
مقایسه جدیدترین معماریهای پردازنده گرافیکی: Navi در برابر Turing


دنیای پردازش گرافیکی روزبهروز پیچیدهتر و جذابتر میشود. غولهای بازار یعنی AMD و Nvidia همهی تلاش خود را به کار میگیرند تا حرفهایترین کاربران دنیای کامپیوتر یعنی گیمرها و متخصصان تولید محتوای گرافیکی را به خود جذب کنند. کاربران مذکور پس از مطالعهی عمیق اخبار و بررسیها پیرامون محصولات گرافیکی، هزینهی بالایی را برای خرید کارت گرافیک از هر یک از بازیگران اصلی بازار، پرداخت میکنند. سختافزاری که توسط آنها خریداری میشود، یک پردازندهی گرافیکی بسیار قدرتمند دارد که میلیاردها ترانزیستور در آن قرار گرفته است؛ ترانزیستورهایی که با سرعت عملیاتی ما فوق تصور فعالیت میکنند.
شاید تفاوت معماری و زیرساخت کارتهای گرافیکی برای همهی کاربران جذاب نباشد. اکثر آنها با اعتماد به بررسیهای موجود در اینترنت یا بنچمارکها، محصولی را خریداری میکنند و عموما هم نیازهایشان بهخوبی برطرف میشود. با این حال برخی از کاربران و کارشناسان به جزئیات عملکردی و معماری سختافزارهای گرافیکی اهمیت میدهند. بهعنوان مثال آنها تمایل دارند تا تفاوت قلب تپندهی کارت گرافیک Radeon RX 5700 را با خانوادهی GeForce RTX درک کنند. در ادامهی این مطلب زومیت، بررسی عمیقی روی این پردازندههای گرافیکی تحولآفرین داریم و جدیدترین معماری پردازندههای AMD و انویدیا را بررسی میکنیم: Navi در برابر Turing.
آناتومی پردازندههای گرافیکی مدرن
پیش از آنکه به بررسی عمیق ساختار کلی تراشهها و سیستمها بپردازیم، نگاهی کلی به ساختار پردازندههای گرافیکی (GPU) مدرن خالی از لطف نخواهد بود. سهم عمدهای از ساختار این پردازندهها، محاسبهگرهای ممیز شناور هستند. به بیان دیگر آنها فقط عملیات ریاضی را در مقادیر اعشاری و کسری انجام میدهند. درنتیجه هر پردازندهی گرافیکی باید یک بخش منطقی برای انجام چنین وظایفی داشته باشد که بهنام FF ALU یا Floating Point Arithmetic Logic Units شناخته میشود. در اکثر نوشتهها از عبارت اختصاری FPU برای این عملگرهای منطقی استفاده میشود.
همهی محاسباتی که توسط پردازندهی گرافیکی انجام میشود، در واحد ممیز شناور نیستند. درنتیجه باید یک ALU برای محاسبات ریاضی اعداد صحیح (کامل) هم وجود داشته باشد. در برخی موارد همان واحد قبلی چنین عملیاتی را هم انجام میدهد.

واحدهای منطقی که در بالا به آنها اشاره شد، نیاز به بخشی برای سازماندهی دارند. بهبیان دیگر بخشی برای رمزگشایی ارتباطها باید وجود داشته باشد تا واحدهای منطقی را مشغول کند. برای این منظور حداقل به یک گروه از واحدهای منطقی اختصاصی نیاز خواهد بود. گروه مذکور برخلاف ALUها قابلیت برنامهریزی را به کاربر نهایی نمیدهد، بلکه تولیدکنندهی سختافزار آن را برای مدیریت توسط پردازندهی گرافیکی و درایورهای مرتبط، طراحی میکند.
برای ذخیرهسازی دستورهای عملکردی و دادههایی که باید پردازش شوند، باید زیرساخت حافظه هم در سختافزار وجود داشته باشد. در سادهترین سطح ساختار حافظه، دو نوع زیرساخت طراحی میشود: حافظهی نهان یا کش و بخشی نیز بهعنوان حافظهی محلی در نظر گرفته میشود. بخش اول در داخل پردازندهی گرافیکی قرار میگیرد و SRAM نامیده میشود. این نوع از حافظه سرعت بالایی دارد، اما بخش زیادی از الگوی پردازنده را به خود اختصاص میدهد. حافظهی محلی بهنام DRAM شناخته میشود و عملکرد کندتری دارد. بهعلاوه آن را در پردازندهی گرافیکی تعبیه نمیکنند. اکثر کارتهای گرافیکی امروزی حافظهی محلی را بهصورت ماژولهای GDDR DRAM دارند.
رندر گرافیکهای سهبعدی درنهایت به وظایف اضافی هم نیاز پیدا میکند تا بافتها و اجسام را به بهترین نحو نمایش دهد. چنین عملکردهایی مانند واحدهای عملکردی و کنترلی، بهصورت طبیعی توابع ثابت محسوب میشوند. وظایف آنها و چگونگی انجام کاملا برای کاربرانی که از پردازندهی گرافیکی استفاده کرده یا برای آن برنامهنویسی میکنند، شفاف خواهد بود.
برای درک بهتر پردازندههای گرافیکی، در ادامه براساس تعاریف بالا یک GPU فرضی میسازیم:
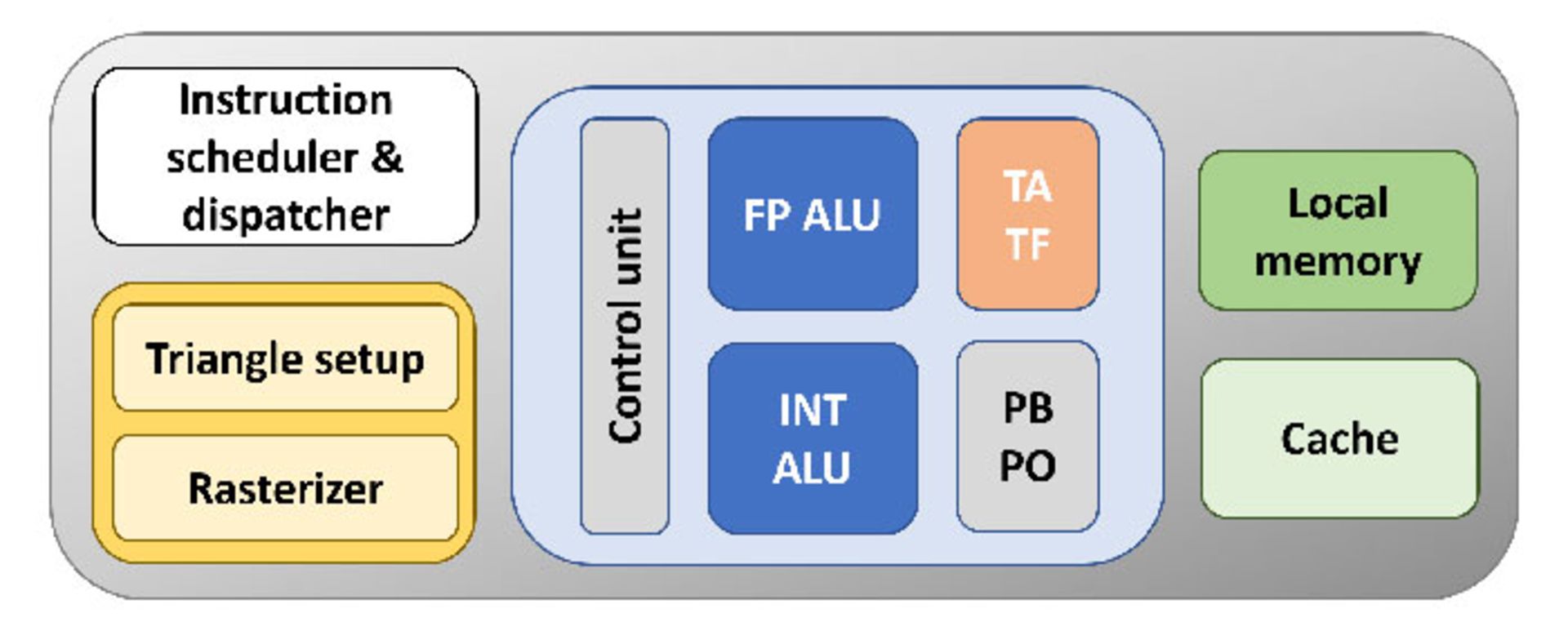
در تصویر بالا بلوک نارنجی واحدی است که بافتها را مدیریت و طراحی میکند و بهنام Texture Mapping Unit یا TMU (واحد بافت نگاشت) شناخته میشود. بخش TA یا Texture Addressing موقعیتهای حافظه را برای استفادهی حافظهی پنهان و محلی میسازد. بخش دیگر یعنی TF یا Texture Fetch مقادیر بافتها را از حافظه دریافت کرده و با هم ترکیب میکند. امروزه واحدهای TMU تقریبا در محصول همهی تولیدکنندهها به هم شبیه هستند. آنها توانایی مشابه شناسایی، نمونهسازی و ترکیب چندین بافت را در هر چرخهی عملکرد GPU دارند.
بلوک زیرین مقادیر رنگ را برای پیکسلهای هر فریم مشخص میکند. بهعلاوه نمونهسازی (توسط واحد PO) و ترکیب (توسط واحد PB) مقادیر رنگ نیز در این بلوک انجام میشود. همین بلوک برای انجام عملیات حذف پلگی هم به کار گرفته میشود. نام بلوک مذکور Render Output Unit یا Render Backend است که بهصورت اختصار ROP (واحد خروجی رندر) یا RB خوانده میشود. این بلوک هم مانند TMU بهنوعی استاندارد شده است و توانایی مدیریت چندین پیکسل را در هر چرخهی عملیات پردازنده دارد.
پردازندهی گرافیکی سادهای که در بالا شرح دادیم، حتی با توجه به استانداردهای ۱۳ سال پیش هم عملکرد واقعا بدی خواهد داشت. در پردازندهی ما از هر واحد FPU، TMU و ROP تنها یک عدد وجود دارد. درحالی که پردازندههای سال ۲۰۰۶ همچون GeForce 8800 GTX از واحدهای فوق به ترتیب ۱۲۸، ۳۲ و ۲۴ عدد داشتند. درنتیجه برای بهبود عملکرد پردازندهی گرافیکی مدل، باید تغییراتی در آن ایجاد کنیم.
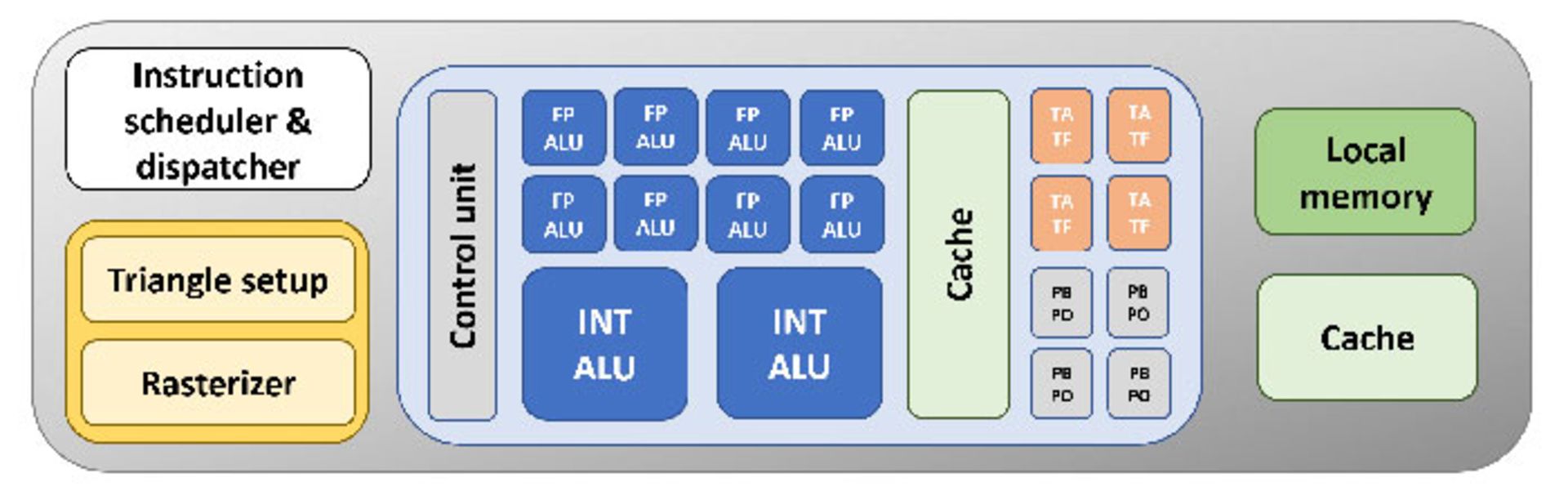
در تصویر بالا و در ادامهی مدلسازی پردازندهی گرافیکی، ما هم با اضافه کردن بخشهای جدید، محصول خود را بهروزرسانی کردیم. بهبیاندیگر اکنون تراشه توانایی پردازش دستورالعملهای بیشتری را بهصورت همزمان خواهد داشت. بهعلاوه برای افزایش پردازش همزمان، حافظهی کش را نیز کمی افزایش داده، اما این بار آن را در کنار واحدهای منطقی قرار دادیم. هرچه حافظهی کش به زیرساخت محاسباتی نزدیکتر باشد، در شروع عملیات اجرایی سریعتر عمل خواهد کرد.
مشکل اصلی طراحی جدید این است که تنها یک واحد کنترلی برای مدیریت ALUهای اضافه وجود دارد. اگر بلوکهای بیشتری برای این بخش داشتیم، عملکرد پردازنده بهتر میشد. بلوکهایی که هرکدام توسط کنترلر مجزای خود مدیریت شوند. درنتیجه عملیات بسیار متنوع و متعدد بهصورت همزمان مدیریت و کنترل میشود.
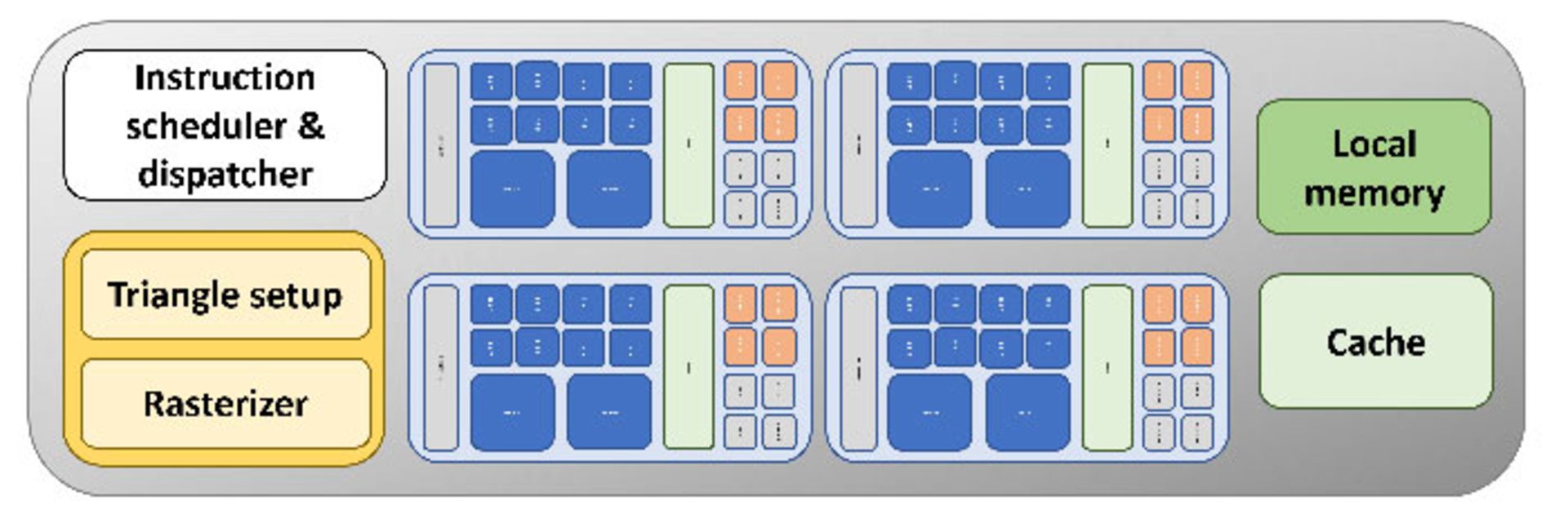
تصویر بالا نمونهی نزدیکتری به واقعیت نشان میدهد. واحدهای ALU مجزا که هرکدام مجهز به TMU و ROP اختصاصی هستند و بخشهایی از حافظهی سریع کش به آنها اختصاص داده شده است. در طراحی بالا، از هر بخش دیگر تنها یک عدد در ساختار GPU دیده میشود، اما بههرحال زیرساخت اصلی تفاوت آنچنانی با پردازندههای گرافیکی امروزی در کامپیوترهای شخصی و کنسولهای بازی ندارد.
Navi در برابر Turing: پردازندههای گرافیکی گودزیلا
پس از درک اولیه از ساختار پردازندههای گرافیکی، نوبت به مقایسهی جدیدترین معماری آنها یعنی Navi در برابر Turing میرسد. برای انجام مقایسه، تصاویری واقعی هم از بخشهای اصلی پردازندهها با هم مقایسه میشود که برای درک بهتر بزرگنمایی و شفافسازی شدهاند.
در سمت چپ تصویر زیر جدیدترین پردازندهی AMD را مشاهده میکنید که در کارتهای سری RX 5700 از آن استفاده شده است. این تراشه به نام Navi شناخته میشود و برخی منابع از نام Navi10 برای آن استفاده میکنند. معماری گرافیکی آن نیز RDNA نام دارد. در سمت راست تصویر پردازندهی TU102 شرکت انویدیا را مشاهده میکنیم که با جدیدترین معماری Turing ساخته شده است. شایان ذکر است تصاویر زیر، مقیاس برابر ندارند. مساحت ناوی ۲۵۱ میلیمتر مربع و مساحت پردازندهی انویدیا ۷۵۲ میلیمتر مربع است. در همین مقایسهی اولیه میبینیم که انویدیا مساحت بزرگتری را به پردازندهی گرافیکی اختصاص میدهد، اما تفاوت عملکردی آنها آنچنان زیاد نیست.

