هسته تنسور چیست و چه کاربردی در پردازندههای گرافیکی دارد؟

انویدیا از سه سال پیش تاکنون، تراشههای گرافیکی مجهز به هستههای افودهای را تولید میکند که درکنار هستههای عادی مخصوص سایهزنی (Shader) استفاده میشوند. هستههای جدید که تنسور (Tensor) نام دارند، امروزه در بسیاری از کامپیوترهای رومیزی، لپتاپها، ورکاستیشنها و دیتاسنترهای سرتاسر جهان بهکار میروند. ساختار این هستهها چگونه است و آنها چه کاربردهایی دارند؟ آیا واقعا در کارت گرافیکی لزوما به هستهی تنسور نیاز داریم؟ درادامهی مطلب، به همین پرسشها پاسخ میدهیم.
آموزش کوتاه ریاضی
برای درک عملکرد و کاربرد هستههای تنسور، ابتدا باید ماهیت آنها را درک کنیم. باید بدانیم هستههای تنسور دقیقا چیست. در ابتدا، باید بدانید ریزپردازندهها صرفنظر از ساختار و فرم، برای انجام عملیات ریاضی روی اعداد (جمع، ضرب و...) ساخته میشوند. برخی اوقات اعداد باید با یکدیگر گروهبندی شوند؛ چون معنای خاصی برای یکدیگر دارند. بهعنوان مثال، وقتی تراشهای مشغول پردازش داده برای رندرکردن جلوههای گرافیکی میشود، شاید برای محاسبهی عامل مقیاس با اعداد صحیح مانند ۲، ۱۱۵ و... سروکار داشته باشد. همین تراشه برای محاسبهی موقعیت یک نقطه در فضای سهبعدی با اعداد اعشاری کار میکند. در وضعیت آخر، برای رسیدن به موقعیت دقیق به سه قطعه داده نیاز پیدا میکنیم.
تنسور مفهومی ریاضیاتی محسوب میشود که ارتباط بین دیگر مفاهیم ریاضی متصل به یکدیگر را شرح میدهد. این اعداد عموما بهصورت آرایهای از اعداد نشان داده میشوند که ابعاد آرایه را میتوان در شکلهایی شبیه تصویر زیر تصور کرد.
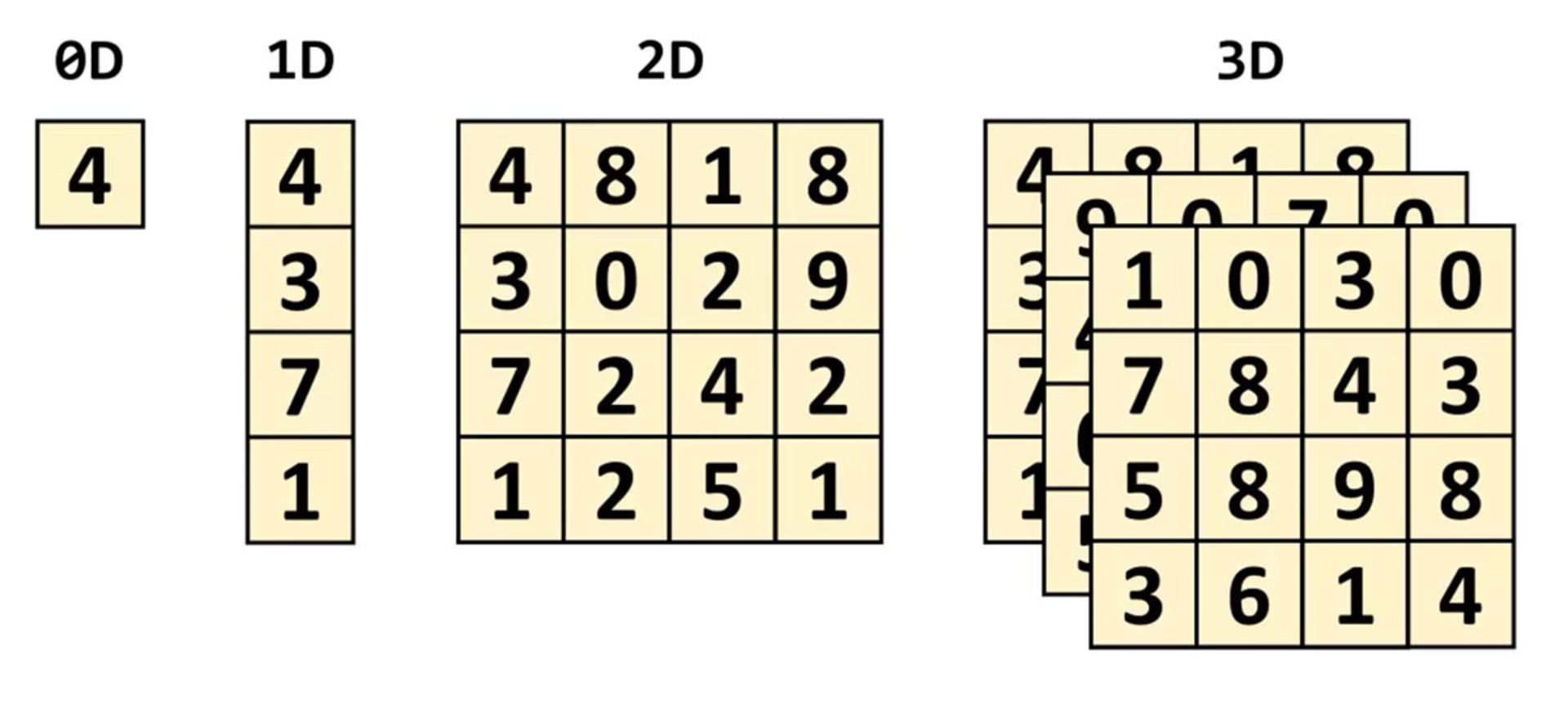
کوچکترین تنسور تصورپذیر صفر بُعد دارد و تنها یک مقدار را شامل میشود. نام دیگری که برای این تنسور بهکار میرود، اسکالر (عددی) است. با افزایش تعداد بُعدها، با ساختارهای مرسوم دیگر ریاضی روبهرو میشویم:
- تنسور یکبُعدی: برداری (Vector)
- تنسور دوبُعدی: ماتریسی (Matrix)
به بیان ساده، هر تنسور اسکالر ساختار 0x0 دارد و تنسور برداری 0x1 و تنسور ماتریسی 1x1 است. درنهایت، برای آسانشدن مفاهیم و ارتباطدادن آنها به هستههای تنسور در پردازندههای گرافیکی، تنها تنسورهایی در فرم ماتریس را بررسی میکنیم. ضرب یکی از انواع مهم عملیات ریاضی است که روی ماتریسها انجام میشود. در تصویر زیر، ضربشدن دو ماتریس با چهار سطر و چهار ستون را مشاهده میکنید.
