بررسی جامع استانداردهای حافظه GDDR و HBM؛ تفاوتها و ویژگیها

تاریخچهی کارتهای گرافیک انویدیاقسمت اولقسمت دومقسمت سوم
این روزها با عرضهی کارتهای گرافیک قدرتمندی از سوی دو رقیب دیرین یعنی انویدیا و AMD، جدال بر سر فناوریهای گرافیکی از همیشه داغتر شده است. یکی از آوردگاههای این رقابت نفسگیر، موضوع حافظههای گرافیکی است. رقابتی که در آن، میزان حافظهی گرافیکی همراهبا پردازندهی گرافیکی تنها پارامتر دارای اهمیت نیست؛ بلکه پارامتری به نام پهنای باند حافظه نقش تعیینکنندهای دارد و این دو رقیب تراشهساز تمام تلاش خود را میکنند تا اعداد و ارقام مربوطبه این پارامتر را ارتقاء دهند.
انویدیا درکنار معرفی و عرضهی معماری گرافیکی جدید خود با نام تورینگ و ارائهی قابلیتهایی مانند رهگیری پرتو (Ray Tracing) و آنتیآلیاسینگ مبتنی بر هوش مصنوعی (DLSS)، حافظههای گرافیکی نوظهور GDDR6 را وارد کارتهای گرافیک خود کرده است تا از حداکثر سرعت دسترسی به دادهها و پهنای باند ارائهشده در حافظه های GDDR تا به امروز نهایت بهرهبرداری را کرده باشد. این شرکت در کارت پرچمدار خود Geforce RTX 2080 با بهکارگیری ۸ گیگابایت از این نوع حافظهی سریع گرافیکی، حداکثر پهنای باند را به ۴۴۸ گیگابایت بر ثانیه رسانده است.
تاریخچهی کارتهای گرافیک AMD/ATIقسمت اولقسمت دوم
در سوی دیگر این آوردگاه AMD قرار دارد که با بهکارگیری ۱۶ گیگابایت حافظهی بسیار سریع و پهنباند HBM2 در کارت گرافیک پرچمدار خود Radeon VII، رقابت تنگاتنگی را با شرکت انویدیا در پیش گرفته و این بار پهنای باند حافظهی گرافیکی را به بیش از یک ترابایت بر ثانیه افزایش داده است.
در ادامهی این مقاله، ابتدا نگاهی خواهیم داشت به مفهوم پهنای باند حافظهی گرافیکی و اصطلاحات فنی مربوطه و سپس بهسراغ بررسی موشکافانهی دو نوع حافظهی گرافیکی GDDR6 و HBM میرویم و ویژگیهای آنها را با یکدیگر مقایسه خواهیم کرد.
پهنای باند حافظه چیست؟
سرعت تبادل دادهها میان حافظه و پردازندهی گرافیکی یا بهعبارت دیگر سرعت خواندن داده از حافظهی گرافیکی یا نوشتن روی آن توسط پردازندهی گرافیکی، پهنای باند حافظهی گرافیکی خوانده میشود. پس پهنای باند حافظه حاکی از سرعت ذخیرهی اطلاعات روی حافظه یا بازخوانی اطلاعات از حافظه توسط تراشهی گرافیکی اصلی یا همان GPU است. پارامتر پهنای باند حافظه با واحد بایت بر ثانیه (Byte/s) یا واحدهای بزرگتر از آن (در این مقاله با واحد GB/s) بیان میشود. معمولاً پهنای باند حافظه که برای یک تراشهی حافظهی خاص اطلاعرسانی و تبلیغ میشود، حداکثر پهنای باند نظری آن تراشه است و پهنای باند واقعی اندازهگیریشده زیر بار پردازش گرافیکی نظیر بازیها کمتر از این عدد است.
پهنای باند حافظهی گرافیکی تابعی از پارامترهای مختلف به شرح زیر است:
پهنای باند با دراختیار داشتن مقادیر فوق ازطریق رابطهی زیر محاسبه میشود:
n*b*s)/8)
رقابت اصلی در زمینه حافظههای گرافیکی نه بر سر حجم، بلکه بر سر مجموع پهنای باند تراشههای حافظه است
در رابطهی فوق، برای رسیدن به واحد استاندارد پهنای باند حافظه (گیگابایت بر ثانیه) حاصلضرب سه پارامتر n و b و s تقسیم بر عدد ۸ شده است. همانطور که از این رابطه پیدا است، پهنای باند حافظه در یک کارت گرافیکِ بهخصوص، از تعداد تراشههای گرافیکی موجود، سرعت هر تراشهی حافظه (که بستگی به نوع آن حافظه اعم از GDDR5، GDDR5X، GDDR6 و ... دارد) و پهنای باس هر تراشه تأثیر میپذیرد.
برای مثال، شکل زیر تصویر برد اصلی Geforce RTX 2080، کارت گرافیک پرچمدار انویدیا با معماری تورینگ را نشان میدهد. همانطور که دیده میشود، ۸ تراشهی حافظه از نوع GDDR6 (هریک با چگالی 1GB)، پردازندهی گرافیکی TU104 را احاطه کردهاند که پهنای باس هر تراشه ۳۲ بیت و سرعت انتقال دادهی هر یک 14Gbps است.

برد اصلی کارت گرافیک Geforce RTX 2080 پرچمدار فعلی انویدیا
بنابر رابطهی فوق، پهنای باند حافظهی گرافیکی در این کارت برابر است با ۴۴۸GBps یا بهعبارتی:
گیگابایت بر ثانیه ۴۴۸=۸/(۳۲×۱۴×۸)
حال برای مقایسه میخواهیم پهنای باند حافظهی کارت گرافیک GTX 1080 را محاسبه کنیم. در تصویر زیر برد اصلی این کارت که پرچمدار معماری پاسکال است را مشاهده میکنید. دیده میشود که ۸ تراشهی گرافیکی از نوع GDDR5X با پهنای باس ۳۲ بیتی (هر تراشه ازطریق ۳۲ مسیر داده با پردازنده در ارتباط است) و سرعت 10Gbps پردازندهی گرافیکی GP104 را در این برد احاطه کرده است.

برد اصلی کارت گرافیک Geforce GTX 1080 پرچمدار معماری پاسکال
بنابراین مجموع پهنای باند بنا به رابطهی فوق عبارت است از:
گیگابایت بر ثانیه ۳۲۰=۸/(۱۰×۳۲×۸)
همانطور که مشخص است، پهنای باند حافظه در کارت گرافیک پرچمدار با معماری پاسکال بسیار کمتر از کارت پرچمدار تورینگ است.
حافظههای GDDR
در حافظههای GDDR تراشههای حافظه و پردازندهی گرافیکی هر دو به یک PCB (برد مدار چاپی یا Substrate) متصل شده است و مسیرهای ارتباطی نازکی با تعداد مشخص (کانکشنها) از هر تراشه به GPU رفته و باعث ایجاد ارتباط میان پردازنده و حافظهی گرافیکی میشود. عموما ۳۲ مسیر ارتباطی میان هر تراشهی GDDR و پردازندهی گرافیکی تعبیه شده است که از آن به پهنای باس ۳۲ بیتی تعبیر میشود.

قبل از آنکه به بررسی دقیق حافظهی GDDR6 و ویژگیهای آن بپردازیم، خوب است نگاهی کوتاه به مهمترین نسلهای حافظهی GDDR که تا به امروز در کارتهای گرافیک مختلف به کار رفته، داشته باشیم. معروفترین انواع حافظههای GDDR عبارتاند از:
GDDR5
حافظههای GDDR5 پرکاربردترین حافظههای پرسرعتی است که در نسل کنونی کارتهای گرافیک دیده میشود. GDDR5 حافظهی گرافیکی با پهنای باند وسیعتر و توان مصرفی کمتر نسبت به پیشینیان خود است. سرعت انتقال داده (سرعت حافظه) در این حافظهها به 8Gbps میرسد. از این نوع حافظه در کارتهای گرافیک مشهوری نظیر GTX 1060، GTX 1070 و Radeon RX 480 استفاده شده است. هاینکیس، ELPIDA، مایکرون و سامسونگ از مهمترین سازندگان تراشههای GDDR5 هستند. چگالی حافظه در هر تراشهی GDDR5 معمولا ۴ یا ۸ گیگابیت و محدودهی ولتاژ کاری این تراشهها از ۱/۳۵ تا ۱/۵ ولت متغیر است.

