اینتل معماری تراشههای مجتمع گرافیکی نسل ۱۱ خود را رونمایی کرد

شرکت اینتل به یکباره و بی هیچ مراسم و تشریفاتی، در وبسایت خود از ریز معماری پردازندههای گرافیکی مجتمع نسل ۱۱ (Gen11) رونمایی کرد. در اسناد ارائهشده توسط اینتل، جزئیات درخورتوجهی در مورد تراشهی گرافیکی جدید این شرکت که همراهبا پردازندههای ۱۰ نانومتری Ice Lake در آیندهی نزدیک عرضه خواهند شد، ارائه شده است.
اینتل پردازندهی گرافیکی نسل ۱۱ جدید خود را در مراسم Architecture Day معرفی کرد و تصریح کرد که تیم مهندسی پردازندهی گرافیکی نسل ۱۱ بهسختی در حال کار روی این تراشههاست تا سطح عملکردی چشمگیر نسبت به تراشههای گرافیکی نسلهای قبلی این شرکت ایجاد کند. هدف از ساخت چنین تراشهای رسیدن به قدرت محاسباتی یک ترافلاپس در محاسبات اعشاری ۳۲ بیتی و ۲ ترافلاپس در پردازش مشابه ۱۶ بیتی همراهبا توان مصرفی پایینتر در تراشههای گرافیکی مجتمع اینتل است. اخیرا شواهدی در مورد سطح عملکرد درخورتوجه این تراشه در محیطهای گرافیکی واقعی روی شبکهی اینترنت منتشر شده است.
با درنظرگرفتن اطلاعات و ارقام ارائهشده توسط شرکت اینتل در این اسناد، میتوان بهطور مستدل عملکرد خام این تراشههای مجتمع گرافیکی را در محدودهی هستههای Radeon Vega 8 دانست که همراهبا پردازندهی Ryzen 3 2200G عرضه میشود. این سطح عملکرد مترقی، حاکی از بهبود اساسی در موتورهای گرافیکی پیشفرضی است که اینتل همراهبا اغلب پردازندههای جریان اصلی محصولات خود عرضه میکند؛ چنین پردازندهی گرافیکی یکپارچهای میتواند زنگ خطری برای محصولات گرافیکی رده پایین انویدیا و AMD به حساب آید.
اسناد ارائهشده توسط اینتل حاکی از آن است که این تراشههای گرافیکی بر پایهی فناوری ساخت ۱۰ نانومتری با ترانزیستورهای نسل سوم FinFET تولید شده است. همانطور که انتظار میرفت، این تراشهها از تمامی APIهای مهم پشتیبانی میکند. اینتل پشتیبانی از ۴ حافظهی ۳۲ بیتی LPDDR4/DDR4 را به این پردازندهها اضافه کرده که پیشرفت چشمگیری نسبت به پشتیبانی تراشههای گرافیکی نسل ۹ از دو حافظهی ۶۴ بیتی LPDDR4/DDR4 به حساب میآید.در تراشههای گرافیکی نسل ۹ اینتل از چیدمانی ماژولار شامل ۳ برش فرعی (Sub-Slice) که هر یک میزبان ۸ واحد اجرایی (EU) است، استفاده شده است. شرکت اینتل Intel این بار در طراحی نسل ۱۱ این تراشههای گرافیکی تا ۸ برش فرعی ایجاد کرده که در اکثر نسخههای GT2 در مجموع دربرگیرندهی ۶۴ واحد اجرایی یا EU است؛ اما ممکن است در طراحی برخی نسخههای تراشه این میزان تعدیل شود.در چنین حالتی قابلیت محاسباتی تراشهی جدید تا ۲.۶۷ برابر تراشههای گرافیکی نسل ۹ افزایش مییابد. تراشهی جدید همچنین قادر به انتقال ۲ پیکسل در هر کلاک است.
شکل زیر نشاندهندهی دیاگرام ابتدائی بلوکهای یک پردازندهی نسل بعدی Ice Lake است؛ همانطور که دیده میشود قسمتهای مختلف SOC (سیستم روی یک تراشه) شامل هستههای پردازنده، هستههای پردازندهی گرافیکی، LLC (آخرین سطح حافظهی کش) و عوامل کارگزار سیستم (شامل PCIe، کنترلر حافظه و کنترلر نمایشگر) ازطریق یک حلقهی اتصالدهندهی داخلی به یکدیگر وصل شده و با هم در ارتباط هستند.
