچیده بصری با دهها هزار شئ به دوش بکشد. این فناوری از دو طبقه Shader تشکیل شده است. یک سطح، وظیفهی تشخیص بخشهایی از صحنه را دارد که نیاز به رندر شدن دارند و سطح دیگر تشخیص میدهد هریک از این بخشها به چه میزان جزییات نیاز دارند. برای مثال اشیاء نزدیک به جزییات بیشتر و اشیاء دور به جزییات کمتری در رندر نیازمند هستند.
انویدیا قدرت فناوری Mesh Shading را با یک دمو بسیار قابل توجه از پرواز یک سفینه فضایی با بیش از ۳۰۰ هزار فضانورد نمایش داد. دمو با نرخ رفرش ۵۰ فریم بر ثانیه به روز میشود. میزان جزییات این صحنه بسیار زیاد بود اما فناوری انویدیا توانسته بود با تشخیص صحیح، تعداد مثلثهای رسم شده را از ۳ هزار میلیارد عدد ممکن به ۱۳ هزار عدد مؤثر کاهش دهد که کار خارقالعادهای است.

نرخ Shading متغیر در واقع نسخهی توسعهیافته Shading چند وضوحی است که انویدیا سالهاست از آن استفاده میکنند. چشم انسان تنها میتواند نقاطی که بر روی آنها تمرکز کرده است را با کیفیت بالا ببیند. فناوری انویدیا از این خاصیت چشم استفاده کرده و تنها اشیائی که توسط چشم دنبال میشوند را با حدکثر جزییات رندر میکند و سایر اشیاء را به ترتیب اولویت و میزان توجه چشم با کیفیت کمتری به نمایش در میآورد.
فناوری دیگر انویدیا با عنوان Shading وفقپذیر با محتوا نیز به صورت مشابهی عمل میکند با این تفاوت که در این روش بخشهایی از صفحه که دارای جزییات کمتر یا تکرار رنگهای بیشتری هستند با وضوح کمتری رندر میشود. در یک آزمایش، بازی ولفنشتاین ۲ در دو حالت فعال و غیرفعال این قابلیت اجرا شد. در حالی که متوجه تغییر گرافیک در این دو حالت نمیشدیم آلبن گفت در حالت فعال این فناوری بیش از ۲۰ درصد افزایش در نرخ بهروز رسانی صفحه داشته است.

این فناوری همچنین میتواند در واقعیت مجازی برای بهبود وضوح تصویر و سرعت بهروز رسانی صفحه به کار گرفته شود. یکی دیگر از فناوریهای مفید برای واقعیت مجازی قابلیت رندر چند نمایی (Multi View Rendering) است. این فناوری که در واقعه توسعه قدیمیتر انویدیا است به توسعهدهندگان اجازه میدهد یک صحنه را به صورت همزمان از چند زاویهی دید یا زاویههای مختلفی از یک شئ را در یک عملیات رندر کنند.
و در نهایت انویدیا فناوری Shading حوزه بافت (Texture Space Shading) را معرفی کرده است که به توسعهدهندگان اجازه میدهد به جای رندر یک صحنه، تمام محیط اطراف یک شئ را رندر کنند تا به این ترتیب به آنها امکان دهد با یک بار رندر کردن تمام فضا آن را در فریمها و پرسپکتیورهای مختلف مورد استفاده قرار دهند.
تورینگ چگونه فریمها را پردازش میکند؟
برای یک معماری استاندارد پردازنده گرافیکی، شاید همین اطلاعات کافی باشد، اما برای تورینگ نه! جزییات و ویژگیهای فراوانی باقی مانده که به آنها بپردازیم. اما قبل از اینکه بیشتر جلو برویم بیایید یک بار روند پردازش یک فریم در این معماری را با هم مرور کنیم.