هر دو پردازنده تعداد بسیار زیادی ترانزیستور دارند. پردازندهی AMD دارای ۱۰/۳ و پردازندهی انویدیا دارای ۱۸/۶ میلیارد ترانزیستور است. البته TU102 در هر میلیمتر مربع حدود ۲۵ میلیون ترانزیستور دارد که در مقایسه با ۴۱ میلیون ترانزیستور در هر میلیمتر مربع ناوی، عدد پایینی محسوب میشود. دلیل تفاوت این است که با وجود یکی بودن سازندهی تراشهها (TSMC)، نود پردازشی تولیدی آنها با هم تفاوت دارد: انویدیا تورینگ در خط تولید قدیمیتر ۱۲ نانومتری ساخته شد، اما AMD سفارش خود را در خط جدیدتر و هفت نانومتری ساخته است.
با نگاه به تصاویر واقعی قالب پردازندهها اطلاعات زیادی از معماری آنها دریافت نمیکنیم. درنتیجه برای بررسی بهتر، دیاگرام بلوکی را بررسی میکنیم که توسط شرکتهای سازنده ارائه میشود:
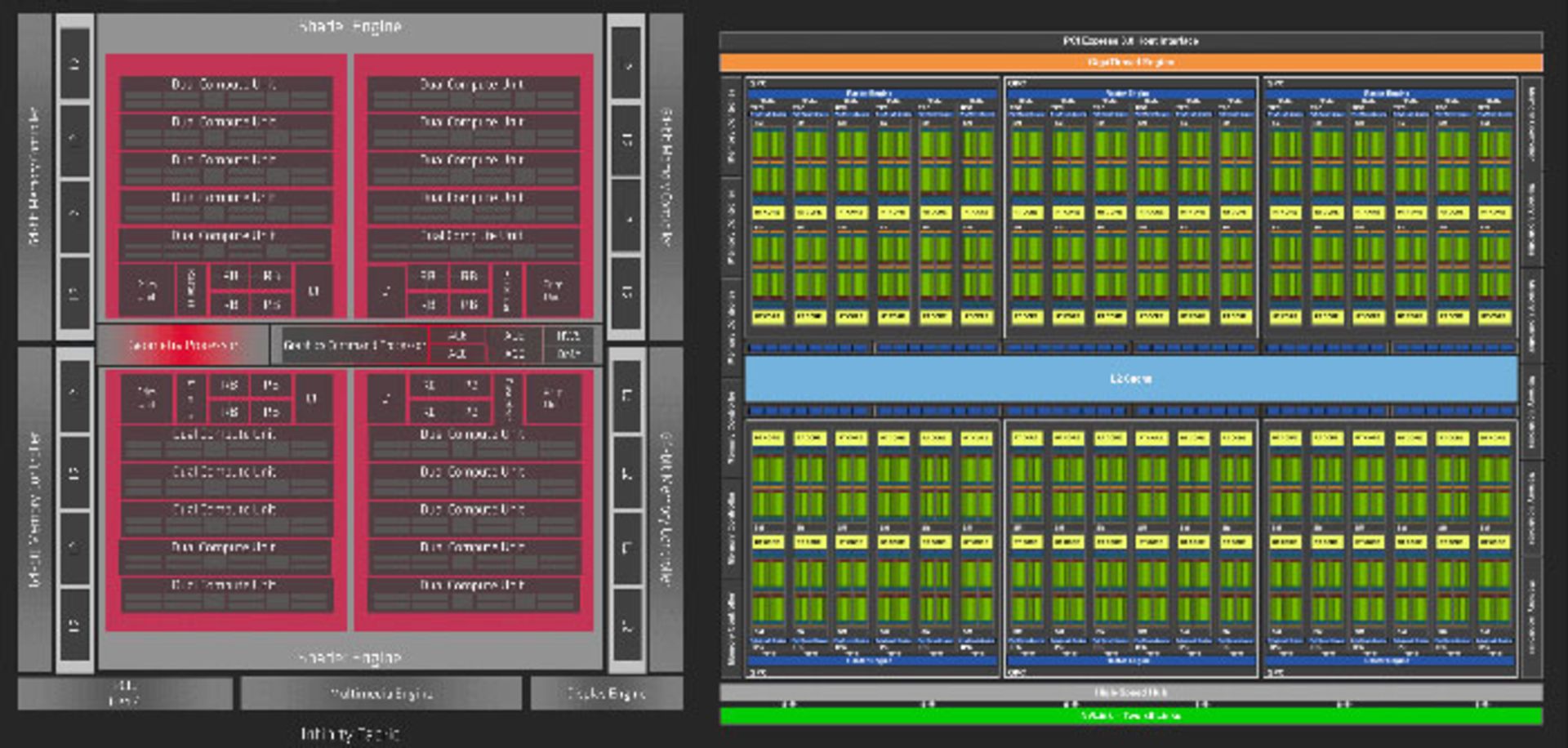
تصاویر بالا نمودهای ۱۰۰٪ واقعی از الگوی پردازندهها نیستند، اما اگر آنها ۹۰ درجه بچرخانیم، بلوکهای متعدد و خطوط مرکزی آنها بهخوبی مشاهده میشود. با نگاهی کلی متوجه میشویم که هر دو معماری، بلوکهایی مشابه پردازندهای دارند که در بخش قبلی بهعنوان نمونه طراحی کردیم. البته در معماریهای بالا، از همهی بخشها بلوکهای بیشتری داریم.
هر دو طراحی، رویکردی کاملا منظم را در سازماندهی بلوکها دارند. برای شروع، معماری ناوی را بررسی میکنیم که از دو بلوک (AMD نام Shader Engines را برای آنها استفاده میکند) تشکیل میشود. هر یک از بلوکهای مذکور به دو بلوک دیگر بهنام Asynchronous Compute Engines تقسیم میشود. هر یک از بلوکهای جدید هم شامل پنج بلوک دیگر هستند که از نام Workgroup Processors برای آنها استفاده میشود. درنهایت این بلوکها هم دارای دو واحد بهنامهای Compute Units یا CU (واحد محاسباتی) هستند.
تورینگ با فناوری ساخت ۱۲ نانومتری و ناوی با فناوری ۷ نانومتری ساخته میشود
در طراحی تورینگ، نام بلوکها و تعداد آنها با ناوی تفاوت دارد. البته زیرساخت و سلسلسه مراتب آنها به هم شبیه است. ۶ بخش بهنام Graphics Processing Clusters وجود دارد که هرکدام دارای ۶ بخش بهنام Texture Processing Clusters هستند و مجددا در هرکدام از آنها دو بلوک بهنام Streaming Multiprocessor داریم.
اگر هر پردازندهی گرافیکی را به یک کارخانهی بزرگ تشبیه کنیم که هر بخش، محصول متفاوت و مجزایی را از مواد اولیهی یکسان تولید میکند، ساختاربندی بالا منطقی بهنظر میرسد. مدیرعامل کارخانه، همهی جزئیات عملکردی را به بخشهای اجرایی ارسال میکند. سپس دستورها به وظایف و روندهای کاری مجزا تقسیم میشوند. با داشتن واحدهای مستقل متعدد در کارخانه، بازدهی نیروی کاری هم افزایش مییابد. در پردازندههای گرافیکی روندی مشابه رخ میدهد و از نام Scheduling (بهترین تعریف: زمانبندی) برای آن استفاده میشود.
زمانبندی و ارسال
اگر به ساختار و روند رندر کردن بازیهای سهبعدی دقت کنیم، به این نتیجه میرسیم که پردازندههای گرافیکی چیزی بیش از یک ماشین حساب فوق سریع نیستند. این قطعات سختافزاری، عملیات ریاضی را با سرعتی بالا روی میلیونها قطعه داده انجام میدهند. در پردازندههای Navi و Turing از ساختارهای Single Instruction Multiple Data یا SIMD استفاده میشود. البته برای تعریف بهتر باید از اصطلاح Single Instruction Multiple Thread یا SIMT استفاده شود.
یک بازی مدرن سهبعدی، صدها و بعضا هزاران رشتهی پردازشی (ترد) تولید میکند، چون تعداد رئوس و پیکسلهایی که باید پردازش شوند، بسیار زیاد است. برای انجام پردازش در کمترین زمان ممکن (میکرو ثانیه) باید حداکثر واحدهای محاسبهگر منطقی (ALU) را مشغول به پردازش کنیم. درواقع نباید هیچگونه خللی بهخاطر قرار نگرفتن دادهها در موقعیت مناسب یا نبود منابع پردازشی، ایجاد شود.
ناوی و تورینگ عملکرد مشابهی در پردازش دارند. در هر دوی آنها یک واحد مرکزی تمام رشتهها را دریافت میکند و زمانبندی و ارسال آنها را انجام میدهد. در تراشهی AMD، وظیفهی مذکور توسط Graphics Command Processor انجام میشود و در محصول انویدیا، این بخش GigaThread Engine نام دارد. رشتهها بهصورتی مدیریت و تنظیم میشوند که هر دستورالعمل حداکثر شامل ۶۴ رشتهی پردازشی است.
AMD هر مجموعهی رشتهها را Wave (جبههی موج) مینامد و انویدیا از نام Warp برای آنها استفاده میکند. AMD بر هر جبههی موج ۳۲ رشته را بارگیری میکند و هر واحد محاسباتی (با دو SIMD هر یک شامل ۳۲ محاسبهگر منطقی) توانایی پردازش آیتمهای کاری دو Wave با مجموعاً ۶۴ رشته را دارد. تمامی ۶۴ رشته بدین ترتیب در یک سیکل کلاک پردازش میشود. البته در صورت انجام فرایند روی یک Wave واحد با ۳۲ رشته زمان دو برابر میشود. در معماری تورینگ، واحد محاسباتی بهصورت همزمان با چهار Warp کار میکند. در هر دو معماری، Wave یا Warp مستقل هستند. بهبیاندیگر پیش از شروع پردازش هریک از آنها، نیازی به اتمام پردازش گروه قبلی نیست.
با نگاهی به همین تعاریف اولیه، متوجه تفاوت نهچندان زیادی میان Navi و Turing میشویم. هر دوی آنها برای مدیریت و پردازش تعداد بسیار زیادی رشته طراحی شدهاند تا عملیات رندر و فرایندهای پردازش را انجام دهند. دراینمیان برای درک بهتر تفاوت پردازندهها، باید به آنچه رشتهها را پردازش میکند، دقت کنیم.
تفاوت در اجرا: RDNA در برابر CUDA
AMD و Nvidia در واحدهای سایهزنی یکپارچهی خود رویکردهای کاملا متفاوتی را در پیش میگیرند. البته نامگذاریها و اصطلاحهای آنها شباهت زیادی به هم دارد. واحدهای اجرایی انویدیا (بهنام هستههای CUDA شناخته میشوند) طبیعت اسکالر (Scalar) دارند. بهبیان دیگر هر واحد، یک عملیات ریاضی را روی یک جزء داده انجام میدهد. درمقابل واحدهای AMD (موسوم به Stream Processors) روی بردارها (Vector) کار میکنند. درواقع آنها یک عملیات ریاضی را روی اجزای دادهی متعدد پیادهسازی میکنند. بهعلاوه واحد محاسباتی این شرکت برای عملیات اسکالر یک واحد اختصاصی دارند.
پیش از نگاه نزدیکتر به واحدهای اجرایی پردازندههای گرافیکی، ابتدا نگاهی به تغییرات AMD روی واحدهای پردازش گرافیکی خود در خلال سالیان گذشته خواهیم داشت. در هفت سال گذشته، کارتهای گرافیکی رادئون از معماری بهنام Graphics Core Next یا GCN استفاده کردند. البته هر تراشهی جدید تحت بازبینی و تغییرات متعدد طراحی قرار گرفت، اما زیرساخت و اصول آنها یکسان میماند. این شرکت با عرضهی معماری جدید، خلاصهای از تاریخچهی معماری پردازندههای گرافیکی خود هم منتشر کرد که در تصویر زیر میبینیم:
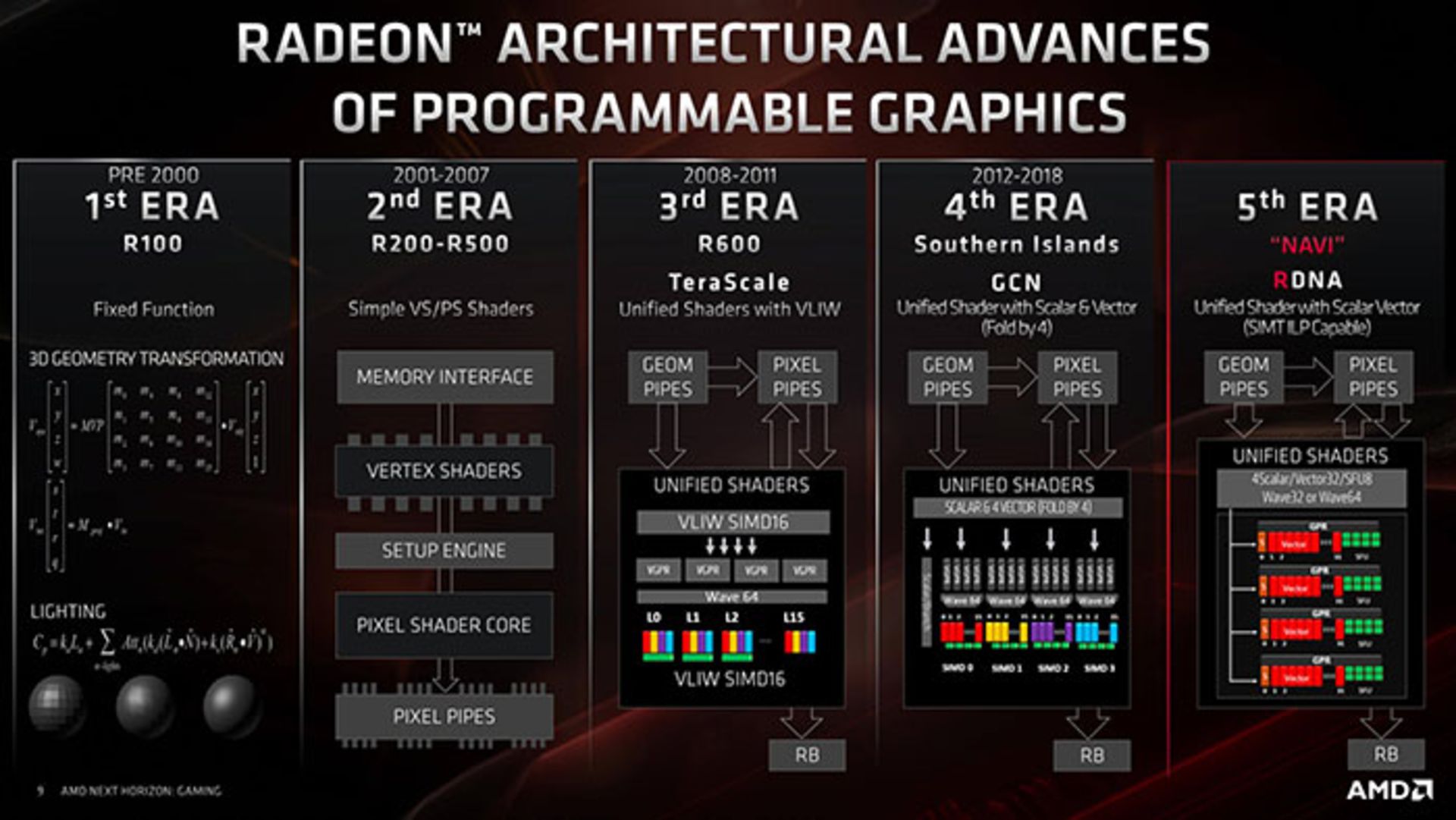
GCN بهنوعی یک نسخهی تکاملیافته از TeraScale بود که امکان پردازش Waveهای بیشتر را در زمان یکسان ایجاد میکرد. مشکل اصلی TeraScale، دشواری برنامهنویسی برای آن بود که برای حصول بهترین نتیجه، نیاز به روندهای بسیار خاص داشت. GCN چالش مذکور را حل کرده و پلتفرمی در دسترستر ارائه کرد.
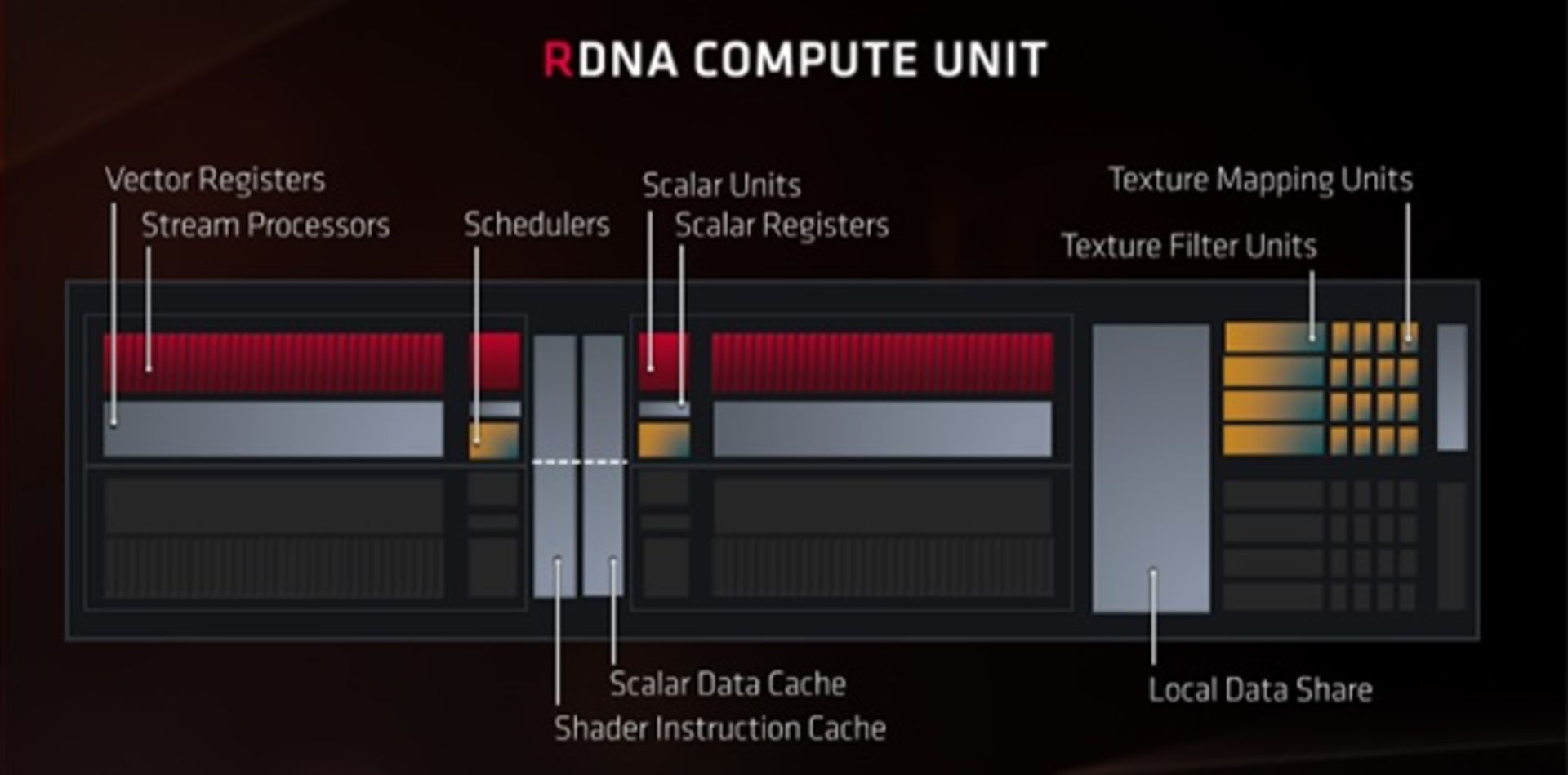
واحدهای محاسباتی (CU) که امروز در معماری ناوی مشاهده میکنیم، نسخههایی بسیار بهینهسازی شده از GCN هستند و بخشی از از فرایند بهینهسازی AMD در کارتهای گرافیک محسوب میشوند. هر واحد محاسباتی شامل دو مجموعه از آیتمهای زیر میشود:
هر واحد محاسباتی علاوه بر موارد بالا دارای چهار واحد بافتدهی (Texture Unit) هم هست. بهعلاوه واحدهای دیگری هم در داخل زیرساخت وجود دارند تا خواندن و نوشتن داده را از حافظهی کش مدیریت کنند. البته آنها را در تصویر زیر مشاهده نمیکنید.
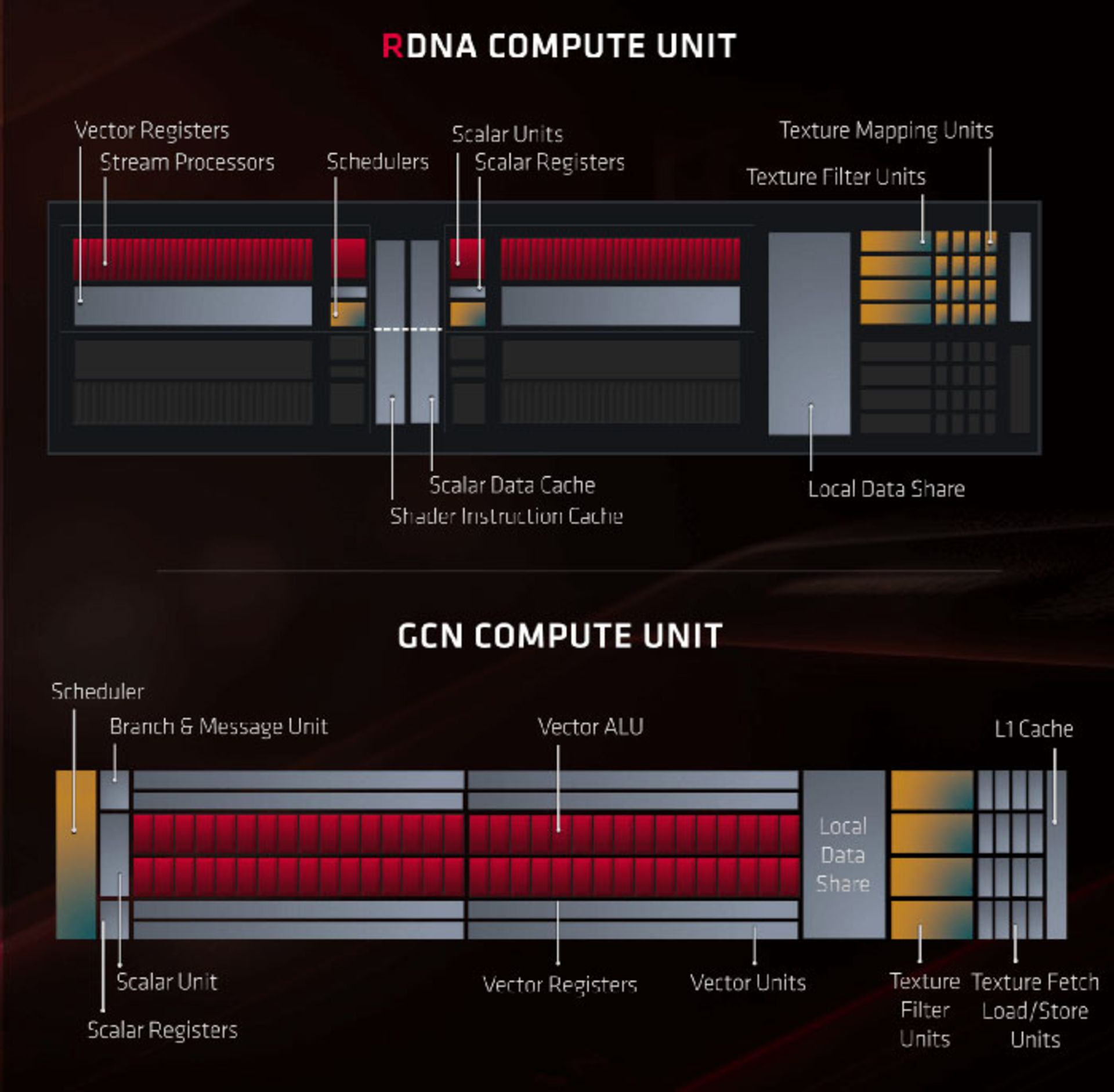
مقایسهی اولیهی واحد محاسباتی RDNA و GCN تفاوت چندانی را نشان نمیدهد، اما مدیریت و تنظیمگری فرایندها تفاوتهای اصلی را شکل میدهد. در اولین تفاوت، هر یک از ۳۲ بخش SP (یا SIMD32) در معماری جدید، واحد زمانبند دستورالعمل (Scheduler) اختصاصی خود را دارد. درمقابل، معماری GCN برای چهار دستهی ۱۶ تایی از SPها (یا SIMD16)، تنها یک زمانبند ارائه میکند.

