بررسی عمیق معماری Zen 2؛ پیشرفتها و ویژگیها (قسمت اول)

AMD بهدنبال رونمایی پردازندههای سری ۳۰۰۰ رایزن در رویداد کامپیوتکس ۲۰۱۹، جزئیات بیشتری از معماری استفادهشده در این تراشهها با نام Zen 2 و بهبودهای اعمالشده در آن ارائه داد. این معماری باعث توانمندی بیشتر پردازندههای جدید AMD در دو بخش پردازندههای خانگی و سازمانی میشود. Zen 2 شگفتیآفرینی ۲۰۱۹ تراشهساز آمریکایی معماریای نیست که بهیکباره و از صفر AMD صحنهگردانی کرده باشد. معماری جدید در واقع بلوغ اولین نسل از معماری Zen به شمار میرود. معماریهای تکامل یافته مهندسان را قادر به کنارگذاردن قسمتهای کمثمر معماری پایه و بازکردن گرههایی با ظرفیت ایجاد گلوگاه و تمرکز بر ترانزیستورهای باقیمانده برای افزایش هرچهبیشتر از سطح عملکرد میکند.
AMD در ساخت تراشههای Zen 2 از ساختار چندچیپلتی استفاده میکند. در شرایطی که ساخت تراشههای بزرگ با فرکانسهای بالا روی نودهای سیلیکون تولیدشده با فرایندهای ساخت فشردهتر با دشواری فزایندهای روبهرو است، سری جدید پردازندههای رایزن با بهکارگیری چیپلتهای مجزا، سطح عملکرد و مقیاسپذیری تراشههای رایزن را بهطور اساسی دگرگون کرده است. AMD قصد دارد الگوی بکارگیری چیپلتها را در تمام سبد محصولاتش از پردازندههای دسکتاپ سری ۳۰۰۰ تا پردازندههای سرور EPYC Rome گسترش دهد. هر یک از چیپلتهایی که AMD در این پردازندهها استفاده میکند، شامل ۸ هسته با معماری Zen 2 است.

برای آشنایی بهتر خوانندگان زومیت با آخرین پردازندههای AMD، گفتنی است سبد جدید محصولات AMD که در ساخت آنها از هستههایی با معماری Zen 2 استفاده میشود، شامل دو بخش مجزا است:
- پردازندههای مصارف عام (دسکتاپ) نسل سوم رایزن که با نام سری ۳۰۰۰ نیز شناسایی میشوند؛
- پردازندههای سرور نسل جدید EPYC که با نام Rome شناخته میشوند.
AMD جزئیات کاملی دربارهی ۶ پردازندهی سری ۳۰۰۰ شامل تعداد هستهها، سرعت کلاک، حجم حافظهی قابل پشتیبانی و توان مصرفی آنها ارائه کرده است. با وجود این، ویژگیهای پردازندههای سرور EPYC Rome بهجز برخی مقادیر حداکثری ارائه نشده و انتظار میرود در ماههای آینده جزئیات بیشتری از این تراشههای سازمانی منتشر شود. پردازندههای EPYC Rome با حداکثر ۶۴ هسته نسل دوم پردازندههای EPYC در نقشهی راه محصولات AMD است که اینبار با معماری Zen 2 تقویت شده است. نسل قبلی این محصولات با معماری Zen که از سال ۲۰۱۷ در بازارهای اینترپرایز حضور دارد، با عنوان EPYC Naples شناخته میشود و حداکثر ۳۲ هستهی پردازشی دارد. در جدول زیر، اطلاعات پردازندههای سری ۳۰۰۰ رایزن (مدلهای دسکتاپ) درج شده که بهطور رسمی AMD اعلام کرده است. پردازندههای معرفیشده ۶ تا ۱۶ هسته دارند و توان طراحی حرارتی آنها حداکثر ۱۰۵ وات است. قیمتها نیز از ۱۹۹ دلار برای پردازندهی ۶ هستهای Ryzen 5 3600 شروع میشود و تا ۷۴۹ دلار برای پردازندهی ۱۶ هستهای ادامه می یابد. تمامی پردازندههای زیر از چیدمان PCIe نسل چهارم ۴+۴+۱۶ و حافظههای DDR4 با فرکانس ۳۲۰۰ مگاهرتز پشتیبانی میکنند.
نام پردازنده | تعداد هسته/ ترد | فرکانس پایه (GHz) | فرکانس بوست (GHz) | کش L2-L3 (مگابایت) | توان طراحی حرارتی (وات) | قیمت (دلار) |
|---|---|---|---|---|---|---|
Ryzen 9 3950X | 16/32 | 3.5 | 4.7 | 8-64 | 105 | 749 |
Ryzen 9 3900X | 12/24 | 3.8 | 4.6 | 6-64 | 105 | 499 |
Ryzen 7 3800X | 8/16 | 3.9 | 4.5 | 4-32 | 105 | 399 |
Ryzen 7 3700X | 8/16 | 3.6 | 4.4 | 4-32 | 65 | 329 |
Ryzen 5 3600X | 6/12 | 3.8 | 4.4 | 3-32 | 95 | 249 |
Ryzen 5 3600 | 6/12 | 3.6 | 4.2 | 3-32 | 65 | 199 |
شیوهی طراحی Zen 2 در مقایسه با نسل اول Zen تغییر اساسی یافته است. در معماری جدید روش پیادهسازی هستهها در تراشه دگرگون شده و این بار هر ۸ هسته در یک چیپلت که با فناوری ساخت ۷ نانومتری TSMC تولید میشود، گنجانده شده است. برای مثال، پردازندهای با ۱۶ هسته دربرگیرندهی دو چیپلت محاسباتی است که هر یک ۸ هسته دارد. پردازندههای ۶ تا ۸ هستهای رایزن ۳۰۰۰، تنها یک چیپلت داشته و سایر مدلها دربردارندهی دو چیپلت است. سطح مقطع هر چیپلت ۷۴ تا ۸۰ میلیمتر مربع است. در هر چیپلت، هستهها بهصورت دو گروه ۴ تایی بازآرایی میشود که به هر یک از این گروهها یک کامپلکس هسته یا CCX اطلاق میشود. هر CCX علاوه بر داشتن ۴ هسته، دربرگیرنده حافظهی کش L3 نیز است. گفتنی است میزان کش L3 در معماری Zen 2 در مقایسه با