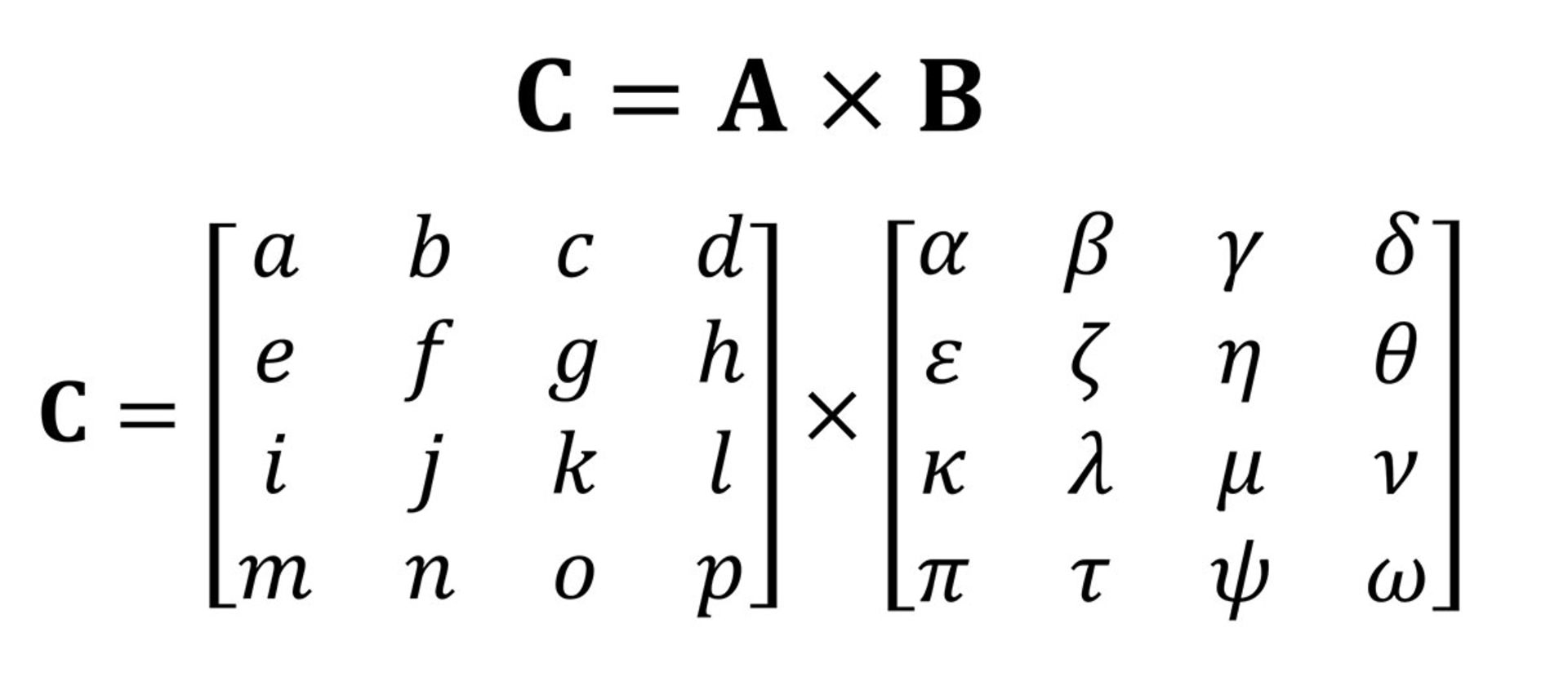
پاسخ نهایی ضرب ماتریسها، تعداد سطر برابر با ماتریس اول و تعداد ستون برابر با ماتریس دوم دارد. در تصویر زیر، نحوهی ضربکردن دو ماتریس بالا را مشاهده میکنید.
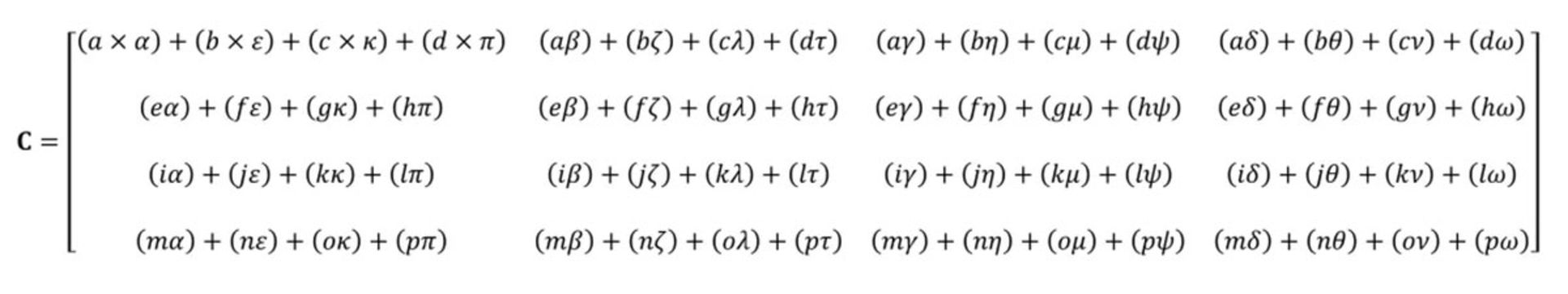
همانطورکه میبینید، ضرب دو ماتریس ساده شامل تعداد زیادی عملیات ضرب و جمع میشود. همهی پردازندههای کنونی موجود در بازار میتوانند همهی این کارها را انجام دهند؛ درنتیجه هر کامپیوتر رومیزی یا لپتاپ میتواند تنسورهای ساده را مدیریت کند و وظیفهی محاسبهی آنها را انجام دهد.
هستهی تنسور بهطور خلاصه برای محاسبههای ماتریسی کاربرد دارد
مثال بالا، شامل ۶۴ ضرب و ۴۸ جمع میشود. هر ضرب کوچک مقداری را حاصل میشود که باید در جایی نگهداری و سپس با حاصل سه ضرب بعدی جمع شود. درنهایت، همهی آنها باید به تنسور نهایی تبدیل شوند که در جایی دیگر ذخیره خواهد شد. اگرچه ضرب ماتریسی ازلحاظ ریاضیاتی ساده بهنظر میرسد، ازلحاظ پردازشی فعالیتی سنگین محسوب میشود. مقادیر زیادی باید در انجام این فرایند ذخیره شوند و حافظهی کش باید فعالیتهای متعدد نوشتن و خواندن را مدیریت کند.