تغییر یادشده اهمیت زیادی دارد؛ چون در معماری جدید میتوان هر جبههی موج متشکل از ۳۲ رشته را در هر چرخهی پردازش به یک دسته SP یا SIMD32 ارسال کرد. بهعلاوه معماری RDNA این امکان را ایجاد میکند تا واحدهای برداری دستورالعملهای متشکل از ۱۶ رشته را با سرعتی دوبرابر مدیریت کنند و همچنین گروههای ۶۴ رشتهای نیز با نرخ نصف مدیریت میشوند. درنتیجه تمام کدهای اختصاصی نوشته شده برای معماریهای نسل قبل، در معماری جدید هم پشتیبانی میشوند.
در طراحی جدید برای مدیریت انواع عملیات اسکالر، دو برابر واحد محاسباتی وجود دارد. درواقع در این طراحی تنها تعداد SFU یا Special Function Unit کاهش مییابد که وظیفهی انجام عملیات ریاضی بسیار خاص را بر عهده دارد. منظور از عملیات ریاضی بسیار خاص در اینجا فرایندهایی همچون مثلثات، وارون ضربی و ریشه دوم هستند. در معماری RDNA در مقایسه با GCN، تعداد کمتری از چنین عملیاتهای ریاضی انجام میشود، اما بههرحال میتوان این عملیاتها را روی مجموعهدادههایی با ابعاد دوبرابر معماری قبلی انجام داد.
AMD در هفت سال گذشته توسعههای قابلتوجهی روی معماری پردازندههای گرافیکی لحاظ کرده است
تغییرات معماری AMD که در بالا به آن اشاره کردیم، برای توسعهدهندههای بازی اهمیت زیادی دارند. کارتهای گرافیک قدیمی رادئون ظرفیت کارایی بالایی داشتند، اما بهرهبرداری از آنها بسیار دشوار بود. امروز AMD قدم بزرگی را در مسیر کاهش تأخیر در اجرای دستورالعملهای پردازشی برداشته است. بهعلاوه قابلیت سازگاری نیز برای راحتی کار با نسخههای قبلی برنامههای مبتنی بر GCN در معماری جدید پیشبینی شده است.
اکنون این سؤال ایجاد میشود که تغییرات جدید AMD چه تأثیری بر بازار پردازش حرفهای و کاربری حرفهای گرافیک کامپیوتری دارند؟ آیا تغییرات به نفع آنها خواهند بود؟ قطعا پاسخ کوتاه به سؤال مذکور، مثبت خواهد بود. بهعنوان مثالی برای مقایسه، نسخهی کنونی از تراشههای ناوی (که در محصولاتی همچون Radeon RX 5700 XT دیده میشوند) تعداد پردازندههای جریانی (SP) کمتری نسبت به طراحی قبلی یعنی Vega دارند، اما از لحاظ کارایی بهراحتی محصولاتی همچون Radeon RX Vega را پشت سر میگذارند.
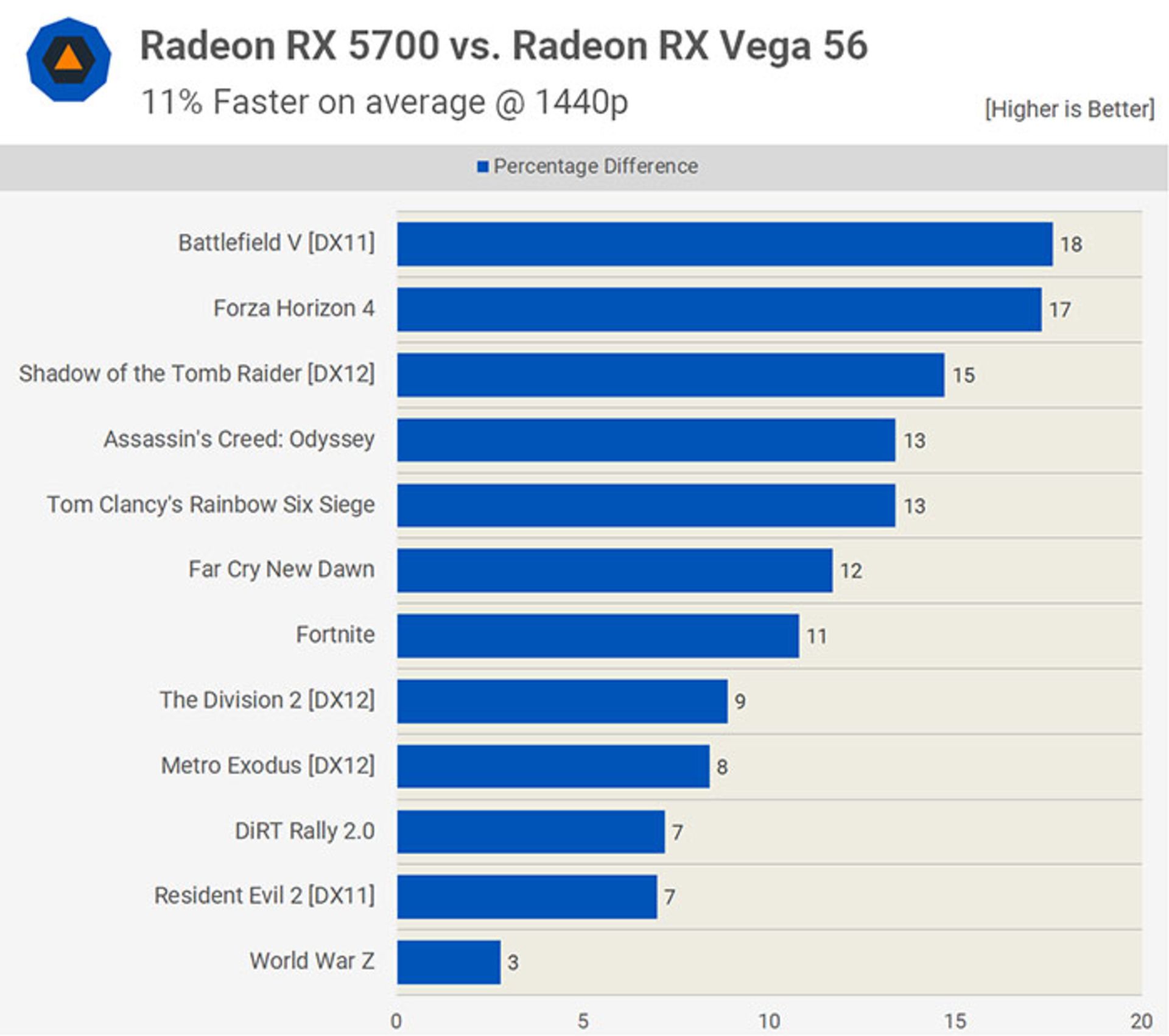
بخشی از برتری کارت گرافیک RX 5700 نسبت به RX Vega 56 بهخاطر سرعت کلاک بالاتر آن به دست میآید (سرعت بالاتر یعنی پیکسلهای بیشتری در واحد ثانیه در حافظهی محلی نوشته میشوند). البته کارتهای جدید از نظر سقف عملکرد عدد صحیح (Integer) و ممیز شناور کاهش ۱۵ درصدی دارند. درنهایت مجموع کارایی کارت ناوی نسبت به وگا، بهبود ۱۸ درصدی را نشان میدهد.
برنامههای رندر حرفهای و دانشمندان علوم کامپیوتر که الگوریتمهای پیچیده را اجرا میکنند، قطعا کاربری متفاوتی نسبت به گیمرها از پردازندهی گرافیکی استخراج خواهند کرد. البته وقتی عملیات اسکالر، برداری و ماتریسی در موتورهای بازی با سرعت بالاتری پردازش شود، قطعا در کاربردهای پردازشی حرفهای هم نقش خود را نشان میدهد. درحالحاضر نمیدانیم که کدامیک از برنامهها و تغییرات AMD در کارتهای گرافیک با هدف بازار حرفهای هستند. بههرحال آنها میتوانند با پایبندی به معماری وگا و تنها بهبود طراحی، علاوه بر صرفهجویی در هزینههای تولید، نیازهای آن بخش از بازار را هم رفع کنند؛ اما با توجه به پیشرفتهای عالی Navi نسبت به نسل قبل، تغییر مسیر تمامی بخش تولید به سمت معماری جدید، منطقیتر خواهد بود.
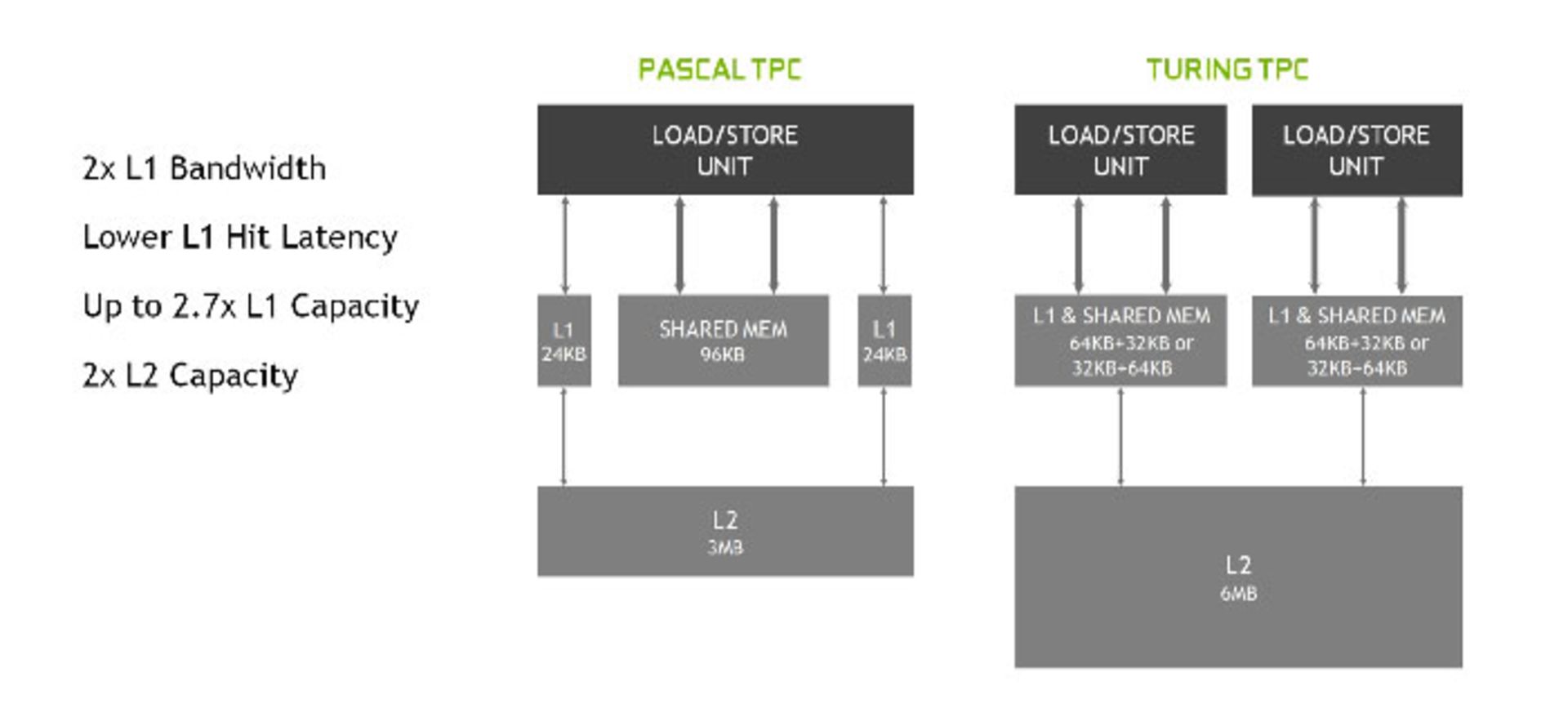
طراحی پردازندههای گرافیکی انویدیا نیز از سال ۲۰۰۶ تاکنون روند تکاملی مشابهی را طی کرده است. این شرکت در آن سال سری GeForce 8 را به بازار معرفی کرد. تغییرات آنها نسبت به رقیب، آنچنان اساسی و زیرساختی نبوده است. سری کارتهای گرافیک مذکور از انویدیا برای اولینبار از معماری Tesla استفاده میکردند که اولین رویکرد سایهزنی یکپارچه را در معماری اجرایی پیادهسازی میکرد. در تصویر زیر، تغییرات ساختار بلوکهای SM را از معماری پیش از تسلا یعنی Fermi تا معماری کنونی تورینگ (از چپ به راست Fermi, Kepler, Maxwell, Volta) مشاهده میکنیم.
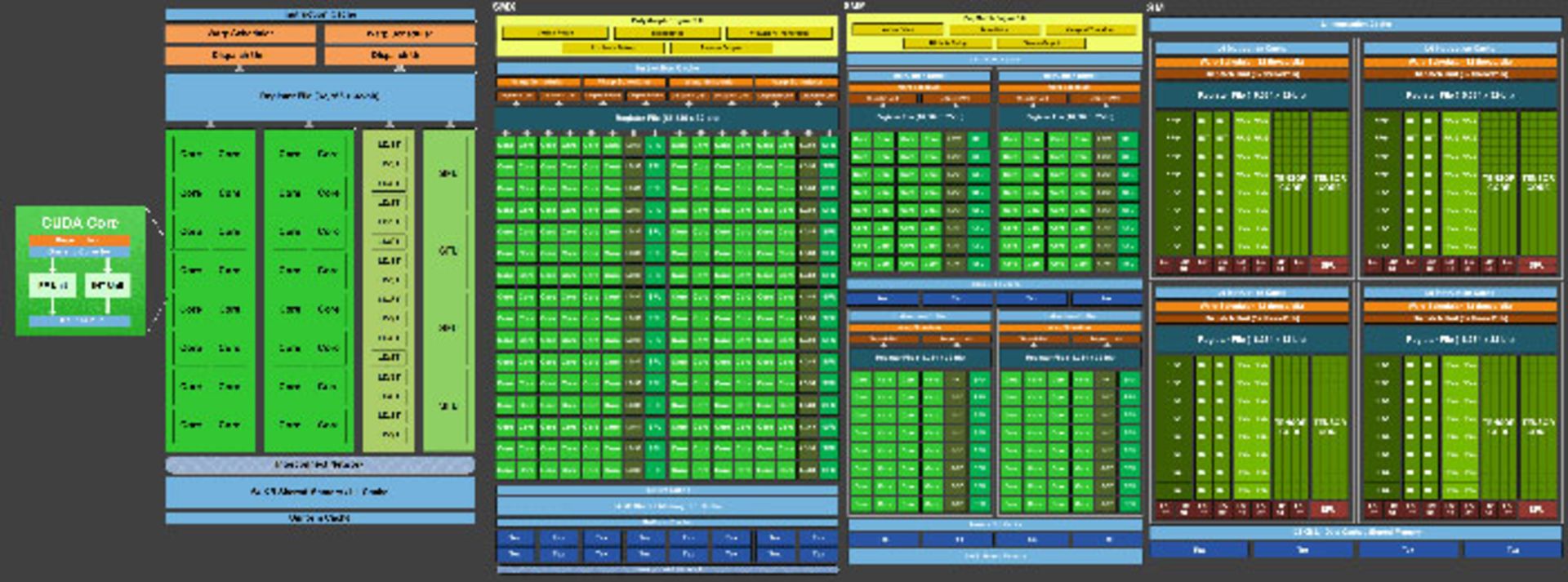
همانطور که قبلا اشاره کردیم، هستههای CUDA رویکرد اسکالر دارند. آنها در هر چرخهی پردازش یک دستورالعمل صحیح و یک دستورالعمل شناور را روی یک جزء داده انجام میدهند. فراموش نکنید که هر دستورالعمل میتواند تا چند سیکل کلاک را اشغال کند. بههرحال واحدهای زمانبندی دستورالعملها را بهصورتی گروهبندی میکنند که توانایی انجام عملیات برداری را داشته باشند. رویکردی که درنهایت به نفع برنامهنویس خواهد بود. با نگاهی به پیشرفت پردازندههای انویدیا به این نتیجه میرسیم که علاوه بر افزایش واحدهای موجود در پردازنده، روش ساختاردهی و برنامهریزی آنها نیز بهبود یافته است.
در معماری Kepler، تراشه شامل پنج واحد GPC بود که هرکدام سه بلوک SM (یا Streaming Multiprocessor) داشتند. پس از رونمایی از معماری Pascal، شاهد تقسیم واحدهای GPC به TPC بودیم که در هریک از آنها دو واحد SM وجود داشت. این تقسیمبندی مانند معماری ناوی اهمیت زیادی دارد. تقسیمبندی مذکور این امکان را ایجاد میکند که کل پردازندهی گرافیکی در حداکثر کارایی وظایف خود را انجام دهد. درنتیجهی تقسیمبندیهای مذکور، گروههای متعددی از دستورالعملهای مستقل بهصورت موازی پردازش میشوند و درنهایت کارایی سایهزنی و پردازش پردازنده افزایش مییابد.
در تصویر زیر معادل تورینگ یک واحد محاسباتی RDNA ترسیم شده است:
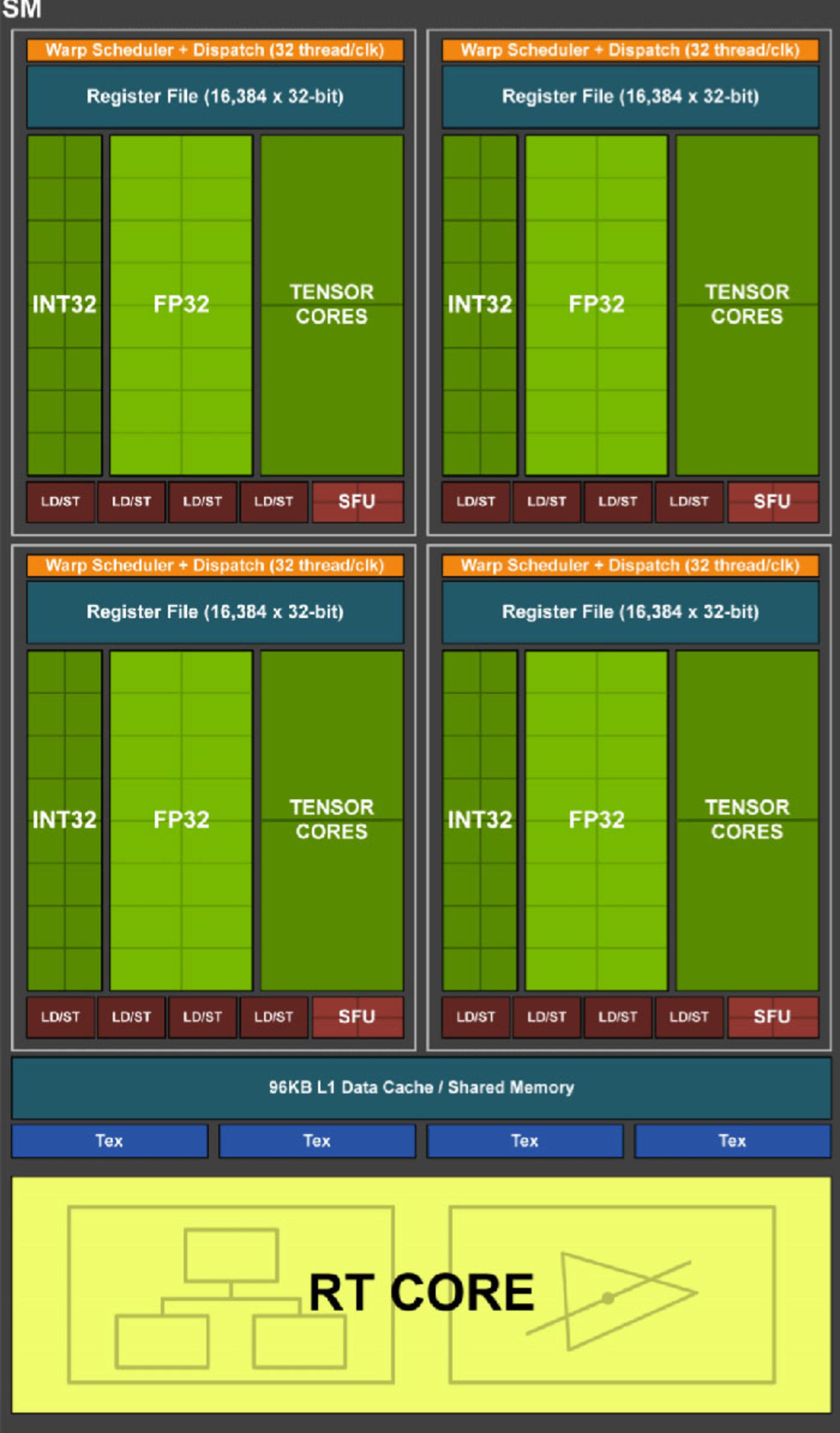
هر واحد SM در معماری تورینگ دارای چهار بلوک پردازشی است که هرکدام از بخشهای زیر تشکیل شدهاند:
علاوه بر موارد بالا در هر SM دو واحد FP64 هم وجود دارد، اما انویدیا در دیاگرامهای بلوکی خود آنها را نمایش نمیدهد. هر واحد SM هم متشکل از چهار واحد بافت میشود که سیستمهای فیلترینگ و شناسایی بافتها را شامل میشوند. بهعلاوه یک هستهی Ray Tracing (یا RT) نیز در هر واحد SM وجود دارد.
واحدهای ALU از نوع FP32 و INT32 توانایی فعالیت بهصورت همزمان و موازی دارند. این قابلیت اهمیت زیادی دارد چون اگرچه موتورهای رندر سهبعدی اکثرا به محاسبات ممیز شناور نیاز دارند، باز هم عملیات اعداد صحیح هم باید توسط هستههای پردازشی انجام شوند.
هستههای تنسور (Tensor Cores) واحدهای ALU هستههایی اختصاصی هستند که انجام عملیات ماتریسی را بر عهده میگیرند. ماتریسها به بیان ساده ردیفهای دادهای مربعی هستند و تنسورها در ماتریسهای ۴*۴ فعالیت میکنند. هستهها بهگونهای طراحی شدهاند تا دادههای FP16، INT8 و INT4 را مدیریت کنند. بهعلاوه مدیریت دادهها باید بهنوعی انجام شود تا حداکثر ۶۴ عملیات شناور FMA را در هر چرخهی پردازش انجام دهد. در اینجا FMA به اختصار برای عملیات Fused multiply-then-add به کار میرود.
واحدهای اجرایی در سطوح پایینتر معماری، شباهت زیادی به یکدیگر دارند
محاسباتی که در بالا شرح دادیم، اکثرا در کاربردهایی همچون شبکههای عصبی و فرایندهای استنباطی استفاده میشوند. چنین عملیاتی کمتر در کاربردهایی همچون بازیهای سهبعدی دیده میشوند. در مواردی همچون الگوریتمهای تحلیل دادهی فیسبوک یا سیستمهای موجود در خودروهای خودران، نیاز شدیدی به چنین پردازشیهایی وجود دارد. معماری ناوی هم توانایی انجام محاسبات ماتریسی را دارد، اما برای انجام آن به تعداد زیادی واحد SP نیاز خواهد داشت. در سیستمهای مبتنی بر تورینگ، عملیات ماتریسی بهراحتی انجام میشود و بهصورت همزمان، هستههای CUDA فعالیتهای ریاضی دیگر را مدیریت خواهند کرد.
هستهی RT یکی دیگر از واحدهای مهمی است که در معماری تورینگ وجود دارد و الگوریتمهای ریاضی خاص را مدیریت میکند. این الگوریتمها بهصورت اختصاصی برای سیستم رهگیری پرتو (Ray Tracing) شرکت انویدیا استفاده میشوند. تحلیل کامل فرایندهای مذکور از حوصلهی این مقاله خارج است، اما بهصورت ساده میتوان هستهی RT را متشکل از دو سیستم دانست که بهصورت مجزا با سایر اجزای SM به فعالیت میپردازند.
مقایسهی تورینگ و ناوی در سطوح پایهای نشان میدهد که هردو دارای واحدهای اجرایی با قابلیتهای مشابه هستند. البته هریک از آنها رویکرد متفاوتی را برای انجام فرایند با قابلیتهای مذکور در پیش میگیرند. برای انتخاب طراحی بهتر، باید نحوهی استفاده از آنها را بررسی کنیم: برنامهای که رشتههای متعددی را با محاسبات برداری FP32 ایجاد میکند و وظایف متفرقهی زیادی ندارد، با معماری ناوی عملکرد بهتری خواهد داشت. درمقابل برنامهای که ترکیبی از محاسبات صحیح، شناور، اسکالر و برداری دارد، از انعطافپذیری تورینگ بهره خواهد برد.
زیرساخت حافظه
پردازندههای گرافیکی مدرن، پردازندههای جریانی هستند. بهبیاندیگر آنها بهگونهای طراحی شدهاند تا به اجرای مجموعهای از عملیاتها روی هر جزء از یک جریان داده اقدام کنند. درنتیجه این پردازندهها انعطافپذیری کمتری نسبت به پردازندههای مرکزی دارند و سلسلهمراتب حافظه هم باید بهصورت بهینهتری در آنها پیادهسازی شود. درواقع حافظه باید بهگونهای طراحی شود تا داده و دستورالعمل را در سریعترین حالت و صرفنظر از تعداد جریانها از ALU دریافت کند. در اثر پیشفرضهای بالا، GPU حافظهی کش کمتری نسبت به CPU دارد؛ چرا که دسترسی اجزای مختلف تراشه به حافظهی کش مهمتر از میزان این حافظه است.
انویدیا و AMD هردو از سطوح متعدد کش در داخل تراشه استفاده میکنند. ابتدا نگاهی به زیرساخت معماری ناوی خواهیم داشت:
در پایینترین سطح سلسلهمراتب حافظهی Navi دو بلوک از پردازندههای جریانی (SP) وجود دارند که ۲۵۶ کیلوبایت ثبات چندمنظورهی (General Purpose Register) برداری (موسوم به Register File) را بهکار میگیرند. این مقدار در معماری Vega هم دیده میشد، اما در آنجا شاهد چهار بلوک SP بودیم. تکمیل ظرفیت ثباتهای پردازنده خصوصا زمانیکه تعداد زیادی رشته در حال پردازش باشند، اثر منفی شدیدی روی کارایی خواهد داشت. درنتیجه در پایینترین سطح طراحی حافظهی ناوی شاهد بهبود قابلتوجهی نسبت به نسل قبل هستیم. بهعلاوه AMD حجم Register File اسکالر را نیز افزایش داده است. قبلا برای هر واحد اسکالر، حجم فایل، ۴ کیلوبایت بود که امروز به ۳۲ کیلوبایت برای هر واحد اسکالر میرسد.
در سطح بعدی دو واحد محاسباتی داریم که ۳۲ کیلوبایت کش L0 دستورالعملی و ۱۶ کیلوبایت کش دادهی اسکالر را به اشتراک میگذارند. البته هر CU کش L0 برداری اختصاصی با حجم ۳۲ کیلوبایت خواهد داشت. برای ارتباط همهی این حافطهها با بخشهای ALU از واحد ۱۲۸ کیلوبایتی Local Data Share استفاده میشود.
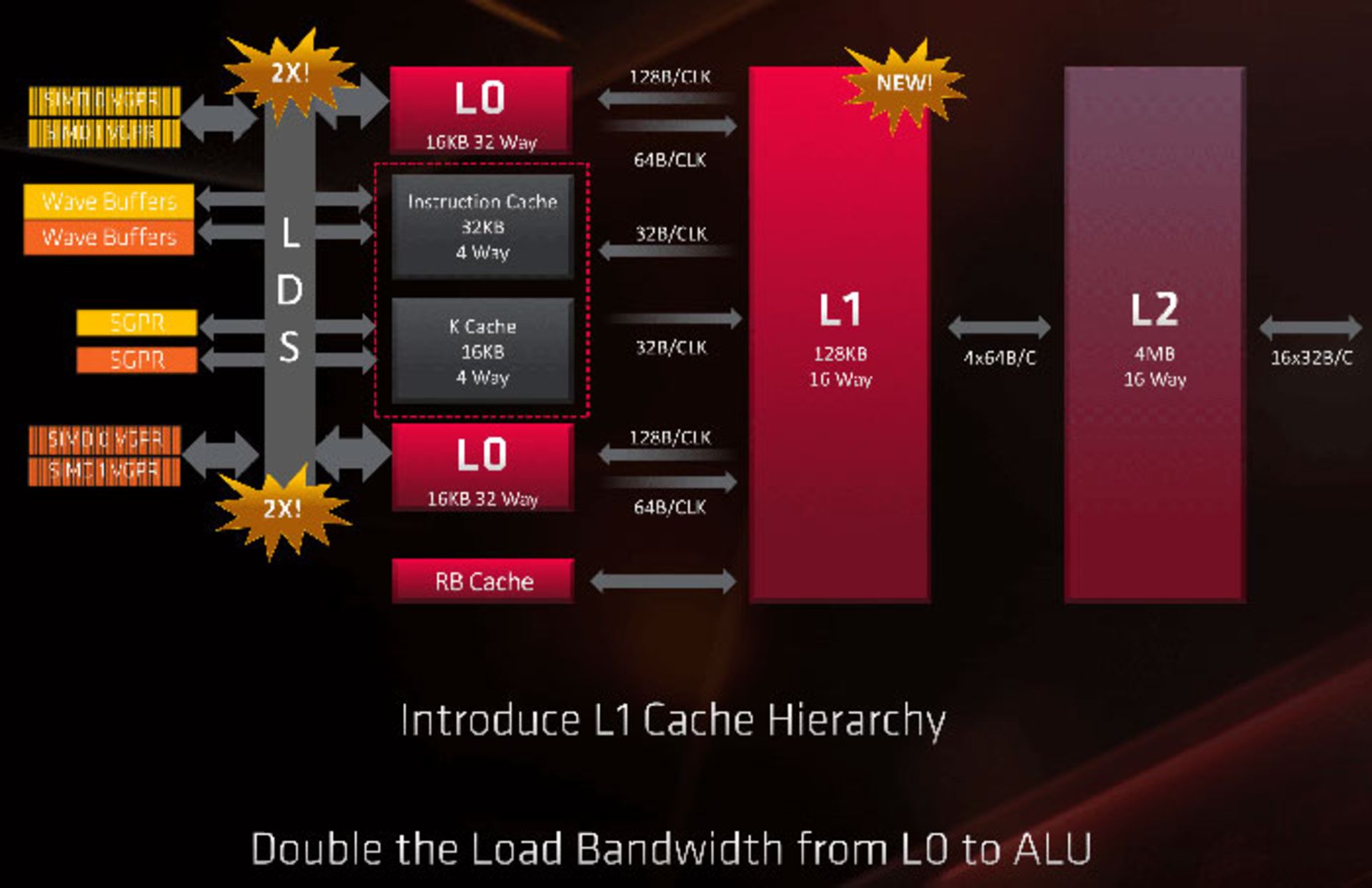
در معماری Navi، دو موتور محاسباتی یک پردازندهی گروهی را تشکیل میدهند و پنج عدد از آنها یک ACE میسازند. هر ACE به حافظهی اختصاصی کش L1 با حجم ۱۲۸ کیلوبایت دسترسی دارد. بهعلاوه کل پردازندهی گرافیکی با ۴ مگابایت حافظهی L2 پشتیبانی میشود. این حافظهی کش، به حافظههای L1 و دیگر بخشهای پردازنده متصل میشود.
توضیحات بالا بهصورت کلی نوعی از معماری اتصالات داخلی اختصاصی AMD را بهنام Infinity Fabric نشان میدهند. سیستم مذکور برای مدیریت ۱۶ کنترلر GDDR6 طراحی شده است. بهعلاوه Navi برای به حداکثر رساندن پهنای باند حافظه، از فشردهسازی حرفهای بین حافظههای L1, L2 و GDDR6 استفاده میکند.