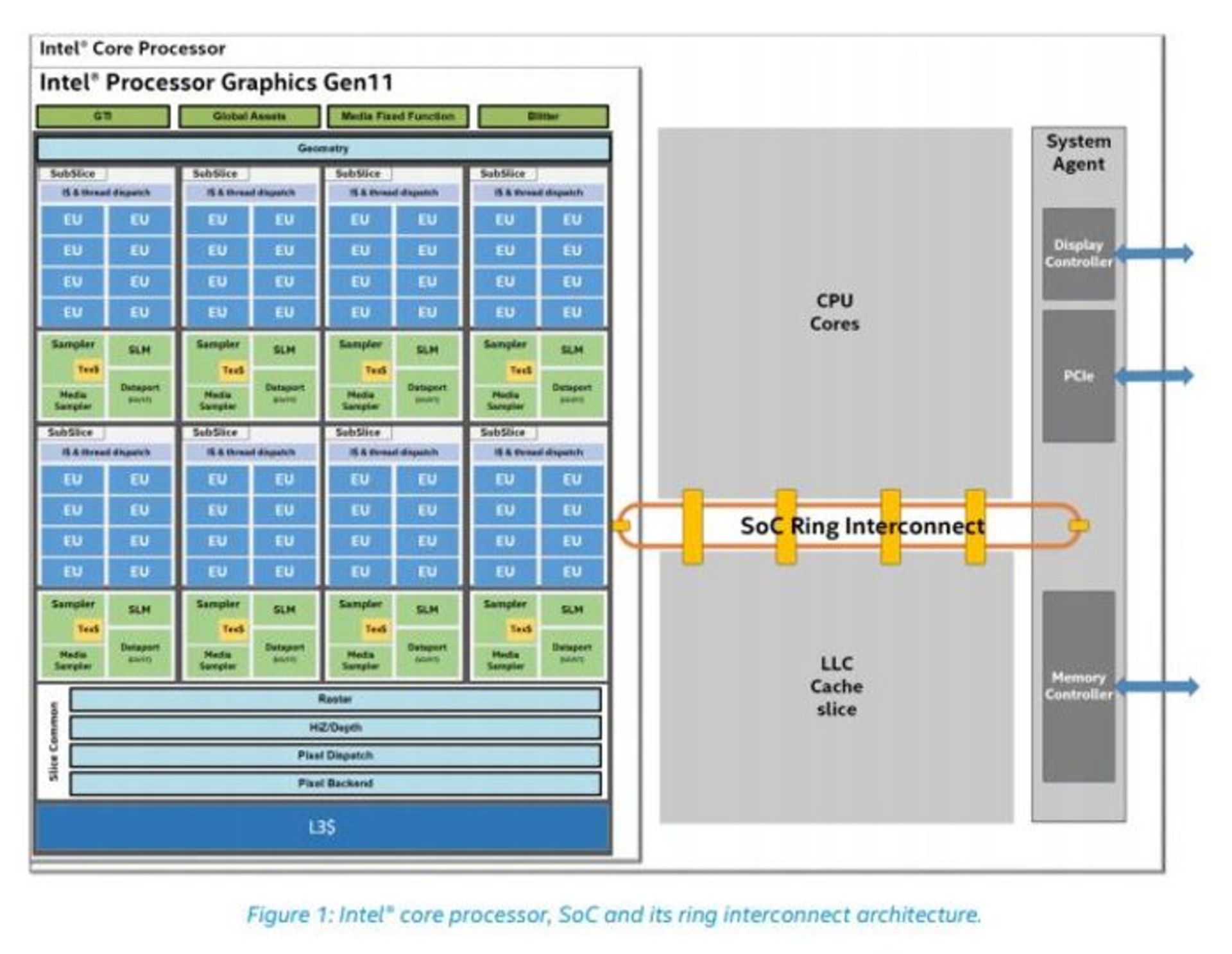
چنین چیدمانی گویای آن است که اینتل از یک اتصال داخلی Ring Bus برای اتصال ساختارهای مختلف در تراشه استفاده میکند. مسئلهی قابلتوجه در این طراحی این است که آخرین سطحِ حافظهی کش (LLC) در میان هستههای پردازنده و تراشهی گرافیکی به اشتراک گذارده شده که باعث حذف فرایند نقل و انتقال دادهها به واحدهای متناظر میشود. در طراحی این SOC از دامنههای کلاک متعددی استفاده شده که به هر هستهی پردازندهی اصلی، تراشهی گرافیکی مجتمع و حلقهی اتصال داخلی، دامنهی کلاک معینی قابل تخصیص است.