GDDR5X
GDDR5X درواقع نسخهی بهبود یافتهی حافظههای GDDR5 است. GDDR5X نسبت به برادر بزرگتر خود دو برابر سرعت بیشتری دارد و میتواند به نرخ انتقال دادهای از ۱۰ تا حداکثر 14Gbps در سطح هر پین تراشه دستپیداکند. انویدیا سرعت تراشههای GDDR5X را در کارتهای گرافیک خود روی عدد 11/4Gbps تنظیم کرده است. در حال حاضر تراشههای GDDR5X تنها توسط شرکت میکرون تولید میشود.
GDDR5X با ولتاژ کاری ۱/۳۵ ولت، توان مصرفی کمتری نسبت به GDDR5 داشته و در ظرفیتهای ۴، ۶، ۸، و ۱۶ گیگابیتی به ازای هر تراشه در دسترس است. باید توجه کرد که روی یک PCB امکان جایگزین کردن حافظههای GDDR5 با GDDR5X وجود ندارد؛ چرا که این دو نوع حافظه از تعداد پینهای متفاوتی استفاده میکنند. درحالیکه تراشهی GDDR5 از ۱۷۰ پین برای اتصال به زیرلایه استفاده میکند، تعداد پینها در GDDR5X برای هر تراشه ۱۹۰ پین است. کارت گرافیک پرچمدار و قدرتمند GTX 1080 انویدیا پذیرای ۸ گیگابایت از این حافظههای سریع است. کارتهای گرافیک دیگری نظیر Nvidia TITAN X و شتابدهندههای گرافیکی ورکاستیشن نظیر Nvidia Quadro P5000 از این حافظهی گرافیکی بهرهمند است.

مروری بر حافظهی گرافیکی GDDR6
پهنای باند حافظه همیشه چالشی برای کارتهای گرافیک بوده است؛ چالشی که با گذر زمان، سختتر و سختتر میشود. بهلطف قانون مور نسل به نسل بر تعداد ترانزیستورهای پردازندههای گرافیکی (و البته تعداد هستههای مختلف در آن) افزوده میشود. این درحالی است که حافظههای DRAM که پهنای باند آن تابع این قانون نیست، روند پیشرفت بسیار کندتری را تجربه میکند.
برآیند خالص چنین روالی این است که رقم پهنای باند حافظهی در دسترس به ازای توان محاسباتی پردازندهی گرافیکی (برحسب فلاپس)، به ازای حجم و کیفیت بافتهای گرافیکی و به ازای آمیزهی پیکسلها بهتدریج افت میکند. در چنین شرایطی برای حفظ سطح عملکرد پردازندهی گرافیکی و ممانعت از ایجاد گلویی (Bottleneck)، سازندگان تراشههای گرافیکی و انواع حافظه هر دو باید به فکر راهی برای افزایش پهنای باند حافظه در مسیر آینده باشند و در عین حال از میزان پهنای باند مورد استفادهی اپلیکیشنهای گرافیکی با روشهایی نظیر فشردهسازی دادهها در حافظه بکاهند. با اینکه هیچکدام از این دو راهحل بهآسانی به نتیجه نمیرسد، انویدیا، غول تراشههای گرافیکی توانسته است در یک دههی گذشته در هر دو زمینه موفق عمل کند. در جدول زیر افزایش نسل به نسل پهنای باند حافظه در کارتهای گرافیکی این شرکت و میزان پهنای باند به ازای هر فلاپ توان محاسباتی پردازندهی گرافیکی (برحسب بیت) ارائه شده است.
پردازنده گرافیکی | توان محاسباتی (ترافلاپس) | نوع حافظهی گرافیکی | پهنای باند به ازای هر واحد فلاپ (بیت) | پهنای باند کلی حافظه گرافیکی |
|---|---|---|---|---|
RTX 2080 | 10.06 | GDDR6 | 0.36 | 448GB/sec |
GTX 1080 | 8.87 | GDDR5X | 0.29 | 320GB/sec |
GTX 980 | 4.98 | GDDR5 | 0.36 | 224GB/sec |
GTX 680 | 3.25 | GDDR5 | 0.47 | 192GB/sec |
GTX 580 | 1.58 | GDDR5 | 0.97 | 192GB/sec |
انویدیا با ارائهی معماری تورینگ و تمرکز بسیار بر رهگیری پرتو و پردازش شبکهی عصبی، جهشی سریع در پهنای باند حافظه رقم زده است. اگر پهنای باند را صرفا برحسب سطح عملکرد هستههای CUDA مورد بررسی قرار دهیم، مقدار این پارامتر به ازای هر فلاپ در معماری تورینگ در مقایسه با پاسکال واقعا افزایش یافته است؛ چرا که توان عملیاتی هستههای کودا در پردازندهی گرافیکی RTX 2080 نسبت به GTX 1080 افزایش چشمگیری نداشته است. اما پردازندهی گرافیکی RTX 2080 هستههای انحصاری و متعددی برای اجرای رهگیری پرتو و آنتی آلیاسینگ مبتنی بر هوش مصنوعی (DLSS) دارد که هر یک به روش خود پهنای باند حافظهی بالایی را اشغال میکند. در مجموع، مشاهده میشود که در بحث محاسبات اعشاری FP32 میزان پهنای باند در دسترس برای هر هسته قدری افزایش یافته است. اما اگر از جنبهی ساختار کلی پردازندهی گرافیکی به موضوع نگاه کنیم، میزان نزاع انواع هستههای گرافیکی نیز برای داشتن پهنای باند بیشتر، فراتر از گذشته است.
نسلهای مختلف پردازندههای گرافیکی شامل پردازندههای ۱۴ یا ۱۶ نانومتری از دیرباز تا بهامروز با گسترهای از حافظههای گرافیکی متنوع کار کردهاند. حافظهی گرافیکی GDDR5 در حدود یک دهه در کارتهای گرافیک بهکار رفته و زمان جایگزین کردن آن با حافظههایی سریعتر فرا رسیده است. مؤسسهی استاندارد JEDEC که تدوین استانداردهای مشترک حافظه را بر عهده دارد، جایگزین کردن حافظههای GDDR5 را از دو مسیر پیگیری کرده است. مسیر اول توسعه و بهبود فناوری GDDR5 بوده که با نام استاندارد GDDR5X شناخته میشود و راهکار بعدی فناوری دیگری با عنوان حافظههای HBM یا حافظه با پهنای باند بالا است که در بخش دیگری از این مقاله در مورد آن بهتفصیل توضیح خواهیم داد.
انویدیا بهدلیل هزینهبر بودن و دشواریهای تولید در روش دوم، از حافظههای HBM تنها در مدلهای محدودی از کارتهای گرافیک سرور خود، از جمله Quadro GP100 و Quadro GV100 استفاده کرده است. در سایر موارد، این شرکت حافظههای گرافیکی GDDR5X را ترجیح داده و جایگزین نسل قبلی کرده است. از سوی دیگر، حافظههای GDDR5X هرگز مقبولیت عام برادر بزرگتر خود GDDR5 را پیدا نکردند. این نوع حافظه تنها توسط شرکت میکرون تولید و تنها توسط انویدیا در برخی مدلهای ردهبالا نظیر کارت پرچمدار سری پاسکال، GTX 1080 مورد استفاده قرار گرفت.
اینجا بود که نسل بعدی فناوری GDDR پا به میدان گذاشت. GDDR6 آخرین و بزرگترین فناوری حافظههای GDDR است. این حافظه برخلاف GDDR5X مقبولیت ویژهای یافته و توسط سه تولیدکنندهی بزرگ حافظه یعنی سامسونگ، هاینکس و میکرون تولید میشود. دراینمیان شرکت انویدیا بهعنوان تنها شرکتی که تاکنون از حافظههای GDDR6 در کارتهای گرافیک خود استفاده کرده است. انویدیا ماژولهای ۱۶ گیگابیتی ساخت سامسونگ را در کارتهای کوادروی خود تعبیه کرده و از ماژول های ۸ گیگابیتی میکرون در کارتهای جدید GeForce RTX با معماریِ بهروز تورینگ استفاده میکند. انویدیا همچنین در ساخت کارت گرافیک GTX 1660 Ti که کارتی با معماری تورینگ اما فاقد ویژگیهای اختصاصی سری RTX همانند رهگیری پرتو است نیز از حافظههای GDDR6 استفاده میکند. پیش از این در زومیت به بررسی جامع مشخصات کارت گرافیک GTX 1660 Ti پرداختهایم. زمزمههایی در مورد بهکارگیری حافظههای GDDR6 در کارتهای گرافیک AMD Navi که در آیندهی نزدیک عرضه خواهد شد نیز به گوش میرسد. سرعت حافظههای GDDR6 بالغ بر ۱۴ گیگابیتبرثانیه بوده و قرار است نسل آیندهی این تراشهها به سرعت 16Gbps یا بالاتر از آن دست یابد.

پهنای باند و سرعت حافظهی GDDR6 در مقایسه با GDDR5 افزایش زیادی یافته، اما در مقایسه با استاندارد بهبودیافتهی GDDR5X چندان قابلتوجه نیست
فناوری حافظهی GDDR6 در مقایسه با GDDR5X به نسبت گذشته گام چندان بزرگی به شمار نمیرود. بسیاری از فناوریهای بهکاررفته در ساخت حافظههای GDDR6 در استاندارد پیشین GDDR5X نیز گنجانده شده بودند. در سری کارتهای گرافیک xx70 انویدیا (مانند GTX 1070)، جایگزینی تراشههای GDDR6 بهجای حافظههای GDDR5 باعث جهش بزرگی در میزان پهنای باند تنها با یک نسل اختلاف میشود. اما برای کارتهای گرافیک xx80، مسئله کمی متفاوت است. در این سری محصولات انویدیا اگرچه جایگزین کردن حافظههای GDDR5X با حافظههای سریعتر GDDR6 تا حدی باعث افزایش پهنای باند میشود، اما درهرصورت این افزایش یک جهش بزرگ به حساب نمیآید.
افزایش پهنای باند تراشههای حافظهی GDDR6 نسبت به GDDR5 ناشی از ایجاد دو تغییر بنیادین در نسل جدید این حافظهها است.
۱- حافظههای GDDR5 میراثدار ویژگیهای حافظهی DDR یا Double Data Rate است. در این حافظه دو واحد داده در هر سیکل کلاک جابهجا و از تراشهی حافظه به کنترلر واقع در پردازندهی گرافیکی یا بالعکس منتقل میشود. درحالیکه باس حافظهی GDDR5 امکان انتقال ۲ واحد داده را در هر کلاک نوشتن (WCK) میدهد، در حافظههای GDDR6 و همچنین GDDR5X این میزان به ۴ واحد داده در هر سیکل کلاک (Quad Data Rate) افزایش مییابد. چنانچه همهی پارامترهای دیگر میان دو نسل حافظه ثابت نگه داشته شود، حافظهی GDDR6 در هر سیکل کلاک دو برابر داده را نسبت به برادر بزرگترش جابهجا میکند. انجام چنین کاری در عمل اصلا ساده نیست و برای افزایش باس حافظه، الزامات یکپارچگی سیگنال سختتری باید لحاظ شود. برای افزایش میزان نقل و انتقال داده در هر سیکل سیگنال حافظه، در عمل کارهای زیادی روی کنترلر حافظه، خود تراشههای حافظه و PCB باید انجام داد.

در گراف آنالیز سیگنال ارائهشده توسط انویدیا برای حافظههای GDDR6 (شکل فوق)، سیگنالی تمیز و پکپارچه دیده میشود که در آن فاصلهی جابجایی میان دو واحد داده بر حسب زمان 70ps است. انویدیا میگوید آنها توانستهاند کراستاک سیگنال را تا ۴۰ درصد کاهش دهند که این خود باعث افزایش یکپارچگی سیگنال و در نتیجه سیگنالدهی سریعتر حافظههای GDDR6 است.
۲- تغییر اساسی دوم در حافظههای جدید GDDR6 روش فراخوانی اطلاعات از سلولهای DRAM است. برای نسلهای متمادی اطلاعات بهصورت رشتههای سری بزرگ و بزرگتر از درون این سلولها خوانده و واکشی (Prefetch) میشد. در شکل زیر روش واکشی داده از آرایهی حافظه در نسلهای مختلف حافظه GDDR دیده میشود.
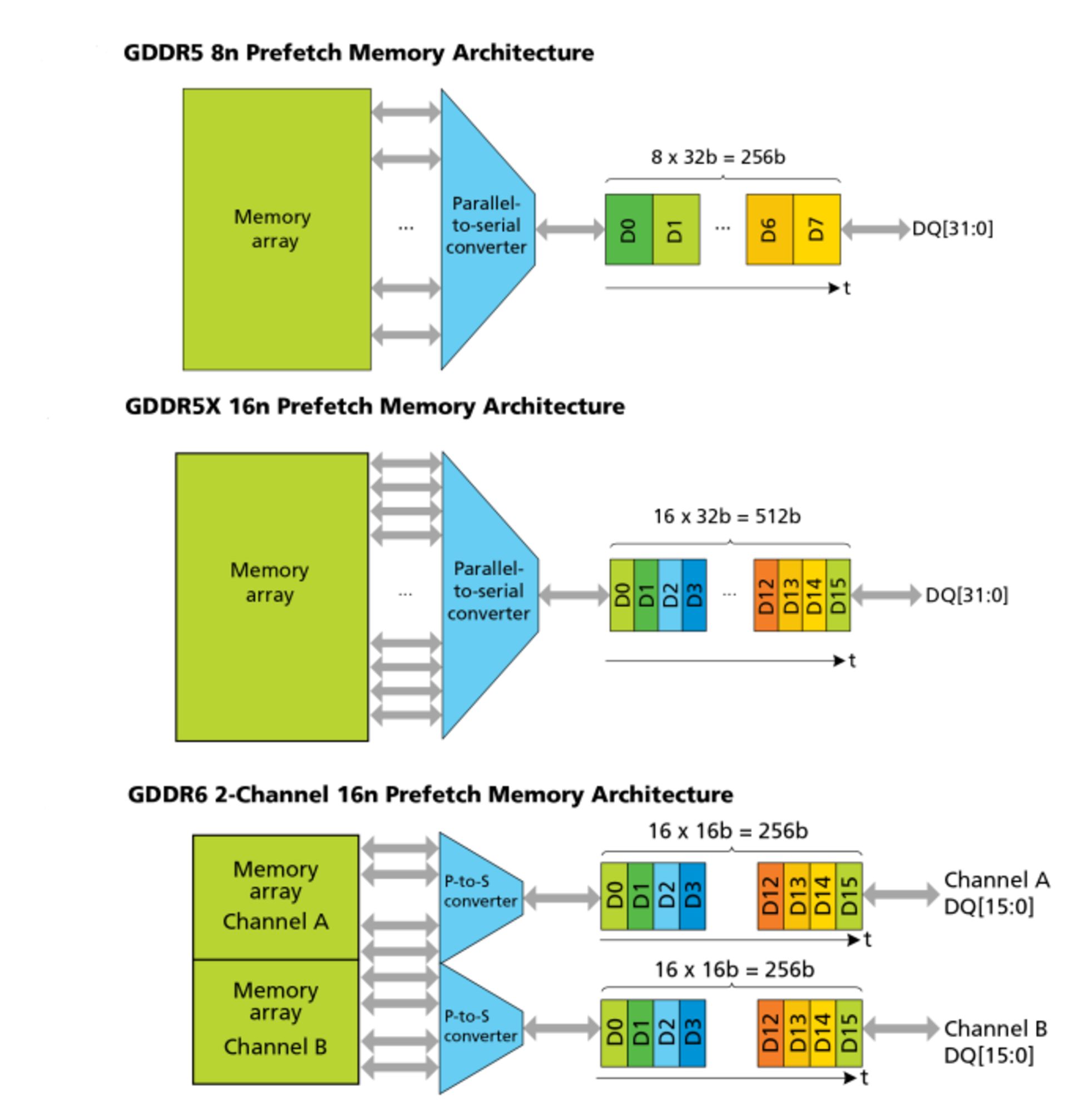
در حافظهی GDDR5 تعداد دادههای واکشیشده در هر سیکل ۸ واحد ۳۲ بیتی و در حافظهی GDDR5X این میزان به ۱۶ واحد ۳۲ بیتی میرسد. اگرچه افزایش حجم دادههای واکشیشده در هر سیکل به ۲۵۶ و ۵۱۲ بیت در این دو نوع حافظه روند رو به افزایشی را نشان میدهد، اما با تسریع پردازندههای گرافیکی این میزان داده برای عملیاتهای کوچک حافظه از میزان بهینه دور و دورتر میشود. در حافظههای GDDR6 میزان دادهی واکشیشده در هر سیکل برابر با استاندارد GDDR5X است؛ اما روش واکشی داده متفاوت است.
در حافظههای GDDR5 و GDDR5X از یک کانال واحد ۳۲ بیتی برای واکشی داده از هر تراشه استفاده میشود، اما حافظهی GDDR6 از دو کانال موازی ۱۶ بیتی برای این کار استفاده میکند. این بدان معنا است که در هر سیکل کلاکِ تراشهی حافظه، ۶۴ بایت داده (۵۱۲ بیت) ازطریق دو کانال ۳۲ بایتی فراخوان میشود. پس حجم دادههای واکشیشده در هر سیکل کلاک حافظهی GDDR6 دو برابر حجم متناظر در حافظهی GDDR5 است که البته اینبار بهصورت یک رشتهی پیوستهی دادهها منتقل نمیشود. در نتیجه هر تراشهی حافظه GDDR6 میتواند شبیه به دو تراشهی مجزا عمل کند و سرعت دسترسی به دادهها را افزایش دهد و از میزان تأخیر بکاهد.
در کارتهای گرافیک امروزی پردازندهی گرافیکی میزان قابلتوجهی داده را بهصورت موازی و پیدرپی با RAM سیستم تبادل میکند و تغییرات معماری یادشده در حافظههای گرافیکی تأثیر چندانی بر میزان عملکرد کلی ندارد. با این وجود تجزیهی مسیرهای دسترسی به داده به کانالهای کوچکتر در استاندارد GDDR6 کارایی دسترسی تصادفی را در مقایسه با GDDR5X و حجم دادهی در دسترس ۶۴ بایتی آن بهبود میبخشد.
اما تغییرات تراشههای حافظه GDDR6 به آنچه گفته شد، خلاصه نمیشود. در این حافظهها توان مصرفی نسبت به نسلهای قبل کاهش یافته یا بهتر است بگوییم که از ادامهی رشد توان مصرفی در حافظههای گرافیکی نسل جدید ممانعت میشود. ولتاژ کاری استاندارد حافظهی GDDR6 معادل ۱.۳۵ ولت است که برابر با استاندارد GDDR5X و کمتر از مقدار ۱.۵ ولت در استاندارد GDDR5 است. انویدیا میگوید بازدهی توانی را نسبت به حافظهی GDDR5X و معماری پاسکال تا ۲۰ درصد بهبود داده و بی شک این میزان بهبود نسبت به استاندارد حافظهی GDDR5 در معماری پاسکال بیشتر نیز هست.
در جدول زیر، مشخصات حافظهی گرافیکی از نسلهای مختلف در برخی از کارتهای گرافیک انویدیا ارائه شده است.
مشخصات | GeForce RTX 2080 Ti (GDDR6) | GeForce RTX 2080 (GDDR6) | Geforce RTX 2070 (GDDR6) | GeForce GTX 1080 (GDDR5X) | Geforce GTX 1070 (GDDR5) |
|---|---|---|---|---|---|
میزان حافظهی گرافیکی (GB) | 11 | 8 | 8 | 8 | 8 |
پهنای باند به ازای هر پین (Gb/s) | 14 | 14 | 14 | 11 | 8 |
ظرفیت تراشهی حافظه (GB) | 1 | 1 | 1 | 1 | 1 |
تعداد تراشهها در کارت | 11 | 8 | 8 | 8 | 8 |
پهنای باس حافظه (bit) | 352 | 256 | 256 | 256 | 256 |
مجموع پهنای باند (GB/s) | 616 | 448 | 448 | 352 | 256.3 |
ولتاژ کاری تراشه (V) | 1.35 | 1.35 | 1.35 | 1.35 | 1.5 |
مروری بر حافظهی HBM
HBM یا حافظه با پهنای باند بالا (High Bandwith Memory) حافظهی غیرصفحهای با ساختاری سهبعدی به شکل مکعب یا مکعب مستطیل است. برای ساخت این حافظهها چند تراشهی حافظه یکی پس از دیگری با روشهای لحیمکاری خاص روی هم انباشته شده و تشکیل یک تودهی مکعبی را میدهند. این نوع طراحی باعث اشغال فضای کمتر روی PCB شده و حتی میتوان آن را در مجاورت کامل پردازندهی گرافیکی قرار داد. بسته به نوع طراحی، یک یا چند تودهی حافظه (Stack)، پردازندهی گرافیکی را احاطه میکند. هر تودهی حافظهی HBM مستقل از تودهی دیگر است، اما همه تودهها در ارتباط با یکدیگر کار میکنند. حافظههای HBM بهدلیل فرم فاکتور کوچکتر با اسامی دیگری نظیر حافظهی فشرده و حافظهی تودهای نیز شناخته میشود.

روش ایجاد ارتباط میان حافظههای HBM و پردازنده کاملاً متفاوت با حافظههای GDDR است. در اینجا از لایهی اضافی دیگری با نام اینترپوزر (Interposer) برای افزایش تعداد اتصالات میان پردازنده و حافظهی گرافیکی استفاده میشود. یک تودهی حافظه HBM متشکل از چهار تراشهی DRAM متصل به هم (یا تعداد ۸ تراشهی حافظه در HBM2) است که روی یک تراشهی منطقی (Logic Die) و کل این پکیج روی اینترپوزر (Interposer) قرار گرفته است. پردازندهی گرافیکی نیز روی همین لایه تعبیه شده و با تودههای حافظه ازطریق اتصالات ظریف پرتعدادی که از درون اینترپوزر میگذرد، در ارتباط است.
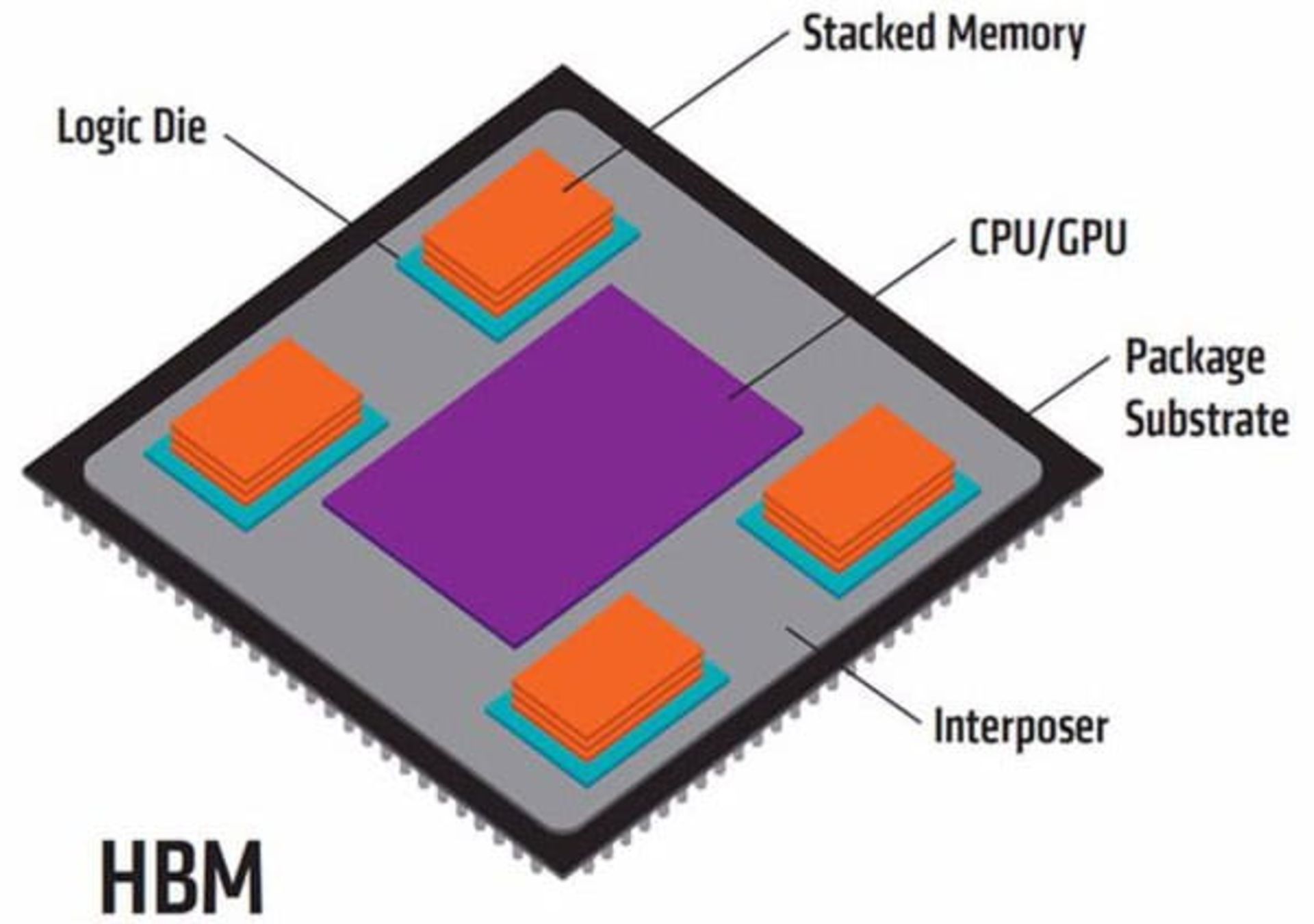
اینترپوزر یک Die سیلیکون است که با استفاده از فرآیندهای ساخت قدیمیتر و بزرگتر تولید میشود. این لایه کاملاً پسیو است و ترانزیستور فعالی در خود ندارد و از آن بهعنوان لایهای که در بردارندهی تمامی مسیرهای ارتباطی یا کانکشنها میان پردازندهی گرافیکی و تودههای حافظه است، استفاده میشود. این لایه هماهنگی و یکپارچگی نزدیکتری میان تراشههای DRAM و GPU ایجاد میکند. یک تراشهی پکیج ارگانیک (Package Substrate) در زیر لایهی اینترپوزر قرار گرفته که درواقع همان PCB بوده و وظیفهی آن تبادل داده با رابط PCI Express، خروجی تصویر و اینترفیسهای دیگر با فرکانس پایین است. تمامی ارتباطات پرسرعت مابین پردازندهی گرافیکی و تراشههای حافظه در لایهی اینترپوزر صورت میپذیرد. باتوجهبه اینکه اینترپوزر یک تراشهی سیلیکون است، در مقایسه با لایهی Package Substrate بسیار چگالتر بوده و دربرگیرندهی اتصالات و کانکشنهای بسیار بیشتر در یک ناحیهی مفروض است. تعداد بسیار بیشتر این کانکشنها بهمعنای پهنای باند بیشتر در مقایسه با حافظههای GDDR است.
خلاقیت اصلی در ساخت حافظهی HBM، پیکربندی چند سطحی تراشههای حافظه است
با وجود ظرفیت سنگین ارتباطی لایهی اینترپوزر، خلاقیت اصلی در پیکربندی HBM تعبیهی تودههای حافظه است. هر تودهی حافظه HBM حداقل شامل پنج تراشه است؛ ۴ تراشهی DRAM و یک Die منطقی واحد که کنترل این چهار تراشه را بر عهده دارد. این ۵ تراشه ازطریق اتصالات عمودی ویژهای با نام Through-Silicon Vias یا TSVبه یکدیگر متصل شده است. این مسیرهای ارتباطی با تعبیهی سوراخهایی در ضخامت تراشههای ذخیرهسازی ایجاد میشود. تراشههای ذخیرهسازی با ضخامتی در حدود ۱۰۰ میکرون به طرز شگفتانگیزی باریک است و اگر یکی از آنها را در دست بگیریم، مثل یک برگ کاغذ انعطافپذیر است. گردههای فلزی لحیم ما بین لایههای تودهی HBM میکروبامپ (Microbump) نام داشته و ستونهایی عمودی را که درواقع مسیر ارتباطی نسبتاً کوتاهی از Die منطقی به هر یک از تراشههای DRAM است، شکل میدهد.
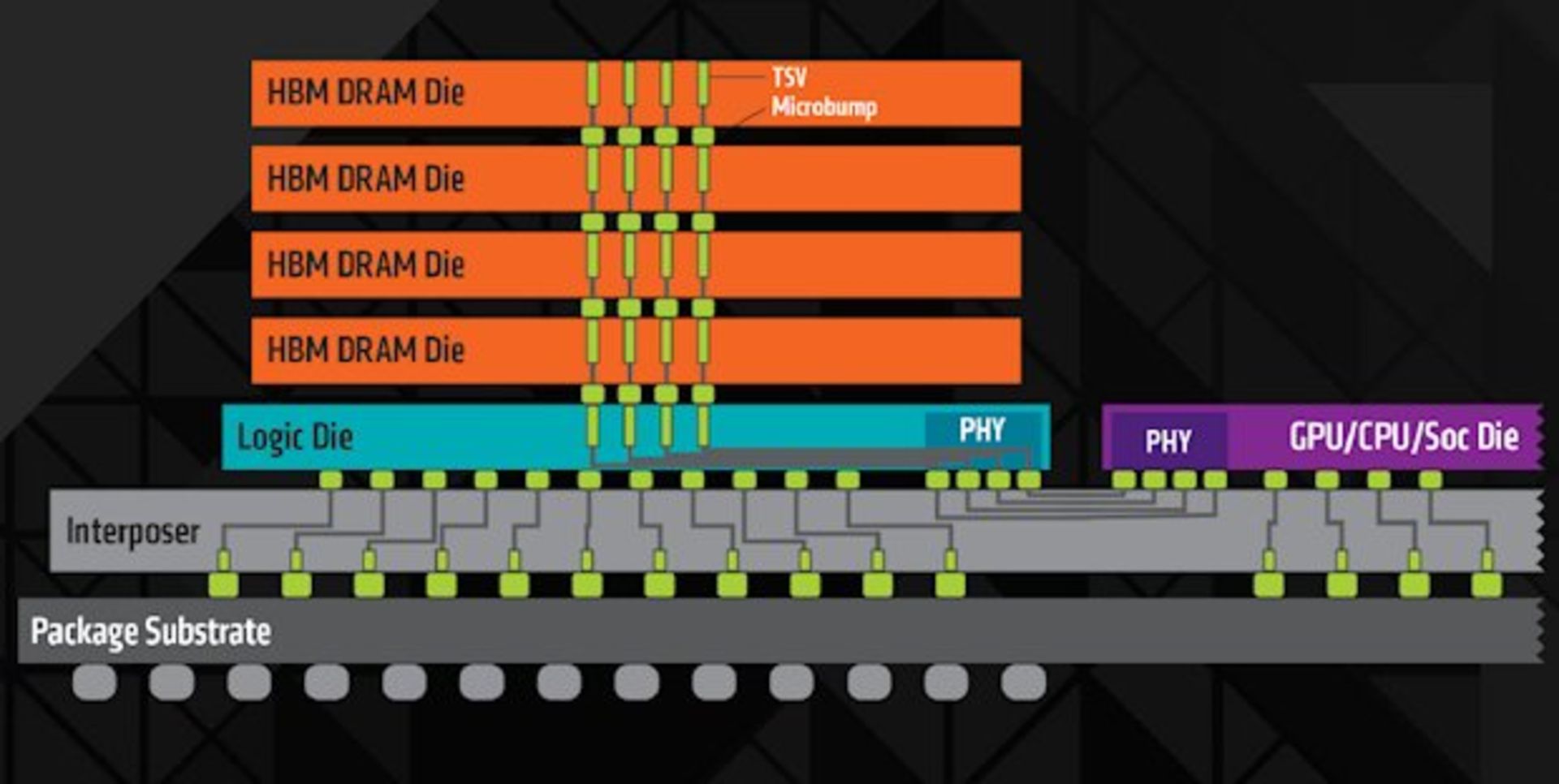
هر یک از تراشههای DRAM در برگیرندهی نوع جدیدی از حافظه است که برای بهرهگیری از مزایای جانمایی فیزیکی متمایز استاندارد HBM به کار میرود. شرکت سامسونگ و هاینکس در حال حاضر به تولید این تراشهها میپردازند. از این نوع حافظه در ساخت برد کارت گرافیک Radeon Fury X ساخت AMD استفاده شده که نحوهی جانمایی حافظه در اطراف پردازندهی گرافیکی در شکل زیر مشخص است. این کارت دربرگیرندهی ۴ گیگابایت حافظهی گرافیکی HBM با مجموع پهنای باند 512GB/s است.

ولتاژ کاری استاندارد حافظهی HBM در مقایسه با GDDR5 نسبتاً کمتر (۱.۳ ولت در مقابل ۱.۵ ولت) است و با فرکانس کلاک کمتری (۵۰۰ مگاهرتز در مقابل ۱۷۵۰ مگاهرتز) کار میکند. سرعت استاندارد انتقال دادهی تراشهی HBM (یا همانطور که پیش از این گفته شد، پهنای باند به ازای هر پین) ۱ گیگابیتبرثانیه است که در مقایسه با سرعت حافظهی GDDR5 معادل ۷ گیگابیتبرثانیه به میزان چشمگیری پایینتر است؛ اما باتوجهبه وجود اتصالات بسیار بیشتری میان پردازنده و تراشههای حافظه به واسطهی وجود لایهی اینترپوزر، پهنای باند حافظهی HBM به مراتب بیشتر است. البته سرعت تراشههای HBM در نسل دوم (HBM2) باز هم افزایش یافته که در ادامهی این مقاله پیرامون آن صحبت خواهیم کرد. در شکل زیر مقایسهی بهتری میان پارامترهای استاندارد دو نوع حافظهی HBM و GDDR5 ارائه شده است.
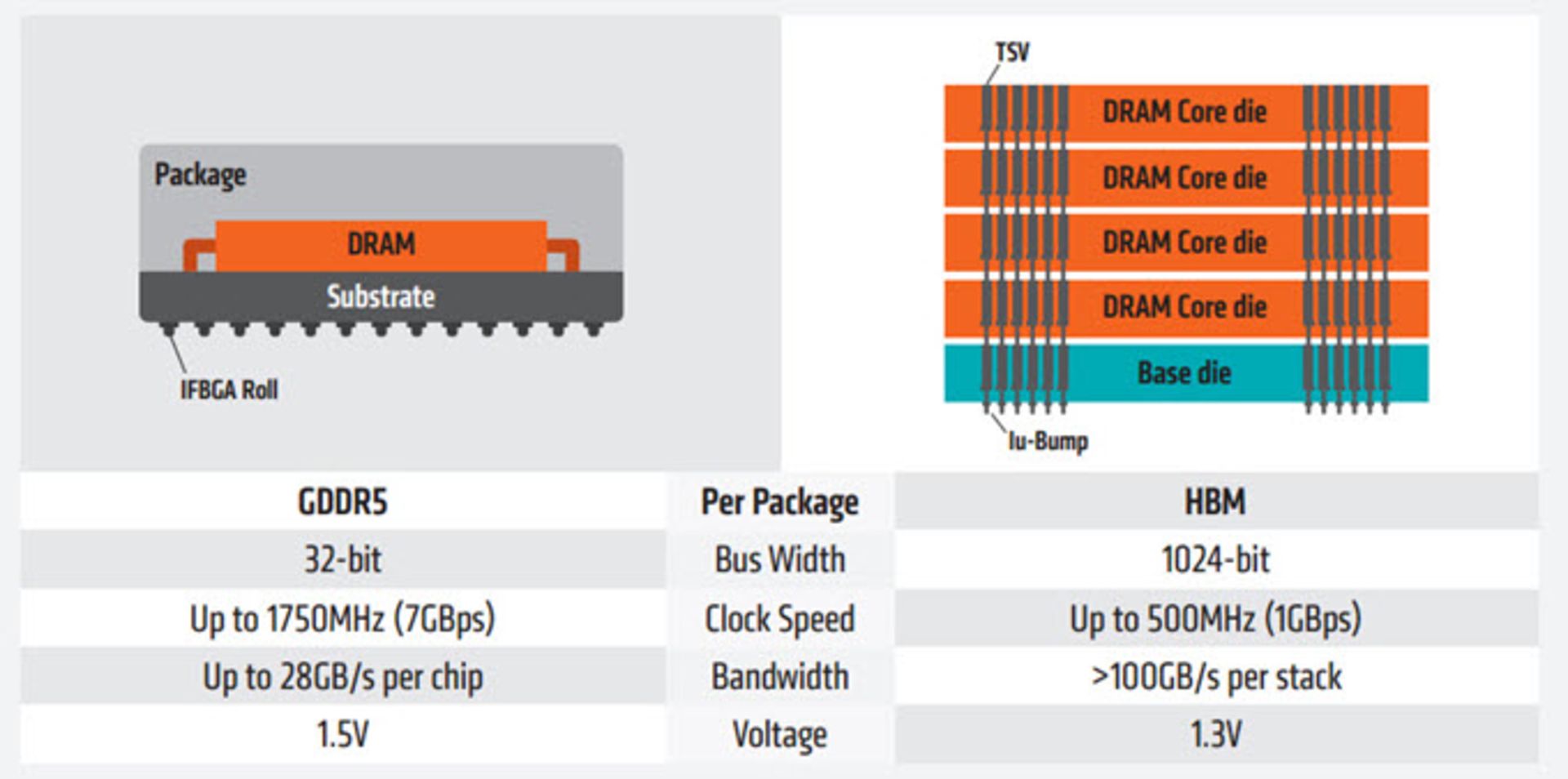
هر تراشهی DRAM در پیکربندی HBM ازطریق دو کانال با پهنای باس ۱۲۸ بیت با منابع بیرونی ارتباط برقرار میکند. بنابراین هر تودهی متشکل از چهار تراشهی DRAM در مجموع پهنای باسی برابر با ۱۰۲۴ بیت دارد که در مقابل پهنای باس ۳۲ بیتی هر تراشهی GDDR5 بارها بیشتر است. در چنین شرایطی اگر سرعت استاندارد هر تراشهی HBM معادل 1Gb/s باشد، پهنای باند هر تودهی حافظه 128GB/s خواهد بود (دقت شود که میزان پهنای باند هر توده مستقل از حجم حافظهی به کار رفته در آن است). طبق رابطهی بیان شده در ابتدای این مقاله پهنای باند به شکل زیر محاسبه میشود:
128bit*2 channels*1 Gbps*4)/8=128 GB/s)
در نسل دوم حافظههای HBM یا HBM2 سرعت استاندارد هر تراشهی DRAM به 2Gb/s میرسد. در این حالت پهنای باند هر توده ازطریق رابطهی زیر به دست میآید:
128bit*2 channels*2 Gbps*4)/8=256 GB/s)
لذا پهنای باند هر توده حافظهی HBM2 رقمی معادل ۲۵۶ گیگابایت بر ثانیه است. اگر پیکربندی حافظهای مشابه کارت گرافیک Radeon VII در دست باشد که در آن ۴ توده حافظهی HBM2 پردازندهی گرافیکی را روی اینترپوزر احاطه کرده است، در این شرایط حداکثر پهنای باند بالغ بر یک ترابایت بر ثانیه است که رقمی بهراستی شگفتانگیز است. این رقم در مقایسه با پهنای باند حافظهی گرافیکی GDDR6 در کارت گرافیک پرچمدار GeForce RTX 2080 انویدیا برابر با ۳۵۱ گیگابایت بر ثانیه، به میزان چشمگیری بیشتر است. البته بایستی توجه داشت که میزان زیادی از این پهنای باند ممکن است در بیشتر اپلیکیشن ها و محیطهای گرافیکی بلا استفاده بماند که در ادامهی این مقاله در مورد آن بیشتر صحبت خواهیم کرد. گفتنی است تراشههای حافظه HBM مورد استفاده در این کارت گرافیک AMD ساخت شرکت هاینکس بوده و تراشهی اینترپوزر را شرکت UMC تولید کرده است. AMD حافظههای HBM2 را در ساخت کارتهای گرافیک Radeon RX Vega 64 و Radeon VII به کار برده است. در شکل زیر، خصوصیات پردازندهی گرافیکی این دو کارت با یکدیگر مقایسه شده است.

مقایسه HBM و HBM2
مهمترین تفاوت نسل اول و دوم حافظههای HBM در سرعت انتقال دادهی تراشهی DRAM و تعداد تراشههای قابل انباشت در هر توده است. در استاندارد HBM2 امکان انباشت ۸ تراشهی DRAM در هر توده وجود دارد و چگالی حافظه در هر توده حداکثر ۸ گیگابایت است. این در حالی است که در نسل اول این استاندارد هر تودهی حافظهی HBM شامل ۴ تراشهی DRAM با حداکثر چگالی ۱ گیگابایت به ازای هر توده است. همانطور که گفته شد سرعت استاندارد تراشه در حافظهی HBM معادل 1Gb/s و پهنای باند به ازای هر توده 128GB/s است. سرعت هر تراشهی DRAM در استاندارد نسل دوم HBM2 رقمی معادل 2Gb/s است و پهنای باند قابل دستیابی در تودهی ۸ سطحی ذخیرهسازی (8Hi) بالغ بر 307GB/s است. هماینک از این حافظهها درکارتهای گرافیک ورکاستیشن با ظرفیت ۳۲ گیگابایت و پهنای باند سرسام آوری بالغ بر ۱.۲ ترابایت بر ثانیه استفاده میشود.
نسل دوم حافظههای HBM2 ساخت سامسونگ با نام Aquavolt بهصورت تودههای ۸ سطحی و با سرعت 2.4Gb/s در ولتاژ ۱.۲ ولت تولید میشود. برای مقایسه بهتر است بدانیم حداکثر سرعت قابل دستیابی در حافظههای نسل اول HBM در ولتاژ کاری ۱.۲ ولت، ۱.۶ گیگابیتبرثانیه و در ولتاژ ۱.۳۵ ولت، حداکثر ۲ گیگابیتبرثانیه است؛ بنابراین حافظههای HBM2 سرعت بسیار بالاتری را ارائه میدهد. سامسونگ با بهینهسازی اتصالات TSV و پایش حرارتی بهتر تراشههای HBM2 سطح عملکرد آنها را نسبت به سطوح استاندارد ارتقاء چشمگیری داده است. برایناساس، این شرکت موفق به ساخت تودههای ۸ سطحی با تراشههای DRAM با ظرفیت ۸ گیگابایت شده است که با بیش از پنج هزار TSV به ازای هر تراشه، بهصورت عمودی با یکدیگر در ارتباط هستند. این شرکت بامپهای بیشتری در فضای میان تراشهها برای دفع بهتر حرارت مازاد ایجاد کرده و لایهی محافظی به همین روش در زیر تودهی تراشهها ایجاد کرده است.

سامسونگ در کنفرانس اخیر فناوری پردازندههای گرافیکی انویدیا (GTC)، حافظههای پهنباند HBM جدید خود با نام فلشبولت (Flashbolt) را نیز رونمایی کرد. حافظهی فلشبولت اولین محصول صنعتی است که منطبق بر مشخصههای استاندارد بهبودیافتهی HBM2E است. HBM2E استانداردی است که در آن پهنای باند بهازای هر پین تا ۳۳ درصد افزایش مییابد و از ۲.۴ به ۳.۲ گیگابیتبرثانیه میرسد. در این استاندارد، ظرفیت هر تراشهی DRAM حداکثر ۱۶ گیگابیت (۲ گیگابایت) است که این میزان، دوبرابر استاندارد قبلی HBM2 است. بدینترتیب هر تودهی حافظهی فلشبولت با پهنای باس ۱۰۲۴ بیتی و پهنای باندی تا ۴۱۰ گیگابایتبرثانیه به ازای هر توده و ۱۶ گیگابایت حافظه در پیکربندی ۸ سطحی (8Hi) ارائه خواهد شد.
گفتنی است نسل سوم حافظههای HBM یا HBM3 نیز در آیندهی نزدیک عرضه خواهد شد که میزان حافظه را در کارتهای گرافیک به ۶۴ گیگابایت رسانده و پهنای باند در آن به ازای هر توده به رقم حیرتآور ۵۱۲ گیگابایت بر ثانیه خواهد رسید. قرار است این حافظهها در سال ۲۰۲۰ توسط شرکتهای بزرگی مانند سامسونگ به تولید انبوه رسیده است و در کارتهای گرافیک ردهبالا مورد استفاده قرار گیرد.
مزایای حافظههای HBM
شاید اصلیترین مزیت حافظههای HBM در مقایسه با GDDR5 حداکثر نرخ انتقال دادهی بالاتر حافظههای HBM در توان مصرفی معین است. حافظهی GDDR5 به ازای هر وات توان مصرفی قادر است 10.66GB/s را انتقال دهد، این رقم در حافظهی HBM به ازای هر وات توان مصرفی بیش از 35GB/s است.
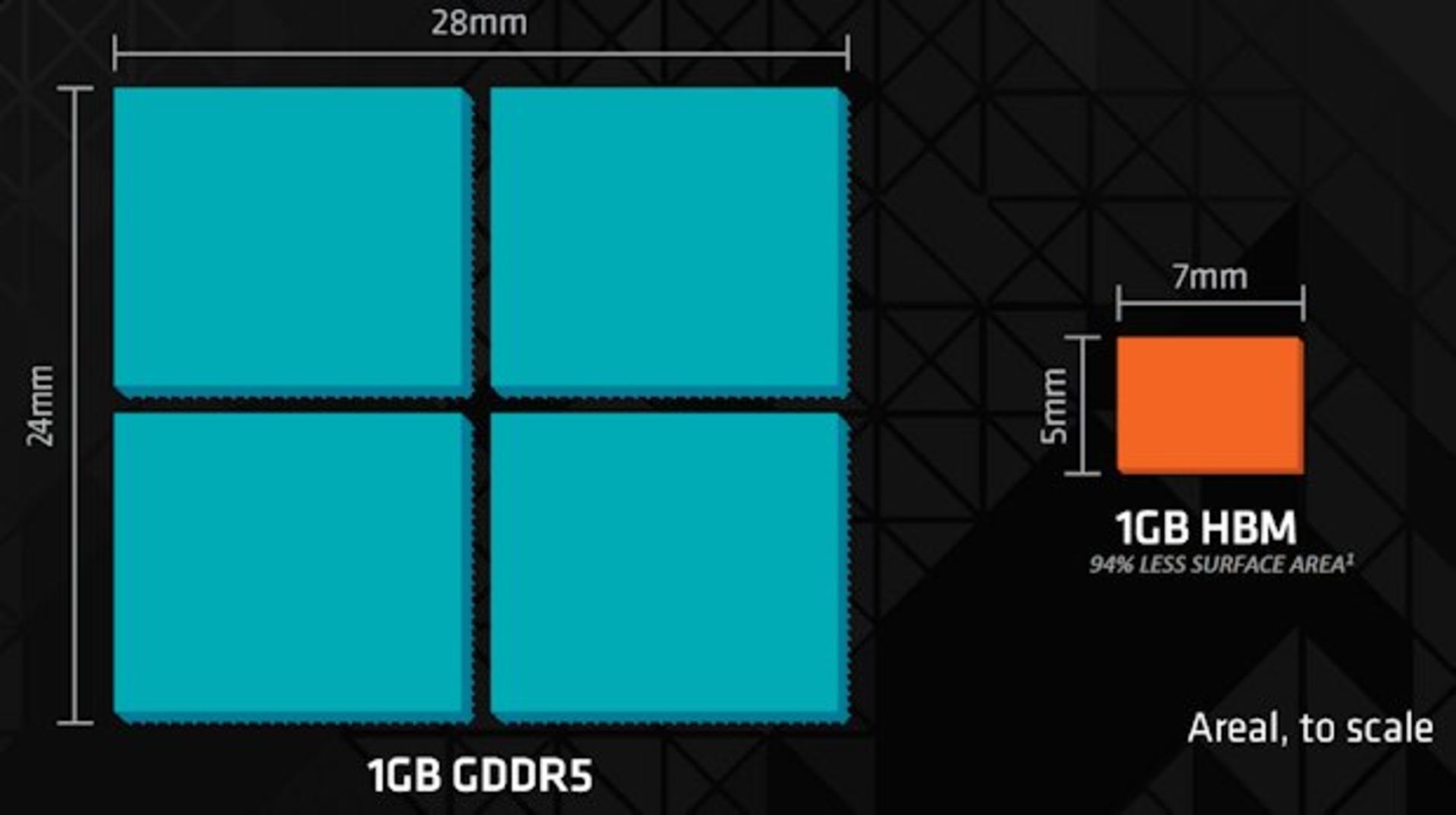
حافظهی HBM بیتهای بسیار بیشتری را نسبت به GDDR5 در فضای کوچکتری فشرده میکند. یک گیگابایت حافظهی HBM تنها ۳۵ میلیمتر مربع فضا اشغال میکند. در مقابل هر تراشهی GDDR5 مساحتی معادل ۶۷۲ میلیمتر مربع دارد. برایناساس، نسلهای مختلف حافظهی HBM راهکاری بهمراتب فشردهتر را برای استفاده در فضاهای محدودتر نظیر بردهای گرافیکی فراهم میکند. بهنظر میرسد حافظههای HBM باتوجهبه مزایای متعددی که دارد، بهتدریج راه خود را در سایر راهکارهای سختافزاری نیز باز کند.
تأخیر دسترسی به دادهها در حافظههای HBM نیز کمتر از دیگر حافظههای گرافیکی است. بهدلیل آنکه مسیر حرکت دادهها بهطور عمودی از میان توده میگذرد، میزان جابهجایی افقی روی هر تراشهی DRAM بسیار کوچک است. با وجود کانالها و بانکهای بیشتر، حافظههای HBM رفتار دسترسی تصادفی کاذب بسیار بهتری نیز دارند. همچنین زیرسیستمهای کلاکینگ در این حافظههای پهنباند سادهتر بود و تأخیرهای کمتری را تحمیل میکند.
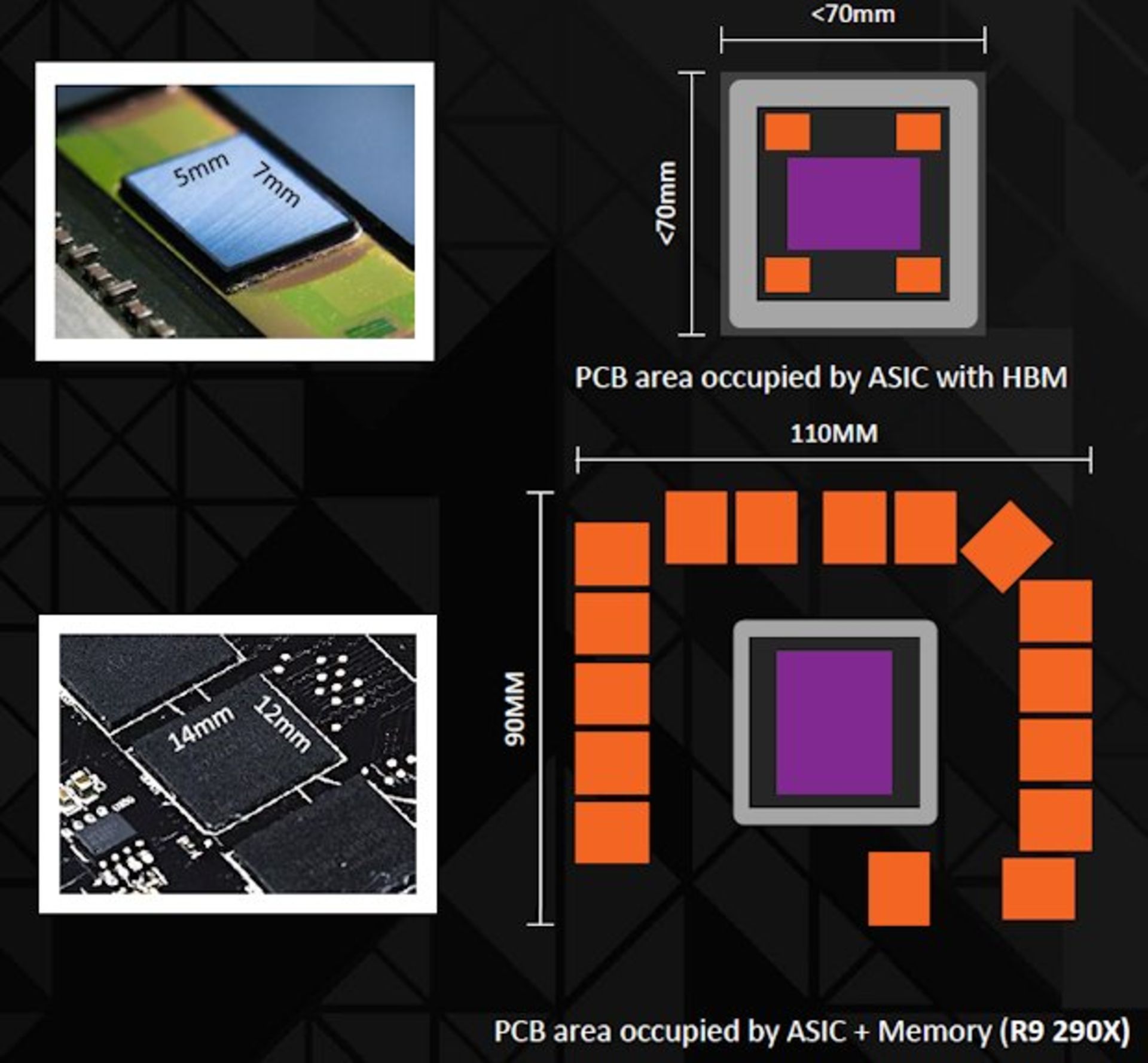
مزیت دیگر حافظهی HBM این است که فضای Die کمتری را درکنار پردازندهی گرافیکی میزبان در مقایسه با GDDR اشغال میکند. رابطهای فیزیکی (PHY) روی تراشه سادهتر هستند و باعث حفظ فضای بیشتری میشود. اتصالات خارجی این تراشهها در اینترپوزر با گامهای بسیار ظریفتری نسبت به یک Substrate سنتی ارگانیک چیده شده؛ چرا که اینترپوزر یک تراشهی فشردهی بسیار چگال است. با هرچه ظریفتر شدن رشتههای اتصال در یک فضای فشردهی اینچنینی، تعداد بسیار بیشتری از این اتصالات قابل طراحی و تعبیه است.
GDDR6 یا HBM2؟
در مقایسهی دو نوع حافظهی GDDR6 و HBM2 بیش از آنکه بهدنبال برتری یکی در سطح عملکرد خالص نسبت به دیگری باشیم، بایستی بهدنبال دادوستدهای هر طراحی که تیم مهندسی در پی اجرای آن بوده است، باشیم. همانطور که گفته شد، پهنای باند حافظهی HBM در مقایسه با استاندارد GDDR5 یک مزیت غیرقابلانکار به شمار میرود. از آنجایی که در آخرین نسل حافظههای GDDR یا GDDR6 پهنای باند حافظه برای گیمینگ و محیطهای گرافیکی در سطح مطلوبی است، مقایسهی آخرین استانداردهای GDDR و HBM از نظر میزان پهنای باند در درجهی کمتری از اهمیت قرار دارد. باوجوداین، حافظهی HBM2 از وجوهی نسبت به GDDR6 برتری و رجحان دارد.
اگرچه سرعت جابجایی داده به ازای هر پین در حافظههای GDDR6 با رقمی معادل ۱۴ گیگابیتبرثانیه نسبت به حافظهی HBM2 با سرعتی معادل ۲ گیگابیتبرثانیه بسیار بیشتر است، اما بایستی در نظر داشت که تعداد پینهای حافظهی GDDR6 بسیار کمتر از رقیب پهنباند خود است. به این مورد بایستی مصرف توان کمتر حافظههای HBM2 را نیز اضافه کرد.

باوجود مزایایی که استفاده از حافظهی HBM2 در کارتهای گرافیک به همراه دارد، تمایل زیادی به استفاده از این نوع حافظهها در میان قطعهسازان اصلی دیده نمیشود. پیچیدگیهای فرایند طراحی و هزینهی بالاتر این حافظهها مانعِ استفاده از آنها در کارتهای پایینرده میشود. حافظههای HBM2 بیشتر در جایی کاربرد دارند که نیاز به پهنای باند بسیار بالا است و درعینحال، توان مصرفی و هزینههای مرتبط با آن با محدودیتهایی روبهرو باشد. پردازندههای گرافیکی مرکز داده که بر محاسبات هوش مصنوعی متمرکز است یا تراشههای محاسباتی بسیار چگال که در کلاسترهای HPC کار میکند، نمونههایی از این کاربردها است.
استفاده از حافظههای HBM2 بار کاری RAM سیستم را در محاسبات گرافیکی کاهش میدهد و بدین ترتیب مقدار زیادی از ظرفیت سیستم بلااستفاده میماند. به نظر میرسد که حافظههای HBM2 با وجود حافظههای پهن باند و ارزان GDDR6 چندان در سختافزارهای مصرفی مورد استقبال قرار نگیرد.
شواهدی وجود دارد که AMD قصد دارد در کارتهای گرافیک ۷ نانومتری Navi از حافظهی گرافیکی GDDR6 استفاده کند. بنابراین با وجود اینکه AMD در ساخت کارت گرافیک ۷ نانومتری پیشین خود یعنی Radeon VII از ۱۶ گیگابایت حافظهی HBM2 استفاده کرد، ممکن است در تولید کارتهای گیمینگ ردهبالای آیندهی خود، استفاده از این نوع حافظه را متوقف کند.