در سالهای متمادی، پردازندههای AMD و اینتل افزونههای متعددی برای مدیریت و محاسبهی اعداد اعشاری بسیار زیاد در لحظه معرفی کردهاند که ازجملهی آنها میتوان به MMX و SSE و اخیرا AVX اشاره کرد. همهی این افزونهها در دستهی SIMD یا «دستورالعمل تکی برای چندین داده» قرار میگیرند؛ درنتیجه، افزونهها تمامی نیازهای محاسباتی و پردازشی برای ضرب ماتریسی را ارائه میکنند. با وجود قابلیتهای مناسب CPU برای مدیریت تنسورها، نوع دیگری از پردازنده وجود دارد که بهصورت اختصاصی برای مدیریت وظایف SIMD توسعه مییابد. بله، درست حدس زدید. پردازندهی گرافیکی یا GPU کاملا مخصوص این فرایندها است.
پردازندهای بسیار باهوشتر از ماشینحساب
در دنیای جلوههای گرافیکی، باید مجموعههای عظیم دادهای در فرم برداری را در یک لحظه جابهجا و پردازش کرد. توانایی پردازش موازی پردازندههای گرافیکی آنها را برای برعهدهگرفتن پردازش تنسورها به انتخابهای عالی تبدیل میکند. همچنین، همهی آنها امروزه از مفهوم جدیدی بهنام GEMM یا General Matrix Multiplication پشتیبانی میکنند که عملیاتی پیچیدهتر را انجام میدهد. در این عملیات، دو ماتریس در هم ضرب و حاصل آنها با ماتریس جدیدی جمع میشود. البته سه ماتریس حاضر در عملیات مذکور، محدودیتهایی ازلحاظ تعداد سطر و ستون دارند که در تصویر زیر مشاهده میکنید.
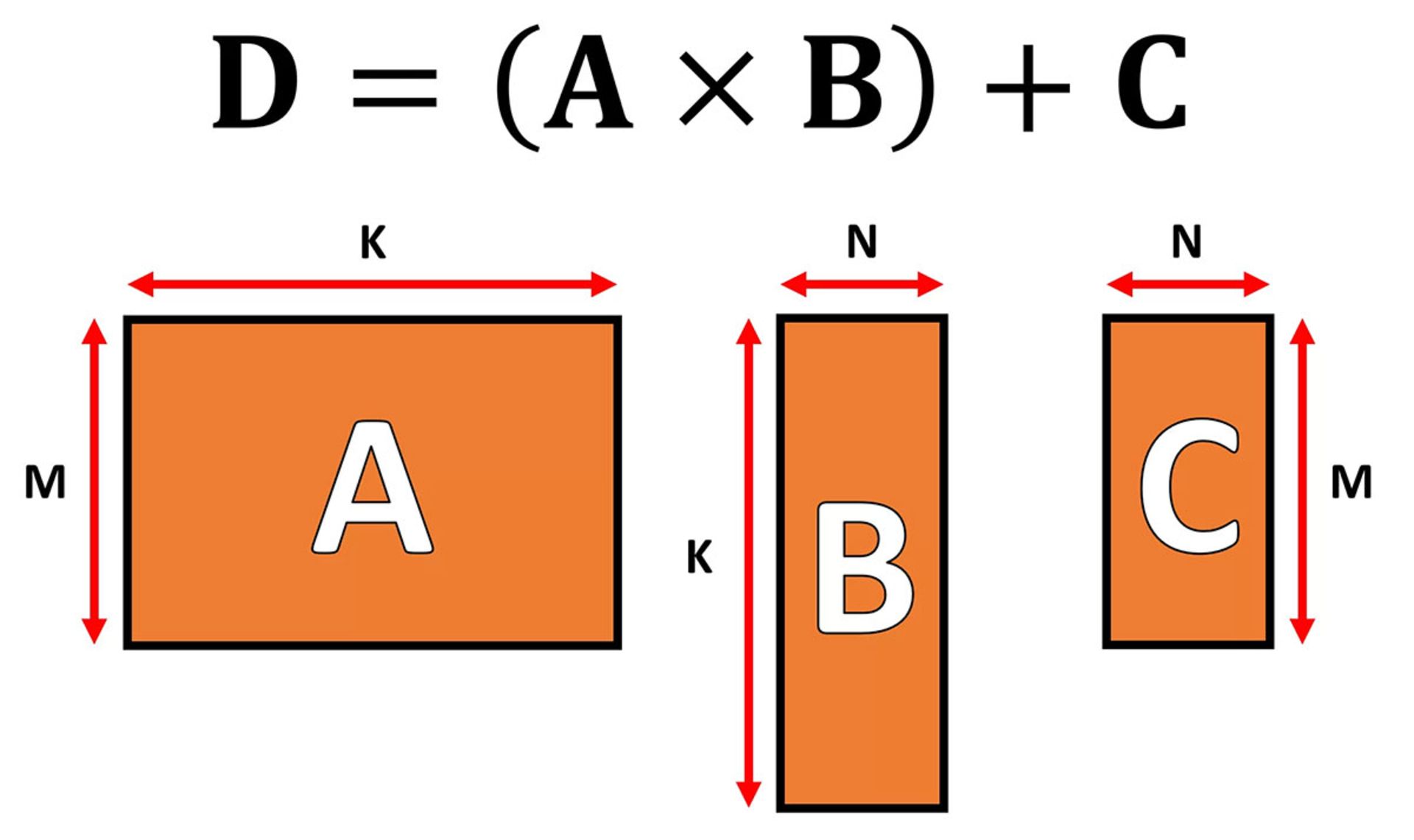
الگوریتمهایی که برای انجام عملیات روی ماتریسها توسعه پیدا کردند، در محاسبهی ماتریسهای مربعی عملکرد بهتری دارند (بهعنوان مثال، ماتریس 10x10 بهتر از 50x2 خواهد بود). همچنین، ماتریسهای کوچکتر برای انجام محاسبه بهتر هستند. بههرحال الگوریتمها زمانی بهترین عملکرد را دارند که در سختافزاری مخصوص انجام چنین محاسباتی اجرا شوند.