تراشهی مجتمع گرافیکی نسل ۱۱ از رندرینگ Tile و همچنین حالت رندرینگ فوری پشتیبانی میکند؛ در این حالت در خلال برخی بارهای کاری رندرینگ، از میزان تقاضای حافظه کاسته میشود.
در شکل زیر، سلسلهمراتب حافظه در یک تراشهی Ice Lake و حداکثر پهنای باند متناظر میان اجزا نشان داده شده است. حرکت اینتل به سمت پشتیبانی از حافظهی LPDDR4 متضمن افزایش چشمگیر پهنای باند و در عین حال کاهش توان مصرفی است. نوآوری راستین در این تراشه در طراحی حافظهی اشتراکی نهفته است که تقاضا برای کپیکردن دادهها را ازطریق بافرها کاهش میدهد.
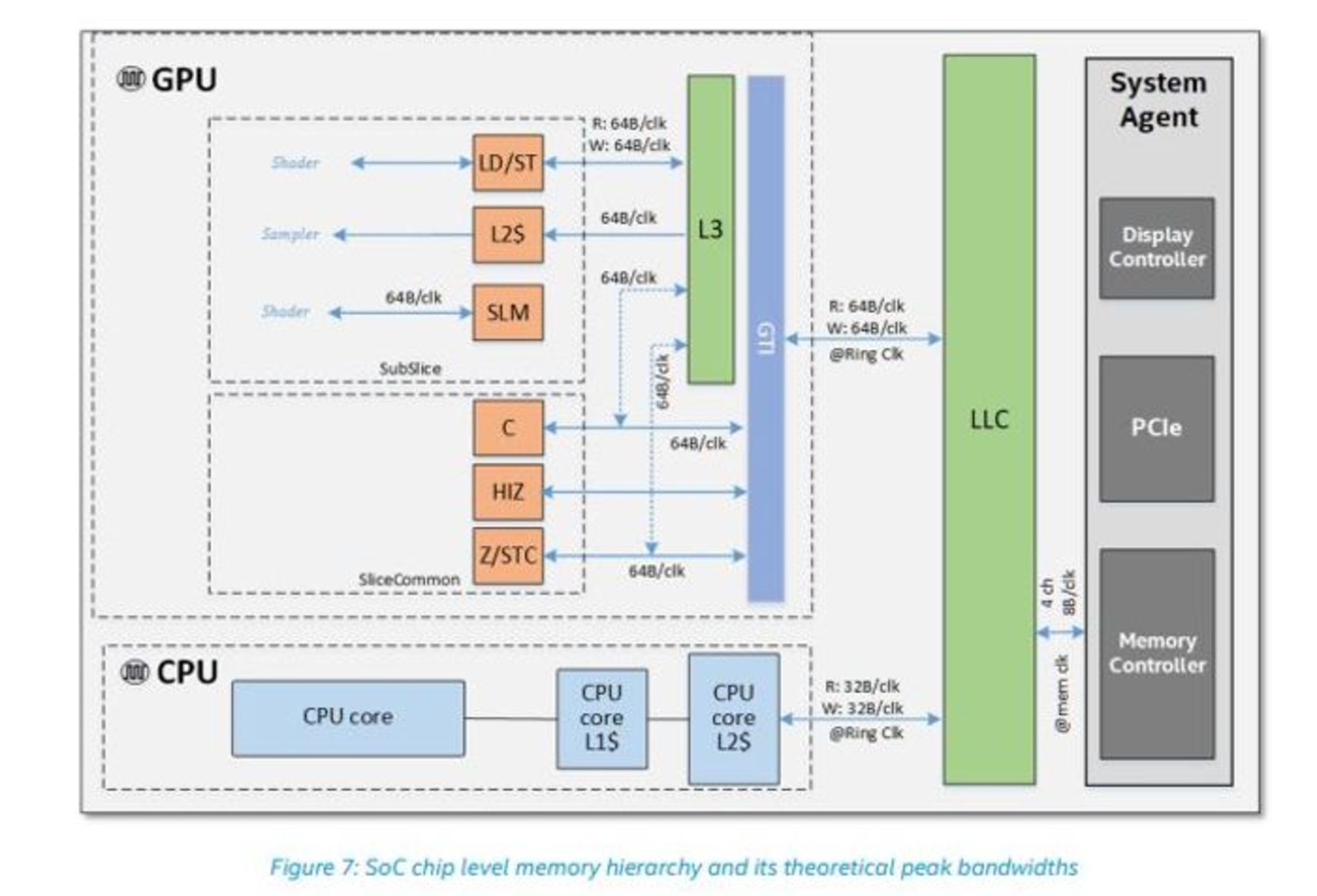
GTI (که مخفف Graphics Technology Interface یا رابط فناوری گرافیکی است) پردازندهی گرافیکی را به بخشهای دیگر تراشهی SOC شامل حافظهی LLC و DRAM متصل کرده است. شرکت اینتل در این نسخه سطح عملکرد را از ۳۲ بایت در هر کلاک به ۶۴ بایت در هر کلاک در عملیات نوشتن ارتقا داده، و صفبندیهای داخلی را با هدف کاهش تأخیر و بهبود پهنای باند بازآرایی و اصلاح کرده است.