همهی تغییرات بالا قدمی مثبت در جهت بهینهسازی عملکردی تراشههای AMD بودهاند. تراشههای قبلی هیچگاه حافظهی کش کافی در سطح پایین نداشتند. بهبیان ساده، اکنون با افزایش حافظهی کش به پهنای باند داخلی بیشتر میرسیم. بهعلاوه دستورالعملهای کمتری هم به توقف میرسند و مجموع اتفاقها، پردازندهای با کارایی بهتر را نتیجه میدهد.
انویدیا در ارائهی اطلاعات دقیق پیرامون سلسله مراتب حافظهی تورینگ، روند مناسبی ندارد. بههرحال در بخشهای قبلی مقاله دیدیم که هر واحد SM در معماری تورینگ به چهار بلوک پردازشی تقسیم میشود و هریک از آنها فایل رجیستر ۶۴ کیلوبایتی دارند. درنتیجه فایل رجیستر کوچکتری نسبت به ناوی در اختیار داریم. البته فراموش نکنید که ALU در معماری تورینگ طبعیت برداری ندارد و اسکالر است.
در سطح بعدی برای هر SM یک حافظهی اشتراکی ۹۶ کیلوبایتی داریم که میتواند بهصورت ۶۴ کیلوبایت کش دادهی L1 و ۳۲ کیلوبایت کش بافت استفاده شود. بهعلاوه میتوان از آن بهعنوان فضای ثبات مجزا استفاده کرد. در حالت Compute Mode میتوان حافظهی اشتراکی را بهصورت دیگری تقسیمبندی کرد. بهعنوان مثال میتوان ۳۲ کیلوبایت حافظهی اشتراکی و ۶۴ کیلوبایت حافظهی کش L1 تعریف کرد. بههرحال در تمامی موارد تنها باید ترکیب ۳۲+۶۴ را بهکار برد.
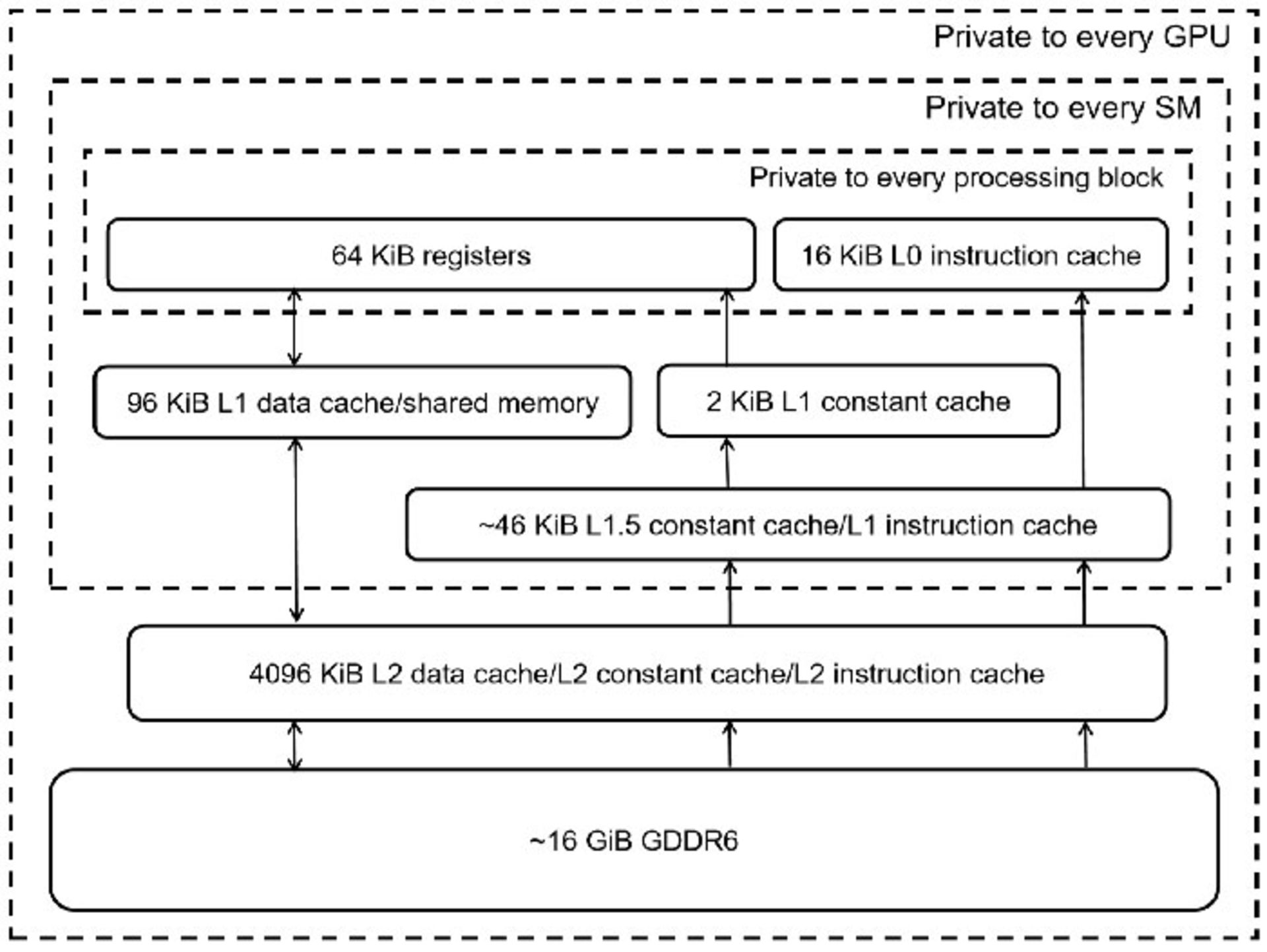
بهخاطر کمبود اطلاعات پیرامون ساختار حافظهی معماری تورینگ، کارشناسان فناوری به منابع دیگر و شرکتهای تحقیقاتی در حوزهی پردازندهی گرافیکی مراجعه کردهاند تا اطلاعات کاملتری از تحلیل پردازندهها استخراج شود. محققان مورد نظر در شرکت Citadel Enterprise Americas فعالیت میکنند. آنها تاکنون دو مقاله پیرامون تحلیل معماریهای Volta و Turing منتشر کردهاند. تصویر بالا طرحی از بررسی عمیق تراشهی TU104 توسط این تیم است.
تیم تحقیقاتی تأیید کردند که توان عملیاتی حافظهی L1 به ۶۴ بیت در هر چرخه میرسد. آنها تأکید کردند که بازدهی حافظهی کش L1 در معماری تورینگ از همهی معماریهای انویدیا بیشتر است. درنهایت این بازدهی با بازدهی حافظهی ناوی برابر میکند. درواقع اگرچه معماری AMD سرعت خواندن بیشتری در Local Data Store دارد، اما نرخ کش ثابت آن پایینتر است.
هر دو پردازندهی گرافیکی از حافظهی محلی GDDR6 استفاده میکنند که جدیدترین نسخهی DDR SDRAM مخصوص پردازش گرافیکی است. بهعلاوه هردوی آنها با پهنای باس (تعداد کانکشنهای تبادل داده میان هر تراشهی حافظه و پردازندهی گرافیکی) ۳۲ بیتی با ماژولهای حافظه در ارتباط هستند. یک کارت گرافیک Radeon RTX 5700 XT هشت تراشهی حافظه دارد و به پهنای باند حداکثری ۲۵۶ گیگابایت بر ثانیه با هشت گیگابایت فضا میرسد. درمقابل کارت گرافیک GeForce RTX 2080 Ti با تراشهی TU102 دارای ۱۱ ماژول از انواع مذکور است که به پهنای باند ۳۵۲ گیگابایت بر ثانیه و ۱۱ گیگابایت حافظه میرسد.
در ساختار حافظه هم تفاوت چندانی بین معماریها وجود ندارد
اگرچه AMD در بحث حافظه اطلاعات بیشتری ارائه میکند، برخی از اسناد آنها مبهم هستند. در اولین دیاگرام بلوکی که از ناوی مشاهده کردیم، چهار کنترلر حافظهی ۶۴ بیتی وجود داشتند، درحالی که تصویر بعدی ۱۶ عدد کنترلر را نمایش میدهد. از آنجایی که تولیدکنندههای حافظه همچون سامسونگ تنها ماژولهای حافظهی ۳۲ بیتی GDDR6 ارائه میکنند، احتمالا تصویر دوم تنها نشاندهندهی تعداد اتصال بین سیستم Infinity Fabric و کنترلرهای حافظه است. درنتیجه احتمالا ۴ کنترلر حافظه داریم که هرکدام به دو ماژول متصل میشوند.
درنهایت بهنظر نمیرسد که در بحث حافظهی داخلی و کش، تفاوت زیادی بین ناوی و تورینگ وجود داشته باشد. Navi در بحث فرایندهای اجرایی مزیتهایی دارد و حافظهی L1 ثابت آن بزرگتر است، البته هردوی آنها امکانات کاملی دارند. هر دو نمونه در موقعیتهای ممکن از فشردهسازی رنگ استفاده میکنند و هردو فضای اختصاصی GPU دارند تا دسترسی حافظه و پهنای باند را به حداکثر برسانند.
مثلثها، بافتها و پیکسلها
تولیدکنندههای پردازندهی گرافیکی ۱۵ سال پیش قرارداد مهمی را برای تعیین تعداد مثلثهای پردازشی در تراشهها ثبت کردند. در همان قرارداد به تعداد المانهای بافتی قابل فیلتر کردن در هر چرخه و ظرفیت واحدهای خروجی رندر (ROP) هم اشاره شد. این المانها امروزه هم در دنیای پردازش گرافیکی اهمیت دارند، اما از آنجایی که فناوریهای رندر سهبعدی بیش از گذشته نیاز به کارایی پردازشی دارند، تمرکز عملکردی بیشتر روی بخشهای اجرایی معطوف میشود.
بههرحال واحدهای بافتی و ROP هنوز جای بررسی دارند. به هر حال این بررسی نیز بار دیگر نشان خواهد داد که تفاوت آنچنانی در حوزهی مذکور بین کارتهای گرافیک انویدیا و AMD وجود ندارد. واحدهای بافتی در هر دو معماری توانایی شناسایی و جذب چهار المان بافتی را دارند. بهعلاوه آنها المانها را بهصورت دوتایی فیلتر و به یک المان تبدیل کرده و طی یک چرخه روی حافظهی کش مینویسند.
تنظیم و ساختاردهی ROB/RB در محصولات انویدیا و AMD با هم تفاوت دارد، اما باز هم تفاوتها بسیار جزئی هستند. تراشهی AMD در هر بخش ACE، چهار RB دارد که هرکدام در یک چرخهی پردازشی چهار پیکسل ترکیبی را به خروجی میفرستند. در معماری تورینگ، هر GPC متشکل از دو بخش RB خواهد بود که هرکدام هشت پیکسل را در یک چرخه ارائه میکنند. درنهایت میتوان تعداد ROP را در هر GPU معیاری برای نرخ خروجی پیکسل دانست. درنتیجه یک تراشهی کامل ناوی خروجی ۶۴ پیکسل در هر کلاک را دارد و این آمار برای TU102 به ۹۶ میرسد. البته فراموش نکنید که ابعاد تراشهی دوم، بسیار بزرگتر است.