هستههای RT معماری تورینگ
بیایید بررسی موشکافانه معماری جدید را با هستههای RT شروع کنیم. آنطور که به نظر میآید RT مخفف عبارت رهگیری پرتو (Ray Tracing) است (اگر چه انویدیا هرگز درباره این نام توضیحی نداده است). همانطور که از این نام بر میآید، این هستهها برای بهبود قابلیت رهگیری پرتو (قابلیتی که با ردگیری شعاع منابع نوری، تأثیر و بازتاب آنها بر روی اجسام را به صورت دقیق شبیهسازی میکند) طراحی شدهاند. این قابلیت یکی از اصلیترین ویژگیهای پردازندههای گرافیکی سری ۲۰ انویدیا به حساب میآید – و شاید به همین دلیل باشد که پردازندههای جدید عبارت GTX را دیگر همراه خود ندارد -.
اما احتمالا میدانید که پیادهسازی چنین قابلیتی در بازیها برای کارت گرافیک چقدر پرهزینه است. حتی وجود هستههای اختصاصی RT نیز نمیتواند رهگیری پرتو واقعی را به بازیها بیاورد. کاری که این هستهها انجام میدهند به نوعی شبیهسازی این قابلیت است. اتفاقی که در واقع رخ میدهد این است که پردازنده گرافیکی ابتدا صحنه را بر اساس روشهای معمول رندر میکند، سپس هستههای RT تأثیر نور، سایهها و بازتابها را بر روی صحنه رندر شده بازسازی میکنند. نتیجه این روش بسیار خوب و قابل توجه از آب در میآید.