در این شکل دیده میشود که پردازندهی گرافیکی (GPU) قادر به خواندن و نوشتن در حلقهی اتصال داخلی با سرعت ۶۴ بایت به ازای هر کلاک است، درحالیکه پردازندهی اصلی (CPU) فقط میتواند ۳۲ بایت به ازای هر کلاک در این رینگ بنویسد یا از آن بخواند؛ بنابراین پردازندهی گرافیکی مسیر (Pathway) سریعتری به آخرین سطح حافظهی کش اشتراکی (L3) در دسترس خود دارد. علاوهبر این، پردازندهی گرافیکی ۳ مگابایت کش سطح ۳ داخلی اختصاصی در اختیار دارد که بهصورت واسطهای میان برشهای فرعی و GTI عمل میکند.
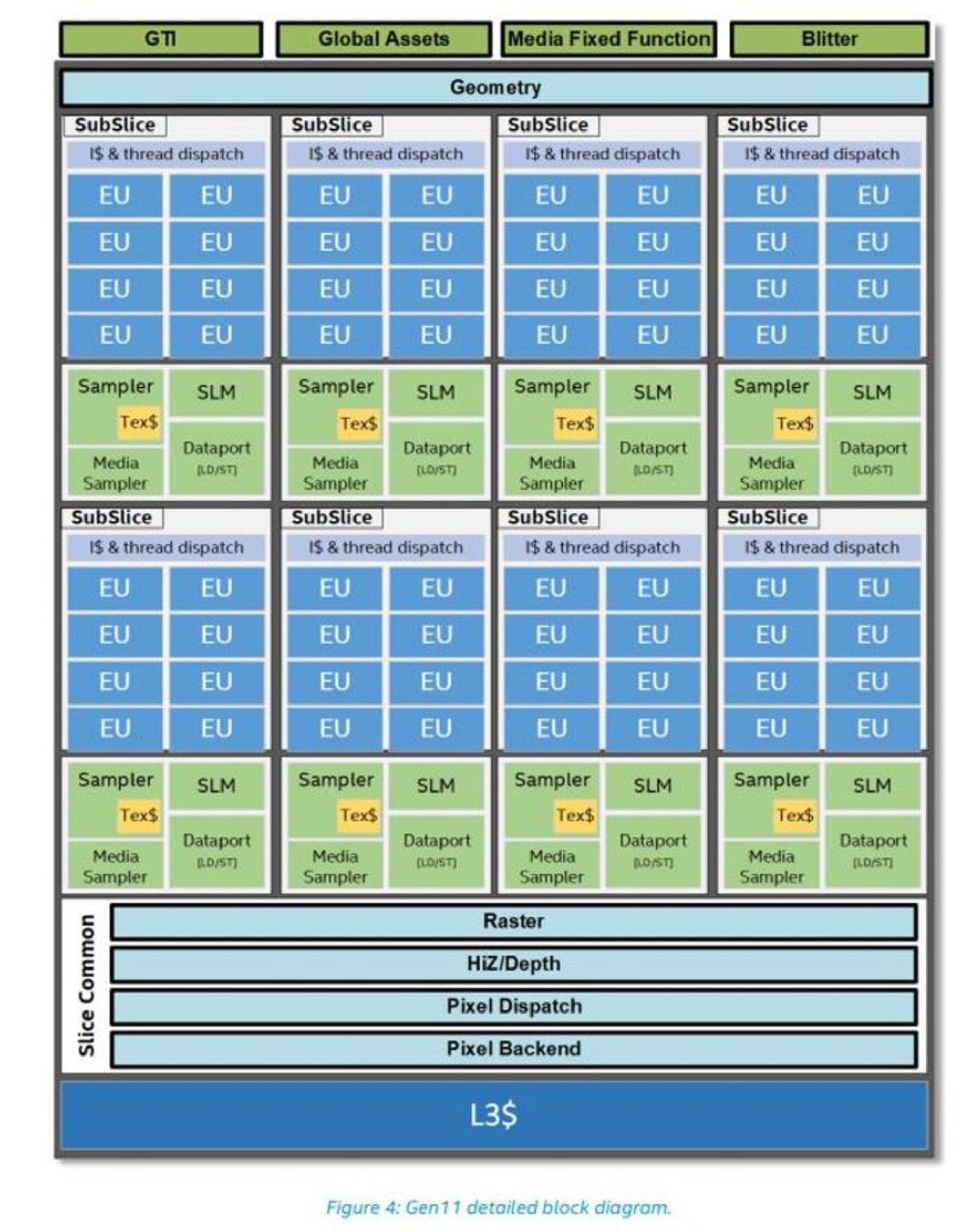
در تصویر زیر، نمایی از برشهای تراشهی گرافیکی نسل ۱۱ ارائه شده است. هر برش تراشه میزبان یک واحد 3D Fixed Function Geometry، هشت برش فرعی شامل واحدهای EU