انویدیا در سال ۲۰۱۷ کارت گرافیکی با معماری کاملا جدیدی بهنام ولتا (Volta) معرفی کرد. محصول جدید با هدفگیری بازارهای حرفهای طراحی و ساخته شده بود و تا امروز هیچیک پردازندههای گرافیکی GeForce مبتنیبر آن ساخته نشده است. نکتهی بسیار مهم در پردازندهی جدید، مجهزبودن آن به هستههایی مخصوص محاسبههای تنسور بود.

کارت گرافیک Titan V مجهز به تراشهی ولتا
هستههای تنسور انویدیا برای انجام ۶۴ عملیات GEMM در هر چرخهی کلاک روی ماتریسهای 4x4 طراحی شده بودند که اعداد اعشاری تا ابعاد ۱۶ بیتی را شامل باشند (FP16). بهبیاندیگر، هستهها قابلیت انجام ضرب FP16 و جمع با FP32 را داشتند. چنین تنسورهایی بسیار کوچک هستند؛ درنتیجه، وقتی دیتاستهایی با ابعاد واقعی را پردازش میکنند، بلوکهای کوچک ماتریسهای بزرگتر را وارد عملیات پردازش میکنند تا بهمرور به پاسخ نهایی برند.
کمتر از یک سال بعد، انویدیا معماری تورینگ را معرفی کرد. اینبار پردازندههای جیفورس نیز به هستههای تنسور مجهز شده بودند. سیستم بهگونهای بهروزرسانی شده بود که فرمتهای دادهای (مانند INT8 یا اعداد صحیح هشت بیتی) را هم پشتیبانی میکرد؛ البته بهجز بهروزرسانیهای مذکور ساختار عملیاتی معماری جدید تفاوت زیادی با ولتا نداشت.

در ابتدای سال جاری، انویدیا معماری امپر را در پردازندههای گرافیکی A100 مخصوص دیتاسنتر معرفی کرد. اینبار بهرهوری و قدرت هستهها افزایش پیدا کرد و بهجای ۶۴ عملیات، ۲۵۶ عملیات GEMM در هر چرخه انجام میشود. بهعلاوه، فرمتهای دادهای جدید هم به مجموعهی پشتیبانیشده اضافه شد و هستههای جدید توانایی محاسبه و مدیریت سریع تنسورهای کمپشت (ماتریسهایی با تعداد زیاد رقم صفر) را با سرعت بسیار سریع پیدا کردند.
هستههای تنسور در یادگیری عمیق و شبکهی عصبی کاربرد بسیار زیادی دارند
برنامهنویسان برای دسترسی به هستههای تنسور در تمامی انواع معماری ولتا و تورینگ و امپر کار دشواری در پیش ندارند. کد برنامه باید از یک نشان (Flag) استفاده کند تا به API و درایورها بگوید قصد دارد از هستهی تنسور استفاده کند. البته نوع داده نیز باید از نوعی باشد که هستهها پشتیبانی میکنند و ابعاد ماتریس هم باید مضربی از هشت باشد. درنهایت، سختافزار تمامی کارهای دیگر را انجام میدهد.
توضیحات اولیه نشان داد هستههای تنسور بسیار مناسب هستند و عملکردی چشمگیر دارند. اکنون این سؤال مجددا مطرح میشود که آنها در انجام فعالیتهای GEMM چقدر بهتر از هستههای عادی پردازندهی گرافیکی عمل میکنند؟ زمانیکه معماری ولتا معرفی شد، رسانهی معتبر آناندتک بررسی کلی و مقایسهی ریاضی بین سه کارت گرافیک انویدیا انجام داد: یک کارت با معماری جدید ولتا و یک کارت مبتنیبر معماری پاسکال و یک کارت قدیمی مبتنیبر مکسول.
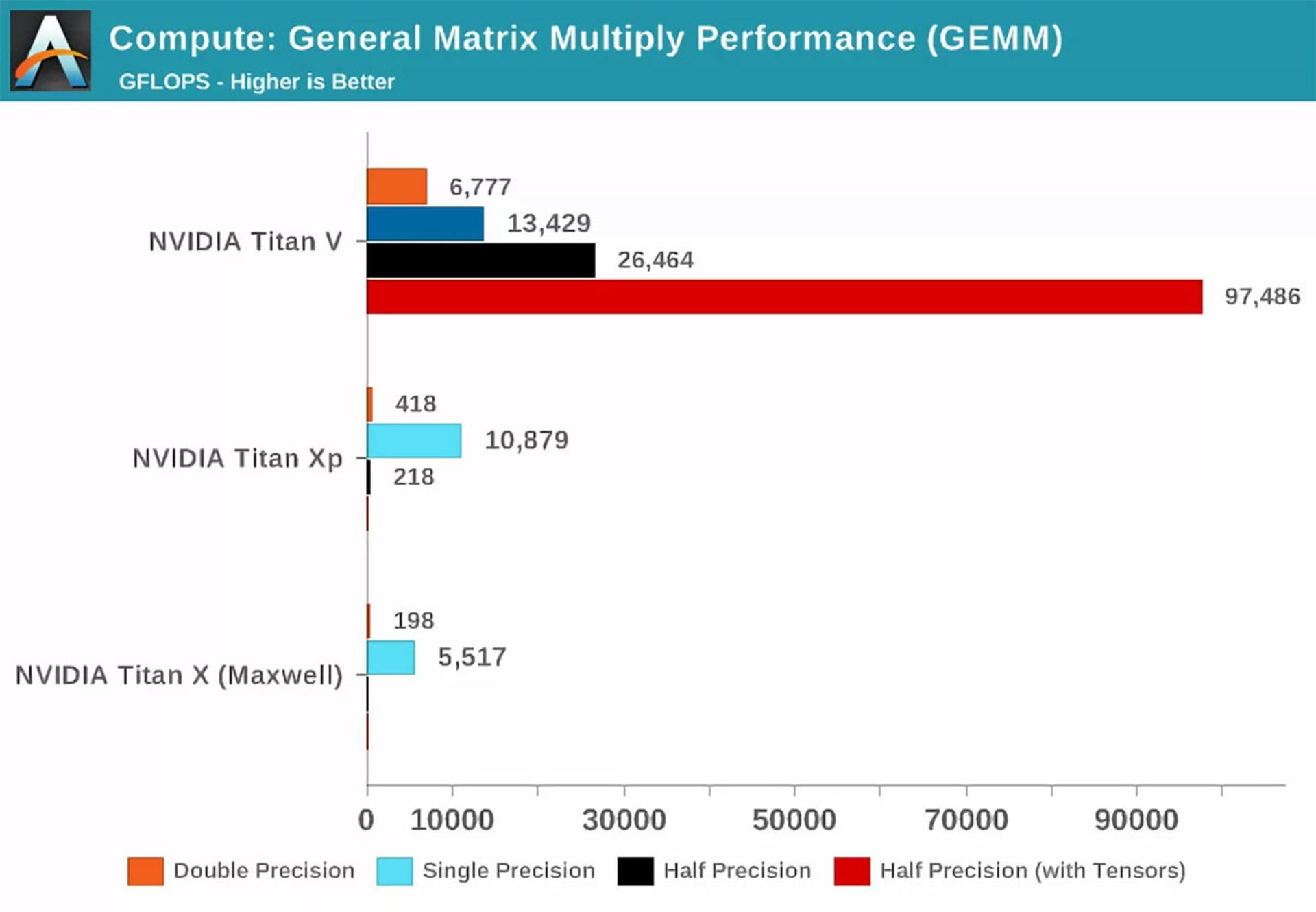
اصطلاح Precision که در تصویر بالا میبینید، به تعداد بیتهایی اشاره میکند که برای اعداد اعشاری در ماتریس استفاده میشوند. double برای نشاندادن ۶۴ و Single برای نشاندادن ۳۲ استفاده میشود و Half نیز ۱۶ بیت را نشان میدهد. محور افقی نشاندهندهی حداکثر عملیات اعشاری است که در هر ثانیه انجام میشود که بهطور خلاصه با اصطلاح فلاپس (FLOPS) میشناسیم (فراموش نکنید هر GEMM بهاندازهی سه FLOP بود).