نحوه پیادهسازی رهگیری پرتو از طریق محدود کردن حجم محاسبات در طی چند مرحله (Bounding volume hierarchy) است. در این روش پردازنده ابتدا بررسی میکند که کدام اشیاء در معرض تابش نور قرار گرفتهاند. سپس به جای آنکه تمام شئ را به مثلثها تبدیل کرده و رندر کند، آن را به تعدادی مکعب تقسیم میکند و بررسی میکند که کدام مکعبها در معرض شعاع نور هستند. سپس بار دیگر آن مکعبها را بررسی و آنهایی که در معرض نور هستند به مکعبهای کوچکتر تبدیل میکند و این روند را آنقدر ادامه میدهد تا به کوچکترین مکعبهای ممکن برسد. در آخرین مرحله محدوده هریک از مکعبها را به مثلث تبدیل کرده و تأثیر نور بر آنها را اعمال نموده و نتیجه کار را به شئ اصلی برمیگرداند.
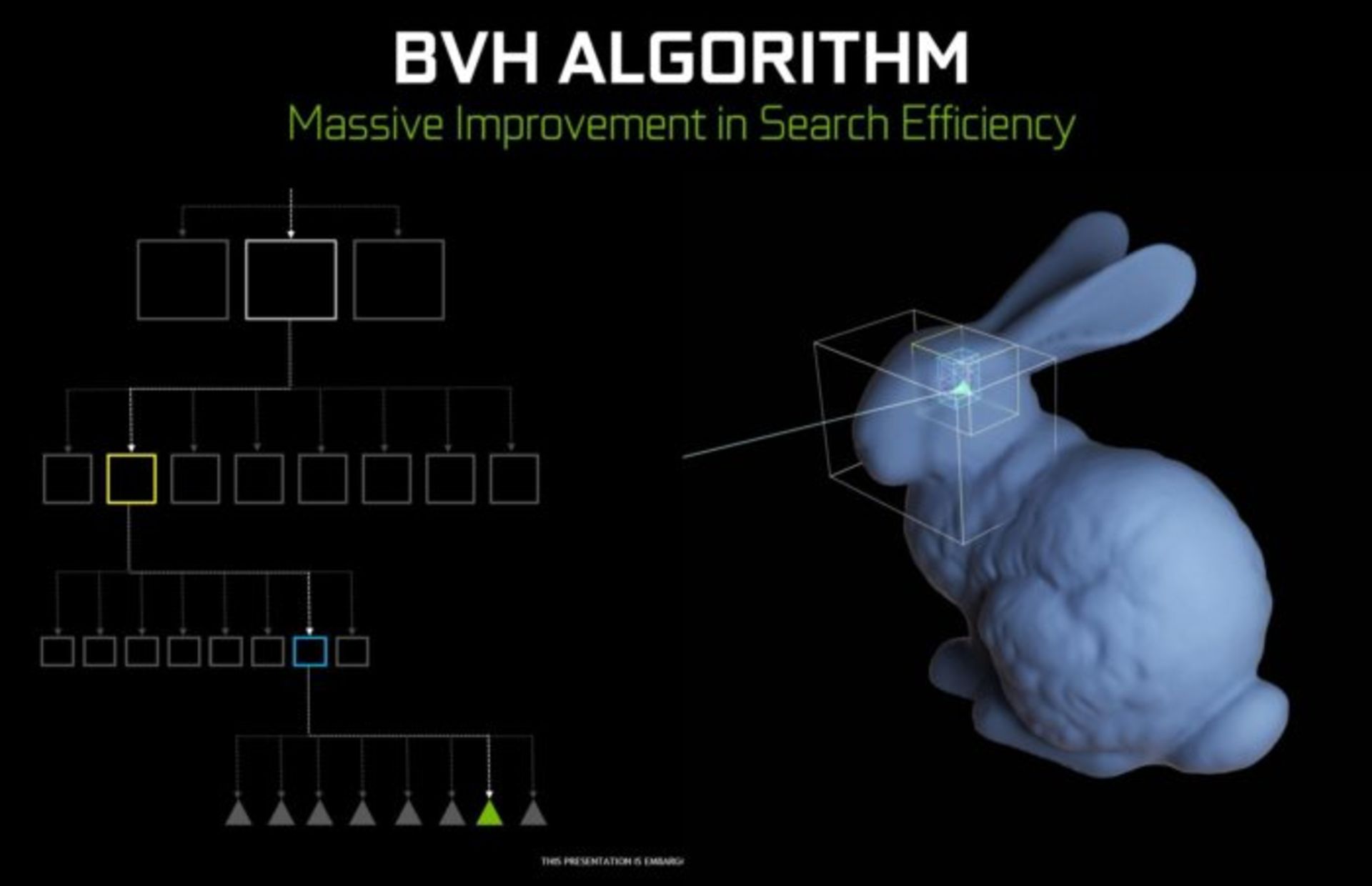
این روش به پردازنده گرافیکی امکان میدهد به جای پردازش دقیق میلیونها مثلث، تنها تعدادی از مثلثها را که در معرض پرتو نور قرار گرفتهاند پردازش کند. اما انجام این عملیات در معماری پاسکل تقریبا غیرممکن است. چرا که واحدهای Shader در معماری پاسکال باید هزاران دستور نرمافزاری شبیهسازی شده را برای پیدا کردن مکعبهای نهایی انجام دهند و سپس عملیات شبیهسازی تأثیر نور را بر روی آنها اجرا کنند. اما معماری تورینگ به صورت دیگری عمل میکند. هر Shader یک پرتو نور را اعمال میکند و به جای اینکه از طریق شبیهسازی نرمافزاری، یک هسته RT را مامور پیدا کردن مثلثها میکنند. در این مدت Shader آزاد است تا عملیات دیگری انجام دهد.