در بحث پردازشهای مرتبط با المانهای مثلثی، اطلاعات زیادی از تولیدکنندهها در دست نیست. در حال حاضر میدانیم که ناوی هنوز حداکثر خروجی چهار دادهی Primitive را در هر چرخهی پردازش دارد (بهبیان دیگر یک عدد برای هر ACE). ازطرفی مشخص نیست که آیا AMD با طرح Primitive Shaders چالش مذکور را حل کرده است یا خیر. طرح مذکور یکی از قابلیتهایی بود که شرکت برای معماری Vega تمرکز زیادی روی آن داشت و به برنامهنویسها امکان میداد تا کنترل بیشتری روی دادههای پریمیتیو داشته باشند. درواقع آن قابلیت امکان افزایش توان پریمیتیو را با مقیاس چهار فراهم میکرد. بههرحال قابلیت مذکور به یکباره از درایورها حذف شد خبر زیادی نیز پیرامون آن وجود ندارد.
هنوز کاربران و کارشناسان به اطلاعات بیشتری پیرامون Navi نیاز دارند. درنتیجه نمیتوان قابلیتها و امکانات آن را با حدس و گمان بیان کرد. تورینگ هم در هر کلاک و برای هر GPC، توان پردازش یک پریمیتیو را دارد. البته انویدیا نیز قابلیتی بهنام Mesh Shaders دارد که شبیه به Primitive Shaders شرکت AMD عمل میکند. قابلیت مذکور ارتباطی با Direct3D یا OpenGL یا Vulkan ندارد، اما میتوان با استفاده از افزونههای مبتنی بر API از آن استفاده کرد.
با بررسی کلی بالا شاید بتوان برتری را در این بخش تا حدودی به تورینگ داد. درواقع میتوان ادعا کرد که پردازندهی گرافیکی انویدیا در مدیریت مثلثها و دادههای پریمیتیو عملکرد بهتری نسبت به رقیب دارد، اما بههرحال هنوز اطلاعات عمومی زیادی برای نتیجهگیری نهایی و قطعی وجود ندارد.
مسائل خارج از واحد محاسباتی
علاوه بر موارد بالا، بخشهای متعدد دیگری هم در معماریهای Navi و Turing ارزش بررسی دارند. بهعنوان مثال هر دو پردازندهی گرافیکی موتورهای تصویری و رسانهای قوی دارند. منظور از موتور تصویری، واحد مدیریت خروجی به سمت نمایشگر و موتور رسانهای، واحد انکودینگ و دیکودینگ پخش ویدئویی است.