با نگاهی به نمودار بالا& بهراحتی میتوانید تأثیر هستههای تنسور را درمقایسهبا زمان استفاده از فقط هستههای CUDA درک کنید؛ درنتیجه، امروز بهطور حتم میدانیم هستههای جدید برای انجام محاسبات اینچنینی عالی هستند. اکنون سؤال دیگری داریم: با هستههای تنسور چه کارهایی میتوان انجام داد؟
استفاده از ریاضی برای بهبود همهچیز
انجام محاسبه در دنیای تنسور در کاربردهای فیزیک و مهندسی بسیار کارآمد خواهد بود؛ خصوصا در مکانیک سیالات و الکترومغناطیس و فیزیک نجومی، از تنسورها برای حل اکثر مسائل پیچیده استفاده میشود. البته همیشه کامپیوترهایی که برای پردازش این نوع از اعداد استفاده میشدند، عمیلات ماتریسی را در مجموعههای عظیم CPU انجام میدادند.
از حوزههای دیگری که قطعا از هستههای تنسور استفادهی بسیار زیادی خواهد داشت، میتوان به یادگیری ماشین اشاره کرد؛ بهویژه در زیرمجموعهی شبکهی عصبی، تنسورها کاربرد بسیار زیادی دارند. پردازشهای مرتبط در حوزههای مذکور، همگی به مدیریت مجموعههای عظیم داده نیاز دارند که در آرایههای بسیار بزرگ بهنام شبکههای عصبی دیده میشوند. در این مفاهیم، ارتباط بین مقادیر گوناگون داده وزن خاصی دارند که اهمیت ارتباط را نشان میدهد.
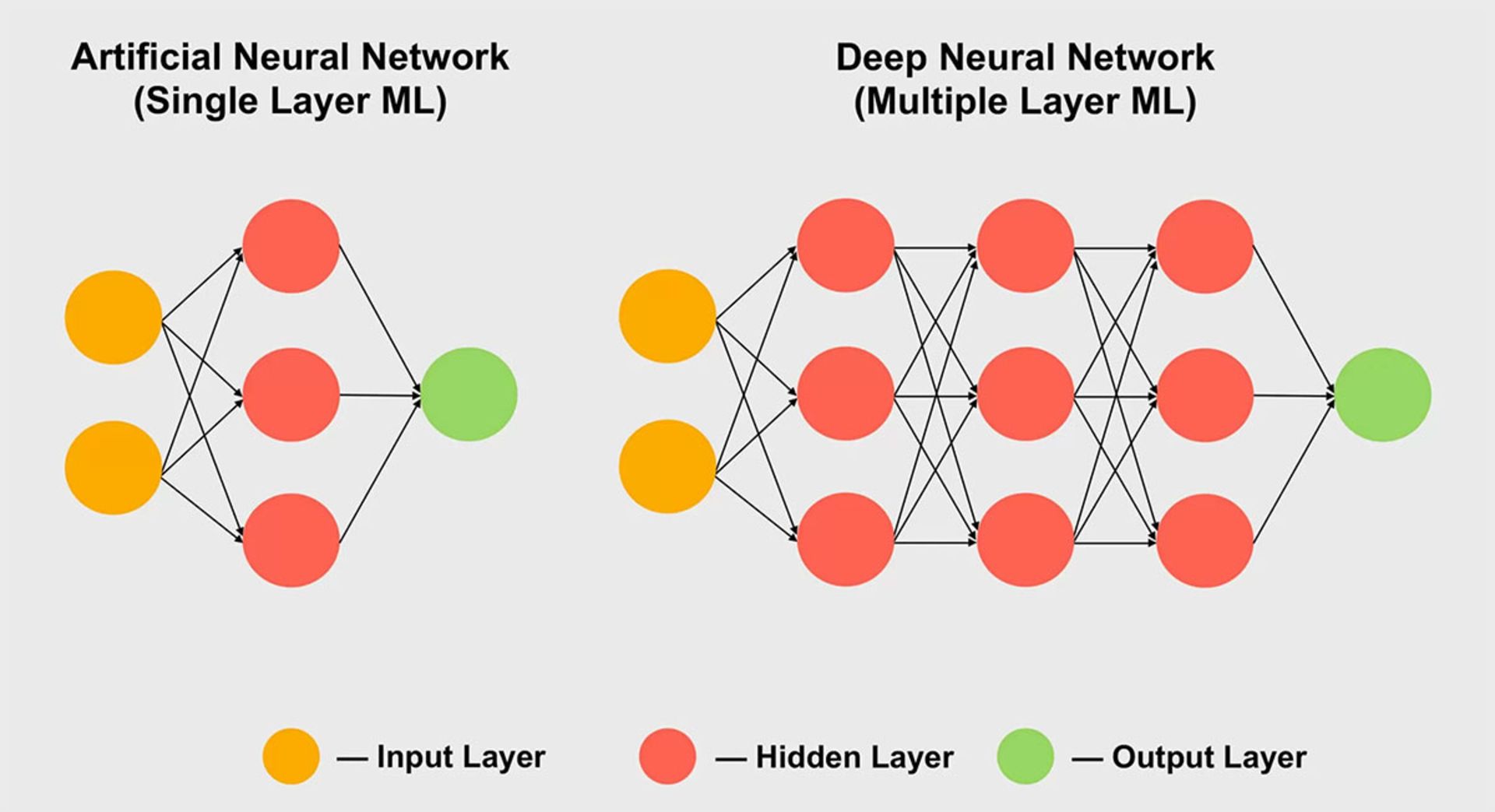
در ساختاری که گفتیم، وقتی نوبت به محاسبه و مدیریت چگونگی تعامل صدها و هزارها ارتباط میرسد، باید هر تکه از داده را در شبکه با وزنهای متفاوت از هر ارتباط ضرب کنید. بهبیاندیگر، باید دو ماتریس در هم ضرب شوند که همان عملیات ریاضی تنسور را نشان میدهد؛ بههمیندلیل، تمامی اَبَرکامپیوترهای عظیم یادگیری عمیق از پردازندههای گرافیکی متعدد استفاده میکنند که اغلب هم ساخت انویدیا هستند. ناگفته نماند برخی شرکتها برای نفع نیازهای خاص خود یک قدم فراتر رفتهاند و پردازندههای مخصوص هستهی تنسور تولید کردهاند. بهعنوان مثال، گوگل اولین واحد پردازش تنسور (TPU) خود را در سال ۲۰۱۶ معرفی کرد؛ اما این تراشهها بهقدری مخصوص هستند که هیچ کاری بهجز محاسبههای ماتریسی انجام نمیدهند.