و یک برش مشترک (Common Slice) است که بلوکهای عامل ثابت را در بر داشته و اقدام به نوشتن در برش کش L3 میکند. اینتل زیرسیستم حافظه را با ۴ برابر کردن حافظهی کش سطح ۳ اختصاصی به میزان ۳ مگابایت بهبود بخشیده و برای بهبود و عدم تداخل در توازیِ کاری (Parallelism) حافظهی محلی اشتراکی (SLM) مجزایی برای هر برش فرعی در نظر گرفته است. بهعلاوه طراحی جدید، دربرگیرندهی الگوریتمهای فشردهسازی حافظه است.
سایر بخشهای ارتقاءیافته در معماری پردازندهی گرافیکی جدید شامل یک موتور HEVC Quick Sync Video کاهشدهندهی ۳۰ درصدی بیت ریت در مقایسه با نسل ۹ (در کیفیت تصویر مشابه یا بهتر)، پشتیبانی از استریم ویدئوی 4K و 8K چندگانه با توان مصرفی کمتر و نیز پشتیبانی از فناوری Adaptive Sync است. عمق بیت در رمزگشایی ویدئویی VP9 از ۸ به ۱۰ بیت افزایش یافته تا این بار از ویدئوهای HDR نیز پشتیبانی به عمل آید.