همانطور که از یک پردازندهی حرفهای سال ۲۰۱۹ انتظار داریم، موتور تصویری ناوی رزولوشنهای بالایی را ارائه میکند و نرخ بازسازی آن نیز بسیار بالا است. بهعلاوه پشتیبانی از HDR هم در کارتهای مبتنی بر معماری مذکور ارائه میشود. از قابلیتهای دیگر ناوی میتوان به Display Stream Compression یا DSC اشاره کرد که الگوریتمی با سرعت بالا و نرخ پایین حذف جزئیات است. الگوریتم مذکور امکان ایجاد رزولوشنهای بالاتر از 4K را با نرخ تازهسازی ۶۰ هرتز فراهم میکند که توسط یک خروجی DisplayPort 1.4 قابل ارائه خواهد بود. خوشبختانه کاهش کیفیت تصویر با چنین کاهش حجمی پایین خواهد بود و حتی برخی منابع آن را نزدیک به صفر بیان میکنند.
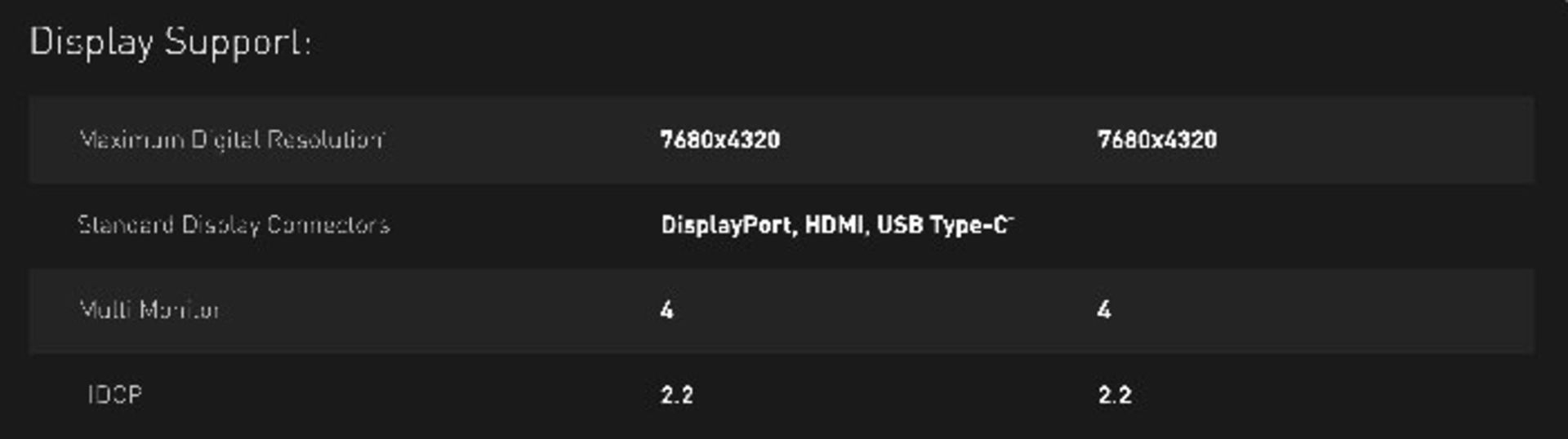
معماری تورینگ هم از DisplayPort با اتصالهای DSC پشتیبانی میکند. البته خروجی این معماری کیفیت بالاتری نسبت به ناوی دارد. معماری انویدیا، خروجی 4K HDR را با نرخ تازهسازی ۱۴۴ هرتز ارائه میکند.
موتور رسانهای ناوی بهاندازهی موتور نمایشگر آن مدرن است و پشیبانی از Advanced Video Coding یا H.264 و High Efficiency Video Coding یا H.265 را به کاربر ارائه میکند. قابلیتهای مذکور باز هم با رزولوشن و نرخ بازسازی بالا ارائه میشوند.
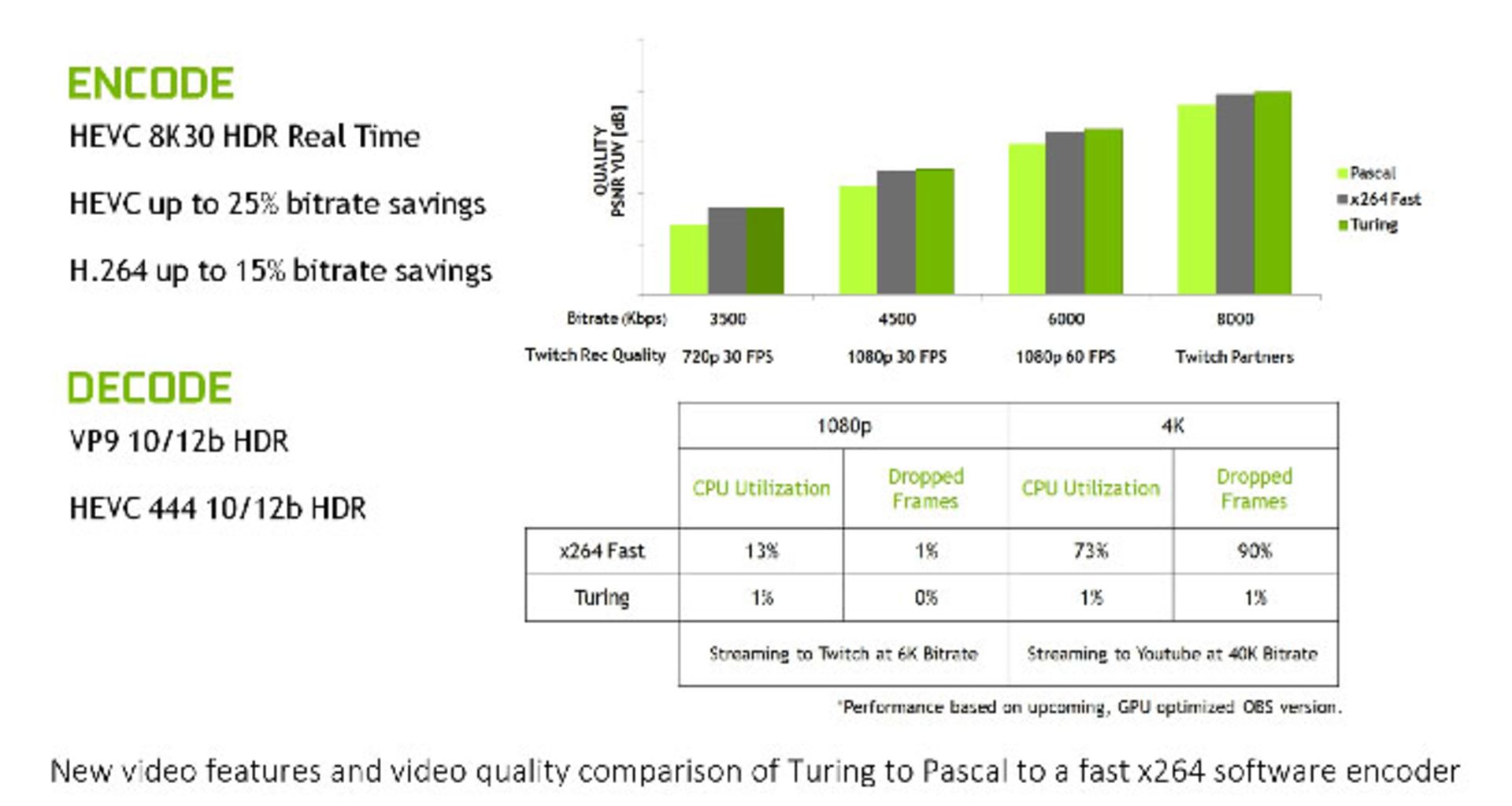
موتور ویدئویی در تورینگ هم مانند بخشهای دیگر شباهت زیادی به ناوی دارد، اما احتمالا پشتیبانی از انکودینگ 8K30 HDR در معماری انویدیا، برای برخی از کاربران یک مزیت نسبت به محصول AMD محسوب میشود.
از جنبههای دیگری که بین دو معماری گرافیکی قابل مقایسه هستند، میتوان به PCI Express 4.0 در ناوی یا NV Link در تورینگ اشاره کرد. البته آنها بخشهایی بسیار جزئی از کل معماری هستند. با وجود این شرکتهای سازنده مانور تبلیغاتی زیادی روی چنین قابلیتهایی دارند و شاید برخی کاربران را به خود جذب کنند. شایان ذکر است قابلیتهای جزئی مذکور با احتمال بالا برای بسیاری از کاربران تأثیر خاصی نخواهند داشت.
مقایسهی عملکردی
مقالهی حاضر بررسی و مقایسهای میان طراحیهای معماری، قابلیتها و کاربردهای دو رقیب در دنیای پردازش است. ازطرفی مقایسهی کارایی آنها میتواند بهعنوان روشی مناسب برای جمعبندی مقایسه به کار گرفته شود. بههرحال مقایسهی تراشهی Navi در کارت گرافیک Radeon RX 5700 XT با پردازندهی Turing TU102 در GeForce RTX 2080 Ti عادلانه نیست چون کارت گرافیک دوم دو برابر محصول اول واحدهای یکپارچهی سایهزنی دارد. بههرحال نسخهای از تراشهی TU104 تورینگ در GeForce RTX 2070 Super وجود دارد که میتوان برای مقایسهی بهینه آن را در نظر گرفت. جدول زیر، مقایسهای از دو تراشهی Navi و Turing در کارتهای گرافیک موجود در بازار است.
Radeon RX 5700 XT | GeForce RTX 2070 Super | |
|---|---|---|
پردازندهی گرافیکی | معماری | Navi 10 | RDNA | TU104 | Turing |
فرایند تولید | 7nm TSMC | 12nm TSMC |
مساحت قالب (میلیمتر) | ۲۵۱ | ۵۴۵ |
تعداد ترانزیستورها (میلیارد) | ۱۰/۳ | ۱۳/۶ |
ساختار بلوک | 2SE | 4ACE | 40CU | 5GPC | 20TPC | 40SM |
هستههای سایهزنی متحد | 2560SP | 2560CUDA |
واحدهای TMU | ۱۶۰ | ۱۶۰ |
واحدهای ROP | ۶۴ | ۶۴ |
کلاک پایهی پردازنده | ۱۶۰۵ مگاهرتز | ۱۶۰۵ مگاهرتز |
Clock | ۱۷۵۵ مگاهرتز | نامشخص |
Boost Clock | ۱۹۰۵ مگاهرتز | ۱۷۷۰ مگاهرتز |
حافظه | 8GB 256-bit GDDR6 | 8GB 256-bit GDDR6 |
پهنای باند حافظه | ۴۴۸ گیگابایت بر ثانیه | ۴۴۸ گیگابایت بر ثانیه |
توان طراحی گرمایی (TDP) | ۲۲۵ وات | ۲۱۵ وات |
در بررسی بالا باید بگوییم که RTX 2070 Super دربرگیرندهی یک پردازندهی TU104 کامل نیست و یکی از واحدهای GPC در آن غیرفعال است. درنتیجه همهی ۱۳/۶ میلیارد ترانزیستور در فرایندهای پردازشی فعال نیستند. درنهایت میتوان ادعا کرد که تراشههای بالا از لحاظ تعداد ترانزیستور با هم برابر هستند. با نگاهی اولیه به مقایسهی بالا، شباهت زیادی بین آنها دیده میشود. خصوصا در بخشهایی همچون تعداد واحدهای سایهزنی، TMU، ROP و سیستم اصلی حافظه تفاوت زیادی بین تراشهها دیده نمیشود.
در پردازندهی انویدیا هر واحد SM توانایی مدیریت و پردازش ۳۲ عدد Warp را بهصورت همزمان دارد. هر Warp نیز از ۳۲ رشته تشکیل میشود. در مجموع یک کارت گرافیک GeForce RTX 2070 Super در حداکثر بار پردازشی توانایی پردازش ۴۰،۹۶۰ رشته را در سطح کل منابع در دسترس تراشه دارد. همین بررسی برای Navi نشان میدهد که هر واحد CU توانایی پردازش ۱۶ عدد Wave را در هر واحد SIMD32 ALU دارد که مجموع رشتهها را باز هم به ۴۰،۹۶۰ عدد میرساند. اعداد مذکور، تراشهها را بسیار مشابه هم نشان میدهند، اما باید در نظر داشت که واحدهای CU و SM این دو معماری متفاوت از هم طراحی و نظمدهی شدهاند. درنهایت میدانیم که پردازندهی انویدیا در پردازش INT و FP برتری دارد، اما بههرحال همه چیز به کدهای برنامهی اجرایی روی پردازندهها بستگی دارد.
با مقایسهی بالا به این نتیجه میرسیم که بازیها در کارتهای گرافیک متنوع بازدهی و عملکرد متفاوتی را نشان میدهند؛ چرا که یکی از آنها شاید برای یک معماری مناسبتر از دیگری باشد. تفاوت نیز براساس دستورالعملهایی روشن میشود که برای پردازندهی گرافیکی ارسال میشوند. چنین تفاوتی را میتوان بهراحتی در بررسیهای عملی کارتهای گرافیک مشاهده کرد.
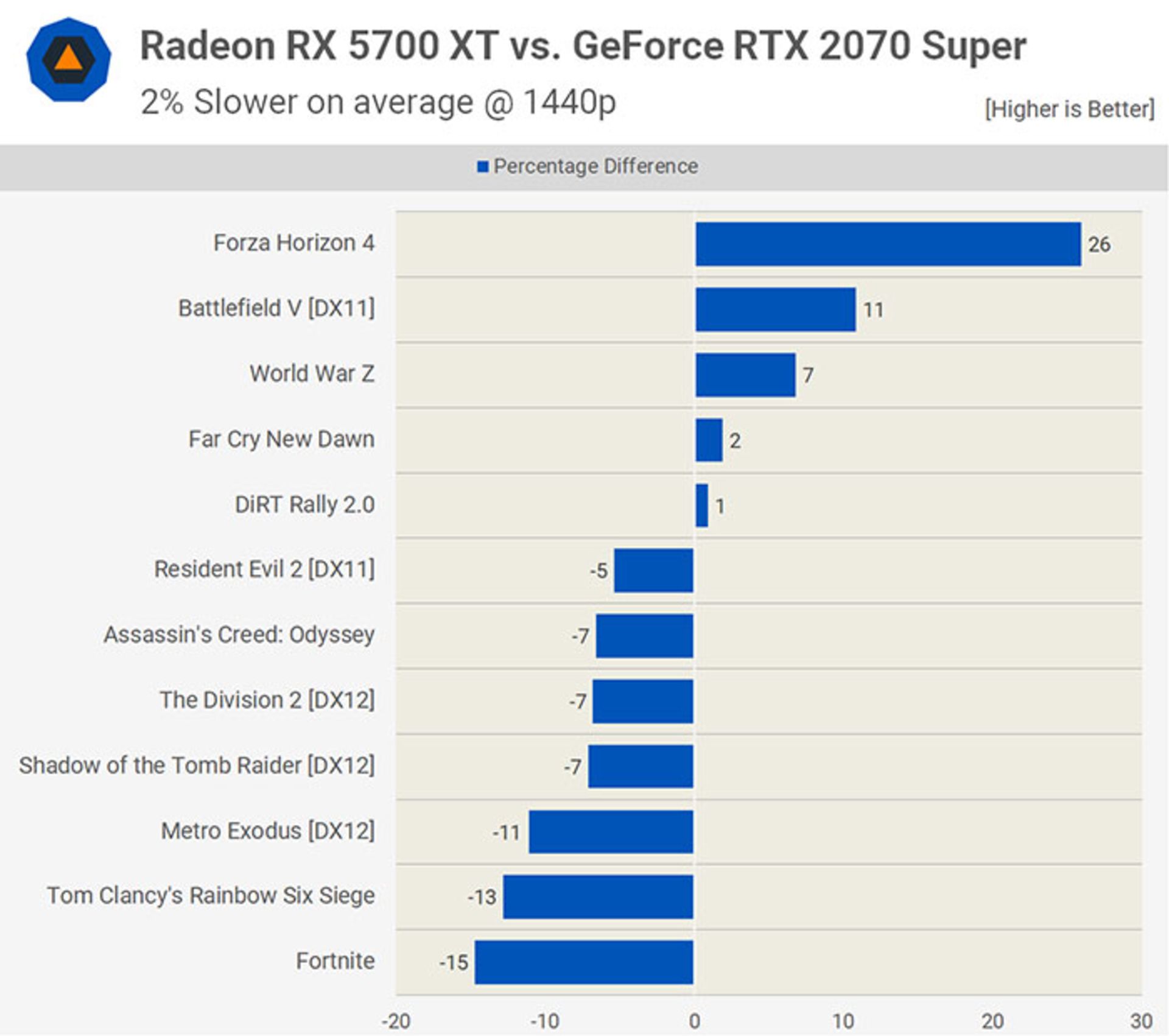
همهی بازیهایی که در بررسیها آزمایش شدند، برای معماری AMD GCN برنامهنویسی شده بودند. درواقع بازیها بهگونهای طراحی شدهاند که برای کامپیوترهای شخصی مبتنی بر کارتهای گرافیک رادئون کامپیوترهای شخصی یا پردازندههای گرافیکی مبتنی بر GCN در کنسولهای بازی همچون پلیاستیشن یا ایکسباکس اجرا شوند. البته این امکان وجود دارد که برخی از نمونههای جدید برای اجرای بهتر با تغییرات RDNA هماهنگ شده باشند، اما درنهایت تفاوت موجود در بنچمارکها به احتمال زیاد به خاطر تفاوت در موتورهای رندر و شیوهی مدیریت دادهها و دستورالعملها است.
در پایان تمامی بررسیها هنوز این سؤال مطرح میشود که آیا یک معماری بهتر از دیگری است؟ معماری تورینگ قطعا بهخاطر هستههای Tensor و RT، قابلیتهای بیشتری را به کاربران ارائه میکند. البته درنهایت نمیتوان دادههای مقایسهای از ۱۲ نمونهی بازی را بهعنوان معیاری نهایی و اصلی برای مقایسه در نظر گرفت.
سخن نهایی
برنامههای AMD برای معماری Navi در سال ۲۰۱۶ معرفی شدند. البته توضیحات زیادی از برنامههای توسعهای در آن زمان مطرح نشد و شرکت سازنده تنها سال ۲۰۱۸ را بهعنوان زمان رونمایی اعلام کرد. بههرحال در سال گذشته همه خبری از رونمایی نهایی معماری گرافیکی AMD نبود و برنامهها به امسال موکول شدند. در جزئیات جدید، خبر از بهکارگیری فرایند تولید هفت نانومتری و بهبود کلی پردازنده بهمنظور بهبود کارایی بود.
آنچه در مقالهی حاضر خواندیم، تأییدی بر تغییرات رو به جلوی AMD در دنیای پردازندههای گرافیکی بود؛ تغییراتی که قطعا با هدف پیشرفت در رقابت با محصولات انویدیا در کارتهای گرافیک لحاظ شدند. بهعلاوه، مزیت طراحیهای جدید تنها به کامپیوترهای شخصی محدود نمیشود. از آنجایی که سونی و مایکروسافت از طراحیهای مشابه در کنسولهای آتی یعنی پلیاستیشن ۵ و ایکسباکس استفاده خواهند کرد، قطعا شاهد پیشرفت قابلتوجهی در عملکرد گرافیکی محصولات آنها خواهیم بود.
اگر به ابتدای مقاله بازگردید و نگاهی بر طراحی زیرساختی Shader Engines شرکت AMD و همچنین ابعاد کلی قالب و تعداد تراتزیستورها داشته باشید، متوجه برنامهی جدی شرکت برای استفاده از تراشهی بزرگ Navi در کارتهای گرافیک حرفهای میشوید. AMD قبلا اعلام کرده بود که این برنامه در طرحهای توسعهای جاری شرکت قرار دارد و در یک تا دو سال آینده هم بهبود معماری و روندهای تولید تراشه در دستور کار قرار خواهد گرفت.