هستههای تنسور در پردازندههای گرافیکی مصرفکننده (GeForce RTX)
اکنون که به کاربرد هستههای تنسور در پردازشهای پیچیده پی بردهاید، هنوز این سؤال را مطرح میکنید: کارت گرافیک مصرفکننده مانند GeForce RTX چه استفادهای از هستهها میبرد؟ بهبیاندیگر، آیا کاربر عادی که با پردازشهای سنگین فیزیک نجومی یا یادگیری ماشین کاری ندارد، واقعا به هستهها نیاز پیدا میکند؟
بهطور کلی، هستههای تنسور برای کاربردهایی مانند رندر عادی یا انکود و دیکود ویدئو استفاده نمیشوند؛ پس ظاهرا پول خود را برای قابلیتی هزینه کردهاید که کاربردی ندارد. البته انویدیا از سال ۲۰۱۸ هستههای تنسور را در محصولات مصرفکننده اضافه کرد و اولین محصولات نیز در دستهی Turing GeForce RTX عرضه شدند و در همان زمان، قابلیت DLSS یا Deep Learning Super Sampling هم در پردازندهها افزوده شد.

فرضیهی پایهای در عملکرد فناوریهای جدید در پردازندههای گرافیکی ساده است: ابتدا یک فریم در رزولوشن پایین رندر میشود و پس از پایان رندر، رزولوشن بهاندازهای افزایش پیدا میکند تا به ابعاد نمایشگر برسد (بهعنوان مثال، ابتدا در رزولوشن 1080p رندر و سپس به 1400p مقیاسدهی میشود). با چنین روشی، بهدلیل پردازشکردن پیکسلهای کمتر و سرعت و کارایی بهتر میشود؛ اما درنهایت، بازهم با تصویری با کیفیت مناسب روی نمایشگر روبهرو میشوید.
کنسولها از سالها پیش رویکردی مشابه مراحل بالا را انجام میدادهاند. بسیاری از بازیهای امروزی دنیای کامپیوتر شخصی نیز همین قابلیت را ارائه میکنند. بهعنوان مثال، در بازی Assassin's Ceeed: Odyssey میتوانید رزولوشن رندر را حداکثر ۵۰ درصد ابعاد نمایشگر کاهش دهید؛ ولی متأسفانه نتیجه آنچنان عالی نمیشود. در تصویر زیر، نمایی از بازی را در 4K با حداکثر تنظیمات گرافیکی مشاهده میکنید.

اجرای بازی در رزولوشن بیشتر، یعنی بافتها بهتر نمایش داده شوند و جزئیات خوبی هم داشته باشند. متأسفانه آن همه پیکسل برای تبدیلشدن به تصویر نهایی به پردازش بسیار زیاد نیاز دارند. اکنون در تصویر زیر، وضعیتی را میبینید که ابتدا فریم در رزولوشن 1080p یا یکچهارم تعداد پیکسلها درمقایسهبا حالت قبلی رندر میشود و سپس به 4K افزایش پیدا میکند.

شاید تفاوت بین دو تصویر را بهراحتی شناسایی نکنید؛ چون بههرحال بارگذاری در اینترنت و فشردهسازی در jpg روی کیفیت نهایی تأثیر میگذارد. البته با کمی دقت میبینید زره شخصیت بازی و کوهی که در دوردست صحنه دیده میشود، کمی مات هستند. برای مشاهدهی بهتر تفاوت، مقایسهی زیر را ببینید.

تصویر سمت چپ در رزولوشن 4Kرندر و تصویر سمت راست پس از رندر 1080p به 4K مقیاسدهی شده است. تفاوت بین دو حالت، خصوصا در حرکت در بازی، بسیار زیاد احساس میشود. در حرکت، بهدلیل کمترشدن جزئیات در رندر با رزولوشن کم جلوههای مات بیشتری تجربه میکنید. برخی از این جلوهها شاید با استفاده از جلوههای شارپکردن در درایورهای کارت گرافیک اصلاحشدنی باشد؛ اما شاید استفادهنکردن از چنین قابلیتی از همان ابتدا منطقیتر بهنظر برسد.
برای رفع مشکل یادشده، فناوری DLSS از انویدیا کاربرد پیدا میکند. در نسخهی اولیهی این فناوری، تعداد محدودی از بازیها تحلیل شدند که در حالتهای گوناگون با رزولوشنهای کم و زیاد و فعال و غیرفعال بودن Anti-Aliasing مقایسه شدند. حالتهای گوناگون تصاویر بسیار زیادی تولید کردند که همگی وارد اَبَرکامپیوترهای مخصوص شدند تا با استفاده از شبکهی عصبی، بهترین روش برای تبدیلکردن تصویر 1080p به تصویری با رزولوشن بیشتر پیدا شود.