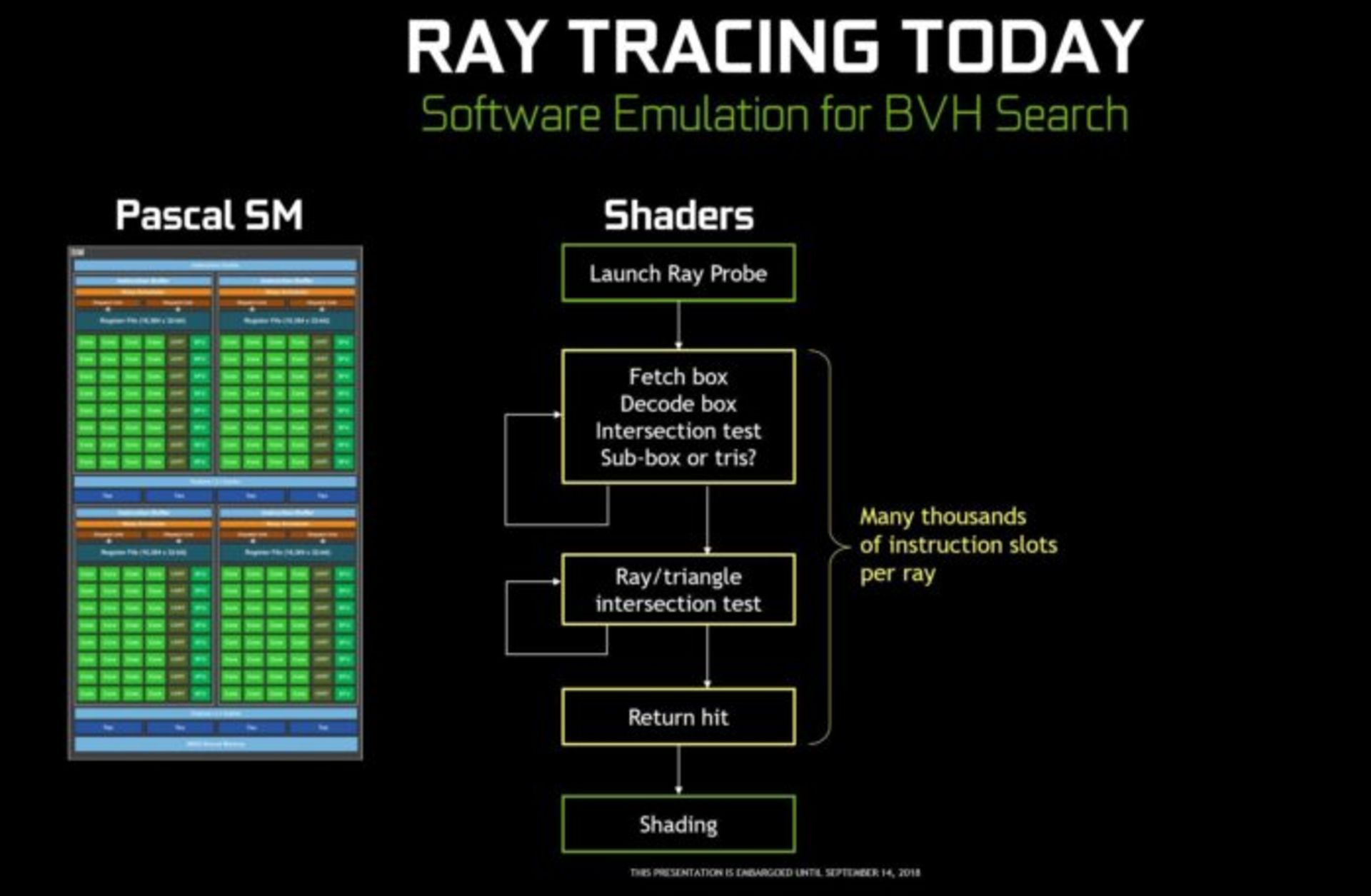
هستههای RT از دو بخش تشکیل شده است. ابتدا بخش اول به ارزیابی تمام مکعبها در سلسله مراتب روش BHV میپردازد تا به آخرین سطح از مثلثها دست یابد، سپس بخش دوم آزمایشهای تقاطع مثلثهای تحت تأثیر را انجام میدهد (Perform ray-triangle intersection tests). در نهایت نتایج به دست آمده به Shaderها ارسال میگردد تا عملیات پردازش تصویر را انجام دهند.