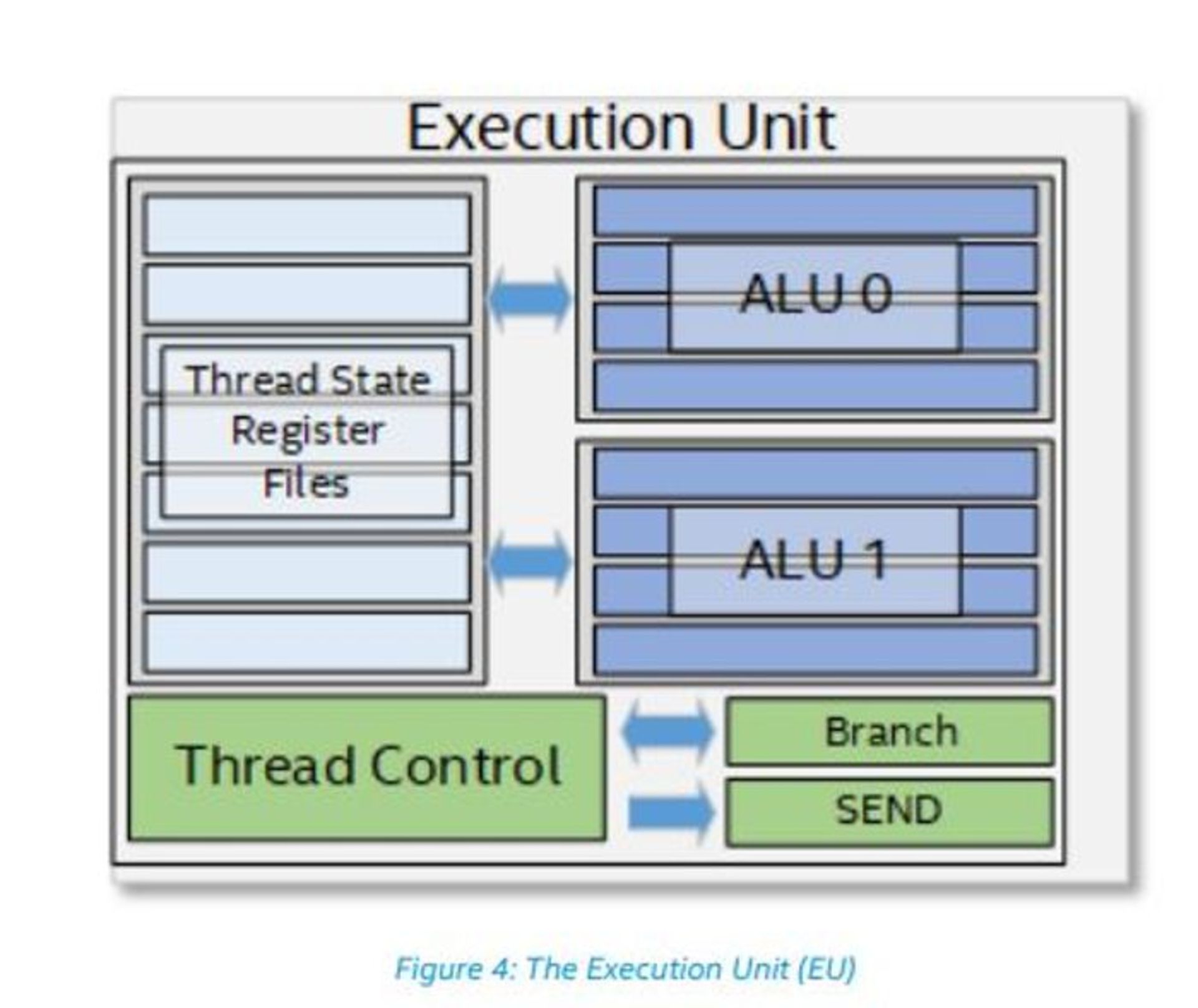
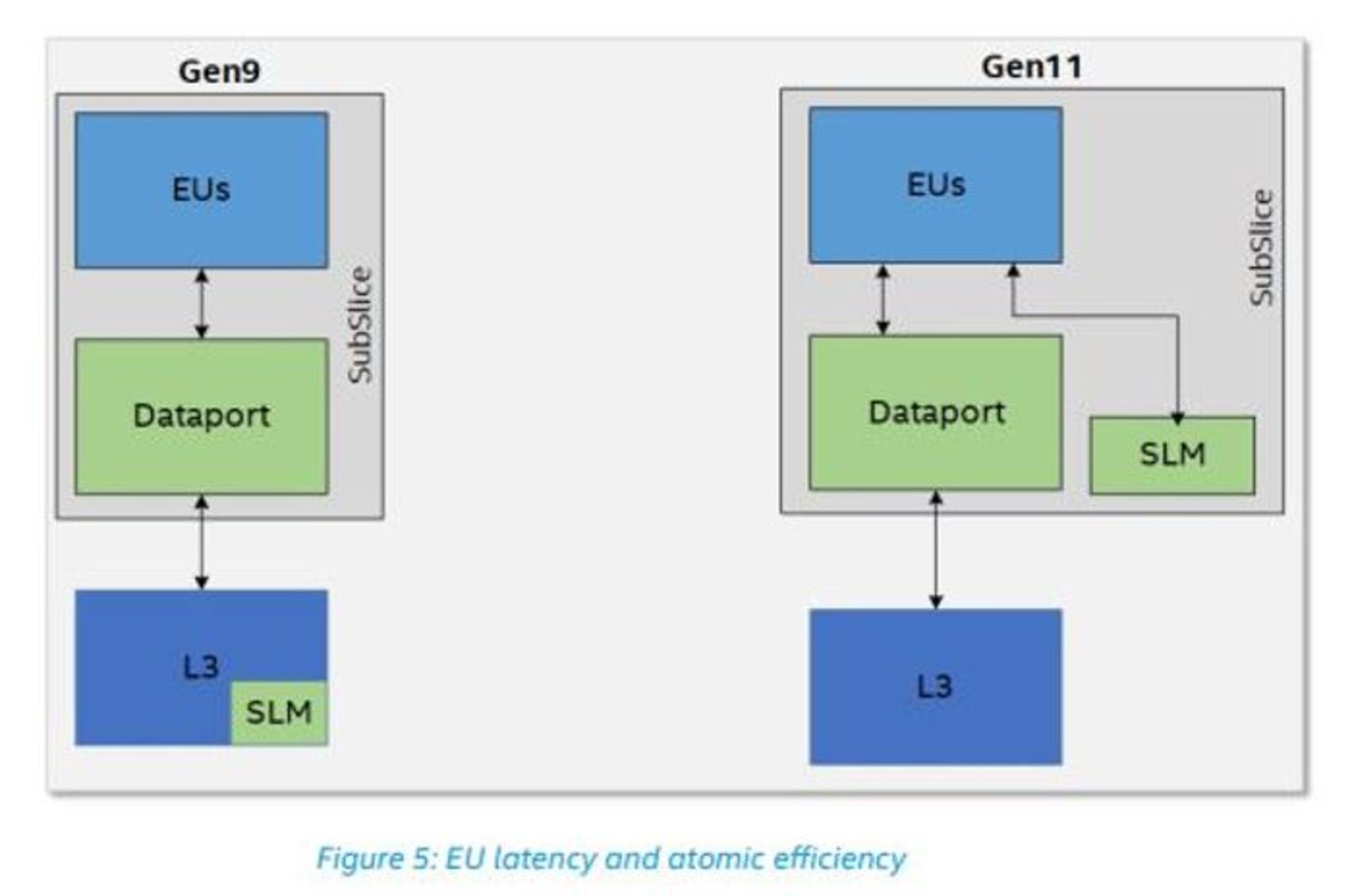
در بررسی عمیقتر تراشهی گرافیکی نسل جدید میتوان دید که هر برش میزبان ۸ برش فرعی است که هر کدام ۸ واحد اجرایی یا EU را در بر دارد. هر زیربرش دربرگیرندهی یک واحد Thread Dispatcher محلی و کشهای دستورالعمل مربوطبه خود برای تغذیهی آن است. یک حافظهی محلی اشتراکی، واحد نمونهبرداری بافت سهبعدی و واحد دیتاپورت هر یک از این برشهای فرعی را تکمیل میکند.
با نگاهی دقیقتر به طراحی حافظهی محلی اشتراکی (SLM) که ۸ واحد اجرایی را در هر برش فرعی تغذیه میکند، مشخص میشود که اینتل SLM را به این دلیل را در برش فرعی وارد کرده است که رقابت را در دیتاپورت به هنگام تلاش واحدهای EU برای دسترسی همزمان به کش سطح ۳ کاهش دهد. نزدیکی بیشتر SLM به واحدهای EU همچنین به کاهش تأخیر و بازدهی بوستها کمک میکند.
با ورود به درون هر یک از واحدهای اجرایی EU چند رشتهای (Multi-threaded)، میتوان یک جفت واحد محاسبهی اعشاری SIMD (یا ALU-ها) در هر کدام مشاهده کرد؛ اما در عمل هر یک از این واحدها هم از عملیات اعشاری و هم از عملیات صحیح پشتیبانی میکند. اینتل میگوید این واحدهای ALU قادر به انجام چهار عملیات اعشاری یا صحیح ۳۲ بیتی یا ۸ عملیات اعشاری ۱۶ بیتی است. این مقدار مساوی است با ۱۶ عملیات FP32 به ازای هر کلاک یا ۳۲ عملیات FP16 در هر کلاک.