فناوری DLSS 1.0 عملکرد آنچنان خوبی نداشت؛ زیرا جزئیات در استفاده از فناوری عموما از بین میرفتند یا در برخی مواقع، با لرزشهای عجیب دیده میشدند. بهعلاوه، فناوری مذکور از هستههای تنسور موجود در کارت گرافیک کامل استفاده نمیکرد. درنهایت، تمامی بازیها به پشتیبانی DLSS نیاز داشتند تا انویدیا تحلیل اختصاصی روی آنها شود و الگوریتم مقیاسدهی را بسازد.
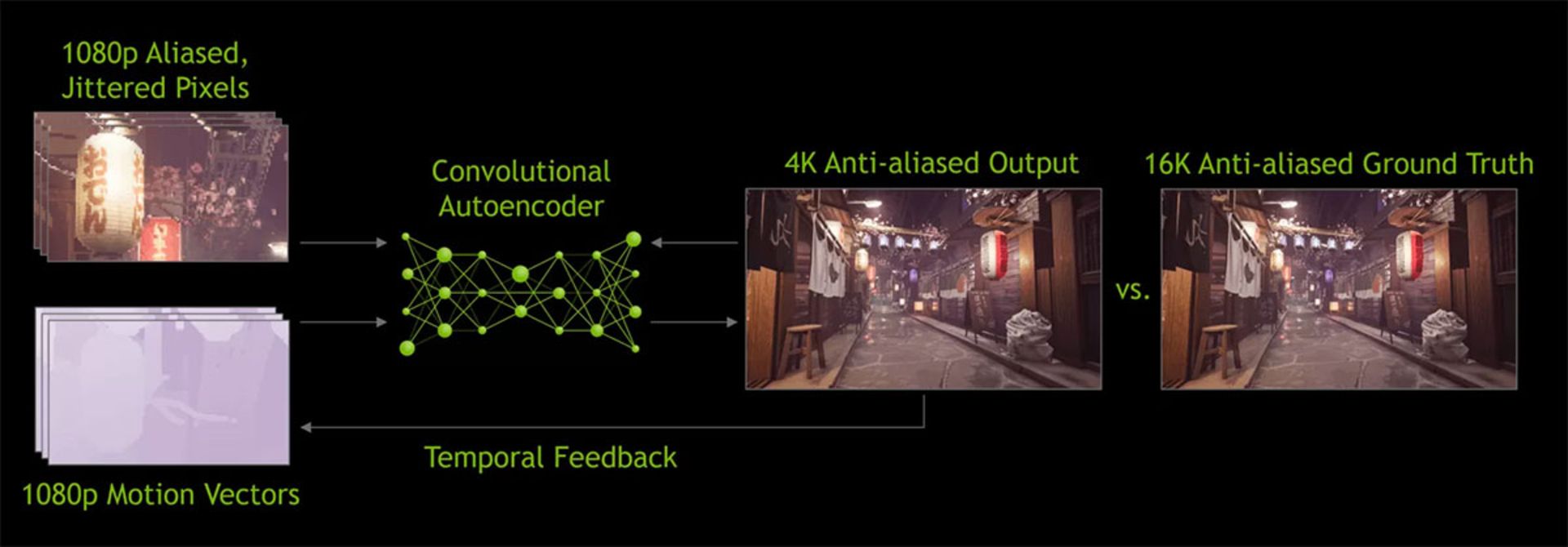
نسخهی دوم DLSS که در ابتدای سال جاری معرفی شد، با بهینهسازیهای بسیار زیادی همراه بود. مهمترین نکته این بود که اَبَرکامپیوترهای انویدیا فقط برای ساختن الگوریتمهای مقیاسدهی عمومی استفاده شدند. در نمونهی جدید DLSS، دادهها از فریمهای رندرشده برای پردازش پیکسلها استفاده میشدند که از هستهی تنسور پردازندهی گرافیکی استفاده میکرد.

درحالحاضر، تواناییهای DLSS 2.0 بسیار جذاب و درخورتوجه هستند؛ اما تعداد محدودی از بازیها از آن پشتیبانی میکنند که اکنون جمعا به ۱۲ عنوان میرسند. قطعا توسعهدهندگان بیشتری در نسخههای بعدی از بازیهای خود به پشتیبانی از قابلیت فکر میکنند. در بحث عملکرد و قدرت، بهبودهای چشمگیری پیدا میشوند که در هرنوع مقیاسدهی احساس خواهند شد؛ درنتیجه، میتوان ادعا کرد DLSS مسیر تکاملی درخورملاحظهای در پیش دارد.
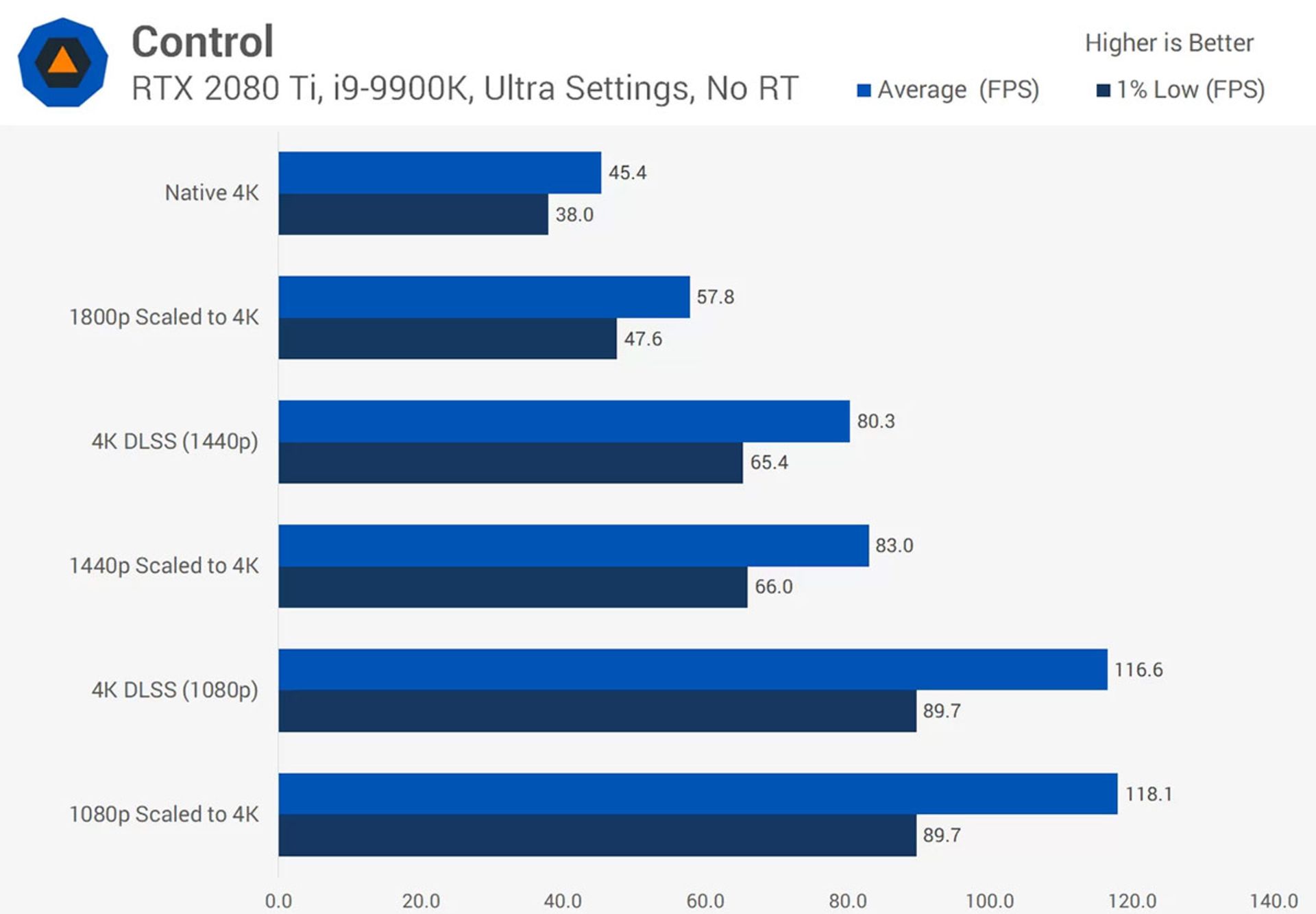
خروجی بصری DLSS در همهی موقعیتهای عالی نیست و عملکرد و قدرت پردازش گرافیکی نیز بهبود پیدا میکند و توسعهدهندگانمیتوانند جلوههای بصری بیشتری ارائه کنند. آنها میتوانند بهسمتی پیش بروند که جلوههای گرافیکی در مجموعهی گستردهتری از پلتفرمها خروجی یکسان داشته باشند.
در اغلب مواقع، DLSS درکنار قابلیت رهگیری پرتو و در بازیهای RTX enabled دیده میشود. پردازندههای گرافیکی انویدیا GeForce RTX با واحدهای پردازشی اضافهای بهنام هستههای RT عرضه میشوند. این واحدهای منطقی مخصوص شتابدهی به پردازشهای ray-triangle در پرتوهای نور و BVH هستند. بهبیان ساده، دو نوع پردازش مذکور برای رندرکردن و محاسبهی جلوهی برخورد نور به دیگر اجسام موجود در صحنه استفاده میشوند و زمان زیادی هم برای پردازش نیاز دارند.