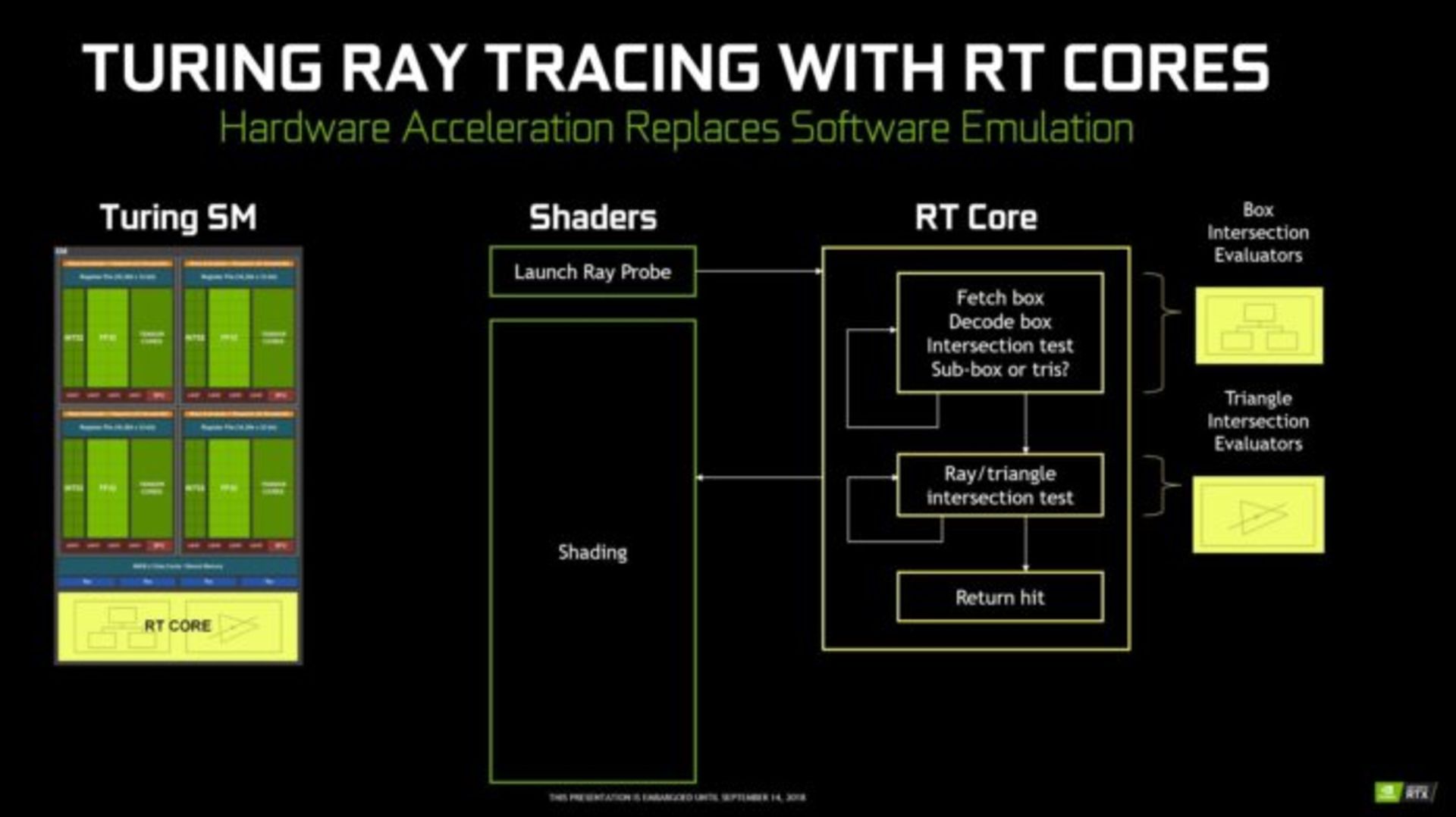
روش انویدیا در تقسیم وظایف بین دو بخش برای انجام عملیات رهگیری پرتو باعث شده نتیجه بسیار شگفتانگیزی رقم بخورد. انویدیا میگوید نسل پردازندههای گرافیکی GTX 1080 Ti در بهترین حالت میتوانستند به پردازش ۱/۱ میلیارد پرتو در ثانیه برسند در حالی که پردازنده گرافیکی جدید RTX 2080 Ti میتواند در هر ثانیه بیش از ۱۰ میلیارد پرتو را پردازش کند و این یعنی پردازش بلادرنگ پرتو – چیزی که تا پیش از این تصور میکردیم صنعت بازی سالها با آن فاصله داشته باشد - حاصل فناوری هیبرید Geforce RTX است.
