
چه چیزی باعث برتری پردازندههای سرور EPYC Rome نسبت به Xeon 9200 میشود


تا عرضهی پردازندههای سرور EPYC Rome مبتنی بر معماری ۷ نانومتری Zen 2 زمان چندانی باقی نمانده و انتظار میرود که AMD با آغازبهکار نمایشگاه Computex 2019 در ماه آینده، عرضهی این پردازندههای قدرتمند را آغاز کند. تاکنون دیدگاه خوبی نسبت به معماری نهفته در پردازندههای سرور Rome و طراحی نوآورانهی چیپلتهای آن به دست آوردهایم، اما همچنان برخی از ویژگیهای کلیدی این تراشهها توسط شرکت سازنده توصیف نشده است. بهلطف اطلاعات وبسایت ServerTheHome اینک اطلاعات خوبی در مورد یکی از ویژگیهای کلیدی پردازندههای سرور آیندهی AMD در دست داریم که اگر درست باشند، این محصولات را پیروز میدان رقابت با پردازندههای مشابه ساخت اینتل خواهند کرد.
این وبسایت در پی دسترسی به برخی از اطلاعات، دریافته است که پردازندههای EPYC Rome تعداد مسیرهای ارتباطی PCI Express بیشتری نسبت به آنچه پیشبینی میشد، دارد.
اکنون میدانیم که یک پردازندهی واحد EPYC Rome دارای ۱۲۸ مسیر ارتباطی نسل چهارم PCIe است؛ اما سیستمهای سروری که با این پردازندهها کار میکنند، درواقع از یک آرایش دو سوکته استفاده میکنند. این نوع پیکربندی دو سوکته بهطور مستقیم در تقابل با سبد محصولات Xeon Platinum 9200 شرکت اینتل قرار خواهد گرفت که قرار است با همین پیکربندی ارائه شوند.

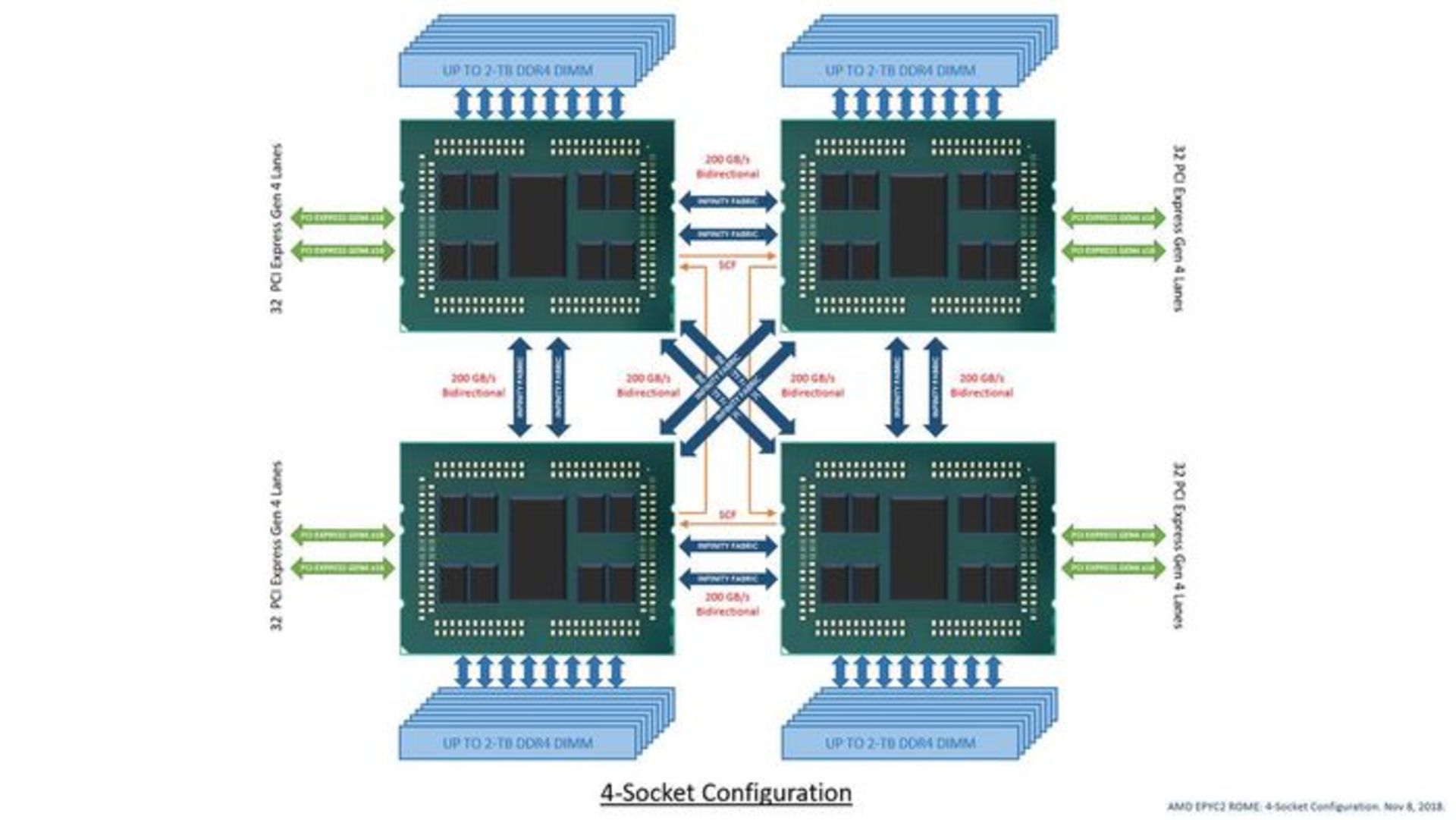
پردازندهی اینتل Xeon Platinum 9200 از ۴۰ مسیر PCIe نسل سوم برخوردار است و باتوجهبه استفاده از راهکار استفاده از دو تراشه روی دو سوکت، در مجموع ۸۰ مسیر ارتباطی نسل سوم PCIe فراهم خواهد شد. بدین ترتیب حتی یک پردازندهی واحد سری رُم اپیک تعداد مسیر ارتباطی PCIe بیشتری نسبت به یک پیکربندی دو سوکت (2S) اینتل دارد. بنا بر پیکربندیهای احتمالی به شرح زیر، تنها راهکار 4S و 8P اینتل میتواند درنهایت تعداد مسیرهای ارتباطی بیشتری را ارائه کند.
در عین حال بزرگترین مزیت پردازندههای AMD نسبت به محصولات اینتل، این است که استاندارد نسل چهارم PCIe بهکاررفته در آن پهنای باند دو برابری نسبت به نسل سوم این استاندارد در پردازندههای اینتل دارد. این مسئله درکنار ویژگی بهروزرسانیشدهی Infinity Fabric در پردازندههای سرور AMD باعث تقویت چشمگیر عملکرد این پردازندهها میشود. درحالیکه Infinity Fabric تا پیش از این برای برقراری ارتباطات داخل تراشه بر سرعتهای نسل سوم PCIe تکیه داشت، برخورداری از نسل چهارم PCIe بدین معنا است که Infinity Fabric ظرفیت کمتری از مسیرهای ارتباطی PCIe را اشغال میکند و سرعتهای تراشه به تراشه، سوکت به سوکت و پهنای باند I/O بهبود مییابد.
از آنجایی که پهنای باند آزادی در دسترس است، اتکای کمتری بر لینکهای x16 میان دو تراشه وجود خواهد داشت. ممکن است به این روش میزان انعطافپذیری بیشتر شود و این امکان برای شرکای تجاری AMD که به این پهنای باند مازاد نیازی ندارند، فراهم است که بهجای استفاده از این پهنای باند بهعنوان یک لینک داخلی پرسرعت، آن را برای مقاصد عملی به کار بندند.
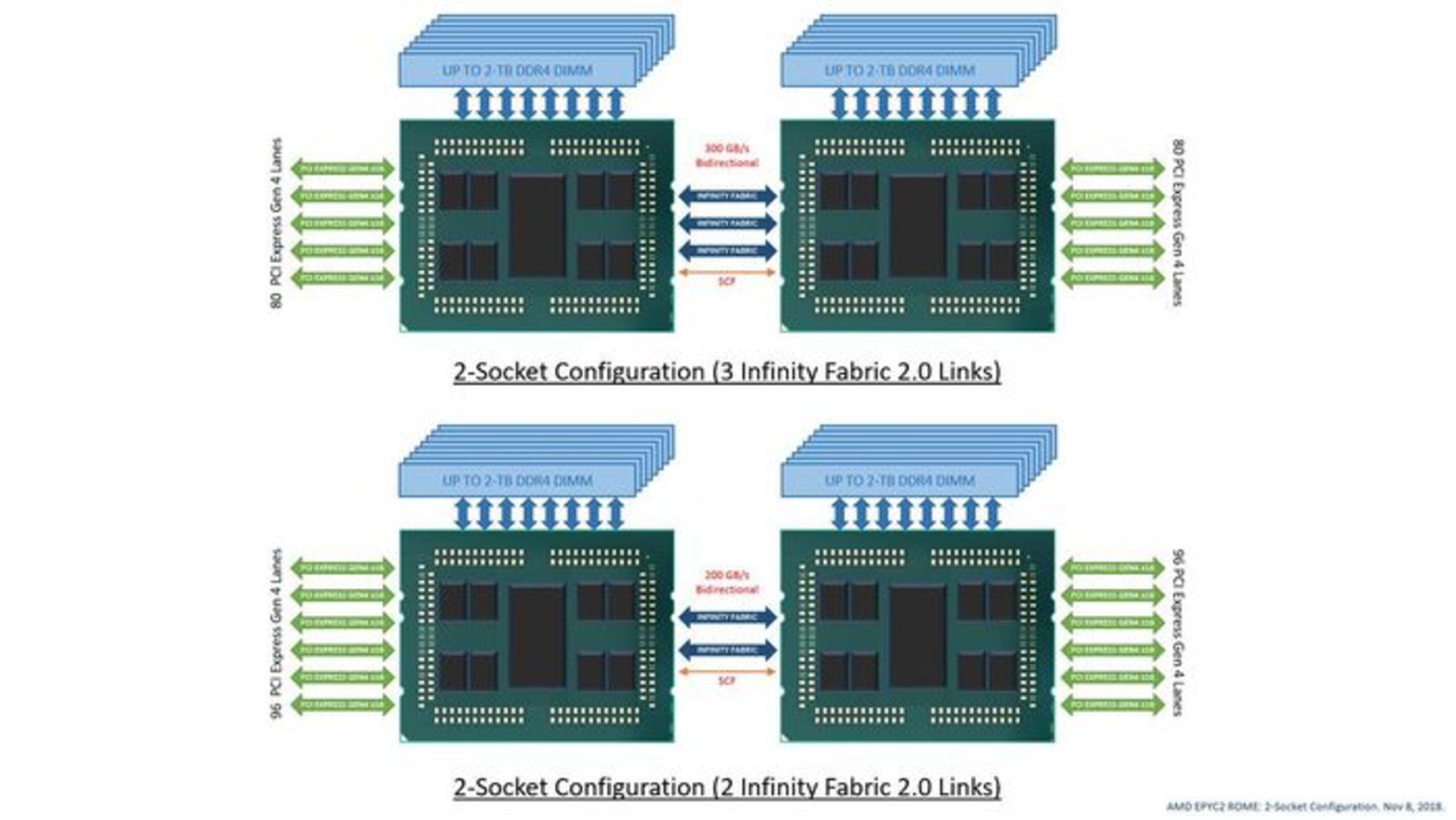
برخورداری از سه لینک x16 بهجای ۴ لینک، امکان بهرهبرداری از مسیرهای ارتباطی PCIe را خارج از کانال ارتباطی Infinity Fabric فراهم خواهد ساخت. بدین ترتیب اتصالات PCIe نسل چهارم بیشتری تا ۱۶۲ مسیر ارتباطی در اختیار کاربران قرار میگیرد. منطقی است که تصور کنیم بسیاری از شرکا این راه را در پیش نگیرند؛ چرا که کاهش پهنای باند برای I/O تراشه به تراشه رویکردی ایدهآل نیست؛ اما بههرحال AMD آن را بهعنوان یک مسیر قابل انتخاب، پیش روی مشتریان خود قرار میدهد. این امکان نیز فراهم است که برخی از مشتریان با غیرفعال کردن دو لینک x16 از حداکثر ۱۹۲ مسیر ارتباطی نسل چهارم PCIe بهرهبرداری کنند؛ اما براساس گزارش ServerTheHome، قطعهسازان اصلی در حال حاضر تنها از دو لینک x16 مابین سوکتها (۱۹۲ مسیر ارتباطی نسل چهارم PCIe) پشتیبانی میکنند؛ هر چند این حالت باعث ایجاد سرعتهای ارتباط داخلی برابر با پردازندههای نسل اول اپیک (سری ناپل - Naples) خواهد شد.
برای مقایسه خوب است بدانیم که نسل اول Infinity Fabric در پردازندههای EPYC Naples با سرعت ۱۰.۷GT/s کار میکند و برای برآورده کردن تقاضای پهنای باند، به ۴ لینک x16 Infinty Fabric نیاز است. از دیگر سو، در پردازندههای EPYC Rome هر لینک Infinity Fabric با سرعت ۲۵.۶GT/s کار میکند که دو برابر سرعت پردازندههای نسل اول اپیک است. به عبارت دیگر، برای برقراری ارتباط تراشه به تراشه تنها به دو لینک x16 Infinity Fabric احتیاج است و هرچه تعداد لینکهای Infinity Fabric افزایش یابد، میزان تأخیر و پهنای باند بهبود پیدا میکند. بااینحال بایستی در نظر داشت که پشتیبانی از PCIe 4 روی پردازندههای اپیک نیازمند پلتفرم جدیدی همراهبا طراحی به روز شدهی PCB است.
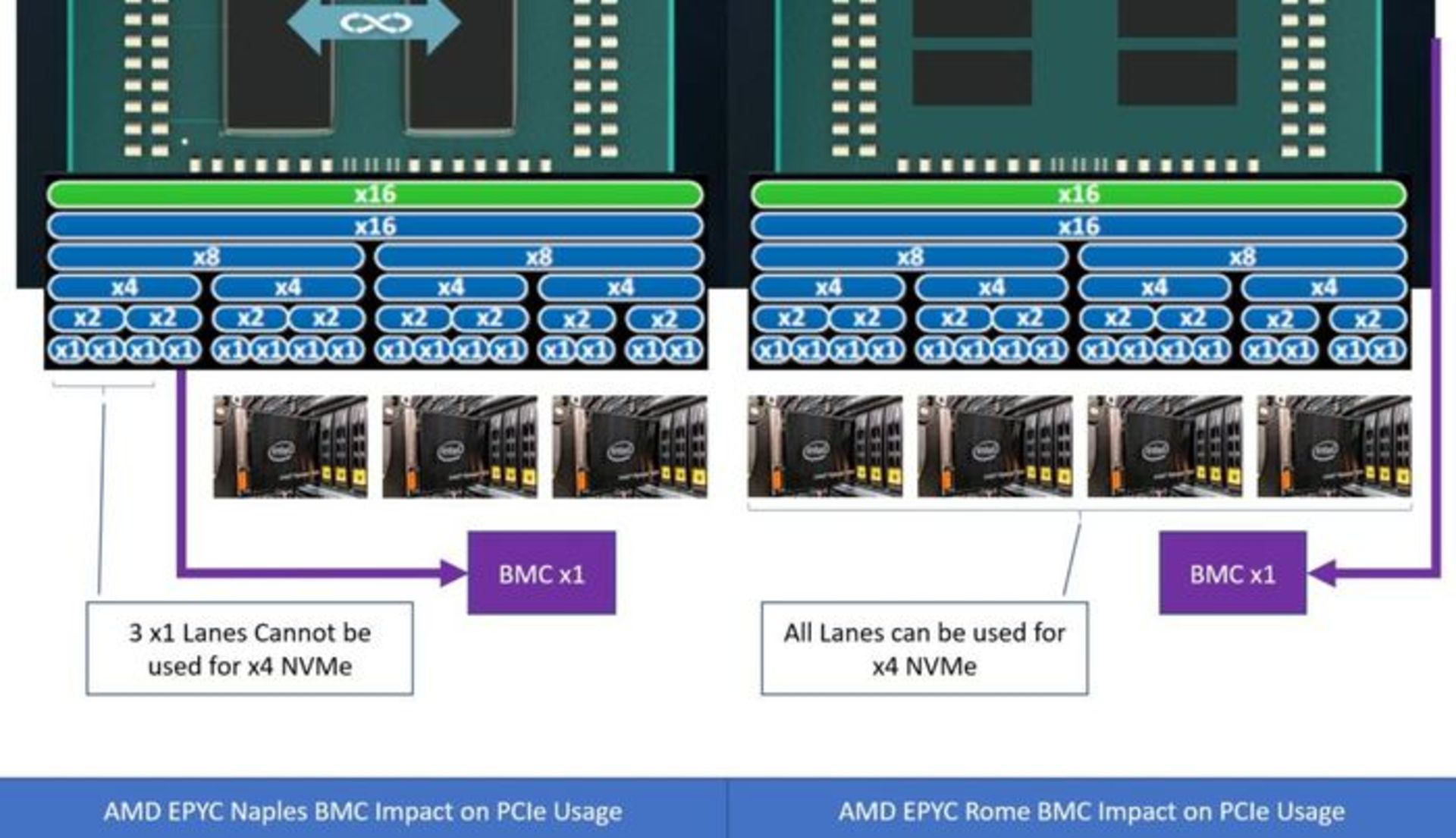
ویژگی اصلی دیگر پردازندههای جدید سرور رُم، قابلیت Integrated Server Controller Hub است که بهصورت Die مستقل ورودی/خروجی ۱۴ نانومتری بیان میشود. در پردازندههای نسل قبل، AMD مجبور بود که بسیاری از منابع را شامل مسیرهای ارتباطی PCIe با تکیه بر کنترلرهای کم سرعت شرکتهای ثالث به اشتراک بگذارد.

AMD قصد دارد یک مسیر ارتباطی اضافی بهازای هر پردازنده به درایو NVMe و سایر تجهیزات ورودی/خروجی فراهم کند؛ این تجهیزات لزوماً تجهیزاتی با سرعت اتصال بالا که ازطریق لینکهای اصلی x16 راهاندازی میشود، نیستند. این مسیر ارتباطی اضافی بخشی از لینکهای x16 مرکزی (Core) نخواهد بود، بلکه لینک مستقلی است که برای هر تراشه I/O در پردازندهی EPYC Rome تأمین میشود.
اگر اطلاعات موجود در این پژوهش درست باشد، شاید AMD به جایگاه برتری در صحنهی رقابت در پردازندههای سرور دست یابد. گزارشهایی در مورد کسب سهمی دورقمی از بازار قطعات سرور تا سال ۲۰۲۰ توسط این شرکت منتشر شده که تحقق آن محتمل است؛ مگر آنکه اینتل با ایجاد تغییرات چشمگیر در پردازندههای ۱۰ نانومتری Ice Lake-SP این روند را دگرگون سازد. در حال حاضر تلاشهای اینتل برای ارتقای پردازندههای سرور خود چنین شرایطی را هنوز ایجاد نکرده است.


هندزفری گردنی گزینهای مناسب برای افرادی است که میخواهند هم از مزایای هدفونهای سیمی و هم مزیتهای هدفونهای بیسیم بهرهمند شوند.

چری در نمایشگاه خودرو شانگهای خودرو تیگو ۹ را بهنمایش گذاشت و زومیت از نزدیک نگاهی به این شاسیبلند لوکس و بزرگ انداخته است.

تصاویر ضبطشده از شامپانزهها درحال خوردن میوهی تخمیرشده، پژوهشگران را به فکر واداشته است که آیا این رفتار میتواند منشأ آیینهای ضیافتی انسانی ...

وانپلاس سرانجام از گوشی پرچمدار 13T با تراشهی قدرتمند کوالکام و بدنهای بسیار باریک رونمایی کرد.

جیم سایمنز، پادشاه آنالیز کَمی، ریاضیدانی بود که با الگوریتم و داده موفقترین صندوق سرمایهگذاری آمریکا را راهاندازی و معمای بازار را حل کرد.

TCL از تلویزیونهای سری Fire TV خود با پنل QLED ۱۲۰ هرتزی و 4K در اندازههای مختلف رونمایی کرد.

فصل جدید همستر کامبت به نام HamsterVerse با بازیهای جذاب و وعدهی کسب درآمد رمزارزی و تونکوین از راه رسید.