انویدیا برای آینده چه برنامههایی دارد؟ آنها برای نسلهای بعدی و توسعهی تورینگ چه طرحهایی دارند؟ تاکنون اخبار و اطلاعات زیادی از سوی شرکت منتشر نشده و اکثر اطلاعات مربوط به بهروزرسانی نقشهی راه شرکت در سال ۲۰۱۴ است. در آن زمان معماری Pascal برای رونمایی در سال ۲۰۱۶ معرفی شد که شرکت در اجرای آن موفق بود. در سال ۲۰۱۷، Tesla V100 معرفی شد که از معماری Volta بهره میبرد. همان معماری بعدا به تولد Turing در سال ۲۰۱۸ انجامید.
از سال گذشته و رونمایی تورینگ، انویدیا بهنوعی در سکوت خبری عمل کرده است و اکثر اطلاعات مبتنی بر شایعهها هستند. اکثر آنها هم تنها به نام معماری بعدی شرکت یعنی Ampere اشاره میکنند که توسط سامسونگ و مبتنی بر فرایند نود پردازشی هفت نانومتری و احتمالا تا سال ۲۰۲۰ تولید خواهد شد. علاوه بر اطلاعات مذکور، جزئیات زیادی از برنامههای انویدیا در دسترس نیست. بههرحال برخی موارد را میتوان با حدس و گمان پیش برد. دراینمیان احتمال تغییر مسیر از واحدهای اجرایی اسکالر یا هستههای Tensor در تراشههای انویدیا دور از ذهن است، چون مشکلات متعددی در حوزهی هماهنگی با نسخههای پیشین ایجاد میکند.
با ورود اینتل به رقابت پردازندههای گرافیکی، شاهد بازار داغتری خواهیم بود
با توجه به روندهای قبلی شرکت انویدیا میتوان پیشبینیها و تخمینهایی کلی از برنامههای آتی آنها داشت. شرکت سرمایهگذاری زمانی و پولی زیادی روی فناوری ری تریسینگ انجام داده است و پشتیبانی از آن در بازیها نیز روزبهروز افزایش مییابد. درنتیجه میتوان انتظار بهبود هستههای RT را در محصولات شرکت بالا دانست. بهبود مورد نظر نیز میتواند در قابلیت و ظرفیت هستهها یا تعداد آنها در هر SM باشد. اگر شایعهی استفاده از فناوری تولید هفت نانومتری را واقعی تصور کنیم، انویدیا به احتمال زیادی بیش از افزایش سرعت کلاک به کاهش مصرف نیرو فکر میکند تا در نهایت امکان افزایش واحدهای GPC را داشته باشد. البته این احتمال هم وجود دارد که شرکت از فرایندهای هفت نانومتری عبور کرده و برای کسب برتری نسبت به AMD، سراغ فرایندهای پنج نانومتری برود.
انویدیا و AMD هردو رقیب جدیدی بهنام اینتل را در مقابل خود میبینند. غول صنعت پردازنده قصد دارد تا پس از ۲۰ سال مجددا وارد بازر شود. البته توانایی محصول بعدی آنها (که احتمالا نام Xe دارد) در رقابت با تورینگ و ناوی مشخص نیست. بههرحال اینتل در دو دههی گذشته با تولید گرافیکهای داخلی برای پردازندههای خود، روند مناسبی در بازار داشته است. آخرین پردازندهی گرافیکی آنها موسوم به Gen 11 معماری نزدیکی به ناوی شرکت AMD دارد و از ALUهای برداری با توانایی پردازش FP32 و INT32 استفاده میکند. درنهایت هنوز مشخص نیست که آیا کارتهای گرافیک جدید آنها بهنوعی محصولات تکاملیافته از این طراحی هستند یا خیر.
درنهایت میتوان سالهای پیش رو را برای صنعت پردازندههای گرافیکی جذاب دانست، چون سه غول بزرگ صنعت رقابت شدیدی را برای افزایش سهم و درآمد خود در بازار در پیش میگیرند. طراحی جدید برای پردازندههای گرافیکی و معماری آنها، باعث بهبودهایی همچون افزایش تعداد ترانزیستور، ابعاد کش و ظرفیتهای سایهزنی محصولات میشود. Navi و RDNA را میتوان جدیدترین اعضای خانوادههای گرافیکی دانست. آنها نشان دادهاند که هر قدم رو به جلو و هرچند کوچک تغییرات عظیمی را بههمراه خواهد داشت.


فصل جدید همستر کامبت به نام HamsterVerse با بازیهای جذاب و وعدهی کسب درآمد رمزارزی و تونکوین از راه رسید.

کاربران برای ورود به دنیای رمزارزها، نیاز به فعالیت در صرافیها دارند. در این مقاله بهترین صرافیهای ارز دیجیتال برای ایرانیان را معرفی خواهیم کرد.

علت واریز نشدن پایا چیست؟ چطور میتوانیم حواله پایا را پیگیری کنیم؟ در این مقاله به بیان نکات مرتبط با حواله پایا میپردازیم.

در مقالهی پیش رو، با بهترین پاور بانک بازار ایران برای گوشی اندروید و آیفون از برندهایی مانند انکر، راوپاور، باسئوس و مک دودو آشنا میشویم.

شما میتوانید همزمان با چند گوشی از یک حساب اینستاگرام استفاده کنید؛ اما انتقال اکانت اینستاگرام به گوشی دیگر چگونه است؟

حالا که تابستان گرم فرارسیده است، ضرورتِ خرید کولر هم افزایش مییابد. در این مقاله با فهرستی از بهترین کولرهای آبی موجود در بازار آشنا میشویم.

دونالد پتی، فضانورد ناسا پس از ۷ ماه حضور در فضا به همراه دو کیهاننورد روس سوار بر کپسول روسی سایوز به زمین بازگشت.