هستههای Tensor و NGX
آنطور که انویدیا میگوید هستههای Tensor به صورت اختصاصی برای استفاده در هوش مصنوعی توسعه داده شدهاند.
هستههای Tensor به صورت اختصاصی برای اجرای عملیات برداری/ماتریسی که هسته اصلی محاسبات یادگیری عمیق است طراحی شدهاند.
در واقع Geforce RTX 20180 Ti و RTX 2080 اولین پردازندههای گرافیکی هستند که دارای هستهی تنسور هستند. این هستهها پیش از این در پردازندههای گرانقیمت اختصاصی مراکز داده انویدیا (ولتا) دیده شده بودند. برخلاف ولتا، هستههای Tensor جدید دارای دو حالت INT4 و INT8 مورد استفاده در محاسبات غیر گرافیکی (که سطوحی از کوانتیزه شدن اعداد در آنها امکانپذیر است) هستند. در واقع میتوان گفت حالت FP16 در بازیها مورد استفاده قرار میگیرد و کاربرد دو حالت جدید در عملیات و محاسبات هوش مصنوعی است. البته عملیات اعداد شناور در بازیها بسیار ضروری و تأثیرگذار است و معماری تورینگ میتواند تا ۱۱۴ ترافلاپس از این نوع عملیات را در ثانیه اجرا کند.

خب تا اینجا فقط تعدادی اعداد و ارقام و اصطلاحات درباره هستههای تنسور گفتهایم. واقعا این هستهها چکار میکنند؟ این هستهها از هوش مصنوعی استفاده میکنند تا نتیجهی رهگیری پرتو را بهبود ببخشد. در واقع میتوان گفت رهگیری بلادرنگ پرتو چیز تازهای نیست. شاید سالهاست که این پردازش در بازیها مورد استفاده قرار میگیرد، اما همیشه به علت عدم توانایی پردازندههای گرافیکی در اجرای کامل و دقیق آن، دچار ضعف بوده و کیفیت پایینی داشته است. حالا انویدیا با استفاده از یادگیری ماشین و هستههای تنسور ضعفها و کمبودهای موجود را رفع میکند.
این تنها کاربرد هستههای تنسور نیست. انویدیا کاربردهای جذاب دیگری نیز برای آن در نظر گرفته است:
هستههای NGX برای بهکارگیری یادگیری عمیق طراحی شدهاند تا بتوانند مجموعهای از خدمات مبتنی بر شبکههای عصبی مورد استفاده در هوش مصنوعی برای بهبود کارهای گرافیکی، رندر و هر کاربرد دیگر در سمت کاربر را اجرا کنند.

این شرکت ابررایانه Saturn V خود را بهکار گرفته تا هوش مصنوعی را برای هرچه بهتر کردن بازدهی هستههای NGX آموزش دهد و سپس شبکهی عصبی تربیت شده را هنگام نصب برنامه Nvidia experience به رایانه کاربران منتقل کند. پس از نصب این برنامه این هستهها برای تطبیق هرچه بیشتر هوش مصنوعی انویدیا با رایانه شما بیشتر و بیشتر آن را آموزش میدهند.

برخی از قابلیتهای NGX تاکنون به نمایش گذاشته شده است. برای مثال میتوان به الگوریتم ساخت ویدئو بسیار آهسته (Super Slow-mo) از روی ویدئوهای معمولی، یا حذف اشیاء در تصاویر و جایگزینی خودکار آنها با المانهای موجود در تصویر اشاره کرد. ایده جالبیست که بتوانید به صورت خودکار دکلهای انتقال برق را از منظرهی عکس خود حذف کنید و جای آن تصویری از ابرهای موجود جای آن بگذارید، نه؟
کاربرد بسیار جذاب دیگری که توسط انویدیا ارائه شده، امکان افزایش رزولوشن و کیفیت تصاویر معمولی و بیکیفیت است. انویدیا با استفاده از هوش مصنوعی و با تشخیص اجزا به کار رفته در تصویر، پیکسلهای لازم را به تصویر اضافه میکند. میتوان گفت الگوریتم انویدیا این کار را بسیار خوب (تقریبا به بهترین شکل) انجام میدهد. این شرکت مدعیست پردازندههای جدیدش میتواند به صورت بلادرنگ یک ویدئوی 1080p را به 4K تبدیل کنند.


اما شاید بتوان بهترین ویژگی برگرفته از هستههای NGX را یادگیری عمیق نمونهبرداری بسیار بالا (Deep Learning Super Sampling یا DLSS) که به کارت گرافیک قدرت رندر تصاویر با لبههای بسیار شفافتر به وسیلهی اجرای دقیقتر الگوریتمهای Anti-Aliasing با هزینه کمتر دانست. انویدیا در مقالهای توضیح داده این قابلیت چطور کار میکند:
راز موفقیت DLSS در روند آموزش شبکه عصبی آن و یافتن بهترین روش برای دستیابی به خروجی ایدهآل است. ما ابتدا مجموعهای از تصاویر را با ۶۴ آفست مختلف رندر میکنیم و سپس با ترکیب این ۶۴ تصویر یک نمونه ایدهآل از تصویر مورد نظر تهیه میکنیم. سپس ورودی خام را به شبکه DLSS میدهیم و شبکه را تحت آموزش قرار میدهیم تا با مقایسه خروجیهای خود با خروجی ایدهآل نواقص آن را کشف و با بهروزرسانی وزنهای شبکه عصبی ایرادها را رفع نماید. در انتها این شبکه پس از تکرار فراوان روند آموزش، یاد میگیرد چگونه نزدیکترین خروجی به تصویر ایدهآل را بسازد و در عین حال از پیش آمدن ایرادهایی مانند ماتی، نویز، عدم شفافیت و... جلوگیری کند.علاوه بر روش ذکر شده که ما آن را DLSS استاندارد مینامیم، روش دیگری با عنوان DSLL 2x نیز طراحی کردهایم که در آن تصویر به دست آمده از DLSS استاندارد را با شبکه DLSS بزرگتری دیگری ترکیب میکنیم تا خروجیای بسیار نزدیک به خروجی به دست آمده از روش 64x به دست آید. با این ترتیب به تصویری میرسیم که دستیابی به آن به روشهای قبلی غیرممکن است.
توسعهدهندگان باید پشتیبانی از NGX را به بازیهای خود اضافه کنند. برای این کار انویدیا یک API و SDK در اختیار آنها قرار داده است. البته قرار نیست آنهای NGX را آموزش دهند، چرا که انویدیا خود این کار را میکند، چنانکه به گفته تونی تاماسی (Tony Tamasi) معاون محتوا و فناوری انویدیا، آنها توانستهاند در کمتر از یک روز NGX را با تمام بازیهای موجود تطبیق دهند.
نمایشگر و ویدئو
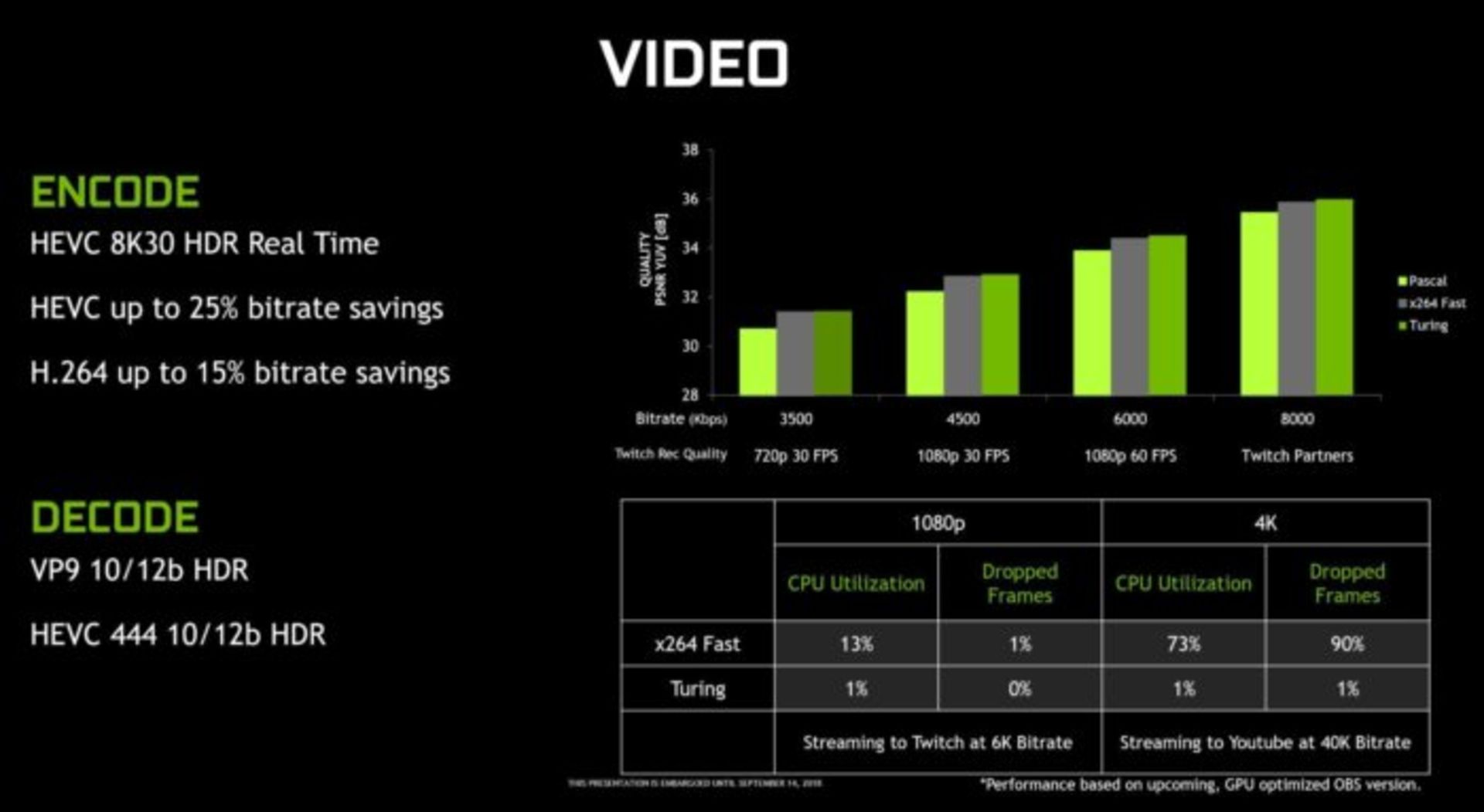
و در نهایت میرسیم به بخش مدیریت نمایشگر پردازندههای جدید. انویدیا در پردازندههای گرافیکی Geforce RTX 2070 ،2080 ،2080 Ti پشتیبانی از VirtualLink را برای انتقال تصویر، صدا و سایر دادههای مورد نیاز در هدستهای واقعیت مجازی از طریق USB-C افزوده است. معماری تورینگ همچنین از HDR بومی با تأخیر اندک به همراه Tone mapping تا رزولوشن 8K و نرخ بهروز رسانی ۶۰ فریم بر ثانیه روی دو نمایشگر پشتیبانی میکند. انویدیا همچنین بهبودهایی در نحوهی Encoding و Decoding ویدئوها داده که میتواند برای علاقهمندان به پخش زنده فیلم و ویدئو جالب باشد. جزییات بیشتر را در تصویر زیر میتوانید ببینید.
در این مقاله سعی کردیم نگاهی عمیق داشته باشیم به پیشرفتها و امکانات جدید که انویدیا در مرکز پردازندههای گرافیکی جدید خود قرار داده است. منتظر میمانیم تا این غولهای پردازشی به دستمان برسد و آنچه توصیف شده را با چشم خودمان ببینیم.