پردازش رهگیری پرتو فشار زیادی به پردازنده وارد میکند؛ درنتیجه، توسعهدهندگان برای ارائهی تجربهی مناسب بازی باید تعداد پرتوها و بازتابهای موجود در صحنه را کاهش دهند. این فرایند شاید به ایجاد تصاویر با نویز فراوان منجر شود؛ بنابراین، استفاده از الگوریتم کاهش نویز نیز احساس میشود. درمجموع، بازهم فشار و پیچیدگی پردازش افزایش خواهد یافت. در چنین موقعیتی، هستههای تنسور با استفاده از کاهش نویز مبتنیبر هوش مصنوعی به بهبود عملکرد کمک میکنند. البته چنین کاربردی هنوز به مرحلهی اجرا نرسیده است و اکثر اپلیکیشنهای کنونی از هستههای CUDA برای پردازش مذکور استفاده میکنند. گفتنی است با تکامل پیداکردن DLSS و حضور DLSS 2.0 بهعنوان روش مقیاسدهی مطمئن، هستههای تنسور میتوانند بهخوبی برای تقویت نرخ فریم پس از اجرای رهگیری پرتو در صحنه استفاده شوند.
برنامههای متعدد دیگری هم برای هستههای تنسور در کارتهای GeForce RTX وجود دارد؛ ازجمله حرکت بهتر شخصیتها یا شبیهسازی لباسها. درنهایت، مانند وضعیتی که برای DLSS 1.0 داشتیم، تا رسیدن به وضعیتی که صدها بازی از محاسبههای مخصوص ماتریسی در پردازندههای گرافیکی استفاده کنند، زمان زیادی نیاز داریم.
امید به آینده فناوری
اکنون میدانیم هستههای تنسور قطعات سختافزاری خاص و محدودی هستند که تنها در تعداد کمی از کارتهای گرافیکی مخصص مصرفکننده استفاده میشوند. آیا این روند در آینده تغییر میکند؟ ازآنجاکه انویدیا هماکنون هم بهرهوری و کارایی هستهی تنسور را در آخرین معماری خود، یعنی امپر بهبود داده است، شاید بهزودی مدلهای میانرده و اقتصادی بیشتری را شاهد باشیم که از هستههای مذکور بهره میبرند.
اینتل و AMD در پردازندههای گرافیکی خود هستههای تنسور ندارند؛ اما شاید در آینده فناوری مشابهی عرضه کنند. AMD اکنون سیستمی برای شارپکردن و افزایش جزئیات در فریمهای کاملشده دارد که تأثیر کمی هم بر سرعت و بهرهوری پردازش میگذارد. شاید تیم قرمز روی همان فناوری متمرکز بماند؛ زیرا مزایای درخورتوجهی هم دارد. بهعنوان مثال، نیازی نیست توسعهدهندگان آن را در کدهای خود ادغام کنند و تنها با کمی تغییر در درایور اجرا میشود.
برخی اعتقاد دارند فضای قالب در تراشههای گرافیکی باید هرچه بهتر برای اضافهکردن هستههای سایهزنی استفاده شود. انویدیا این کار را در تراشههای اقتصادی مبتنیبر تورینگ انجام داد. محصولاتی همچون GeForce GTX 1650 اصلا به هستههای تنسور مجهز نبودند و درعوض، هستههای سایهزنی FP16 بیشتری داشتند.
درپایان باید بگوییم اگر بهدنبال انجام پردازشها و محاسبههای سریع روی عملیات GEMM هستید، دو راه بیشتر پیش روی شما نخواهد بود: ۱. استفاده از تعداد زیادی CPU بهصورت تجمیعی؛ ۲. استفاده از پردازندهی گرافیکی مجهز به هستههای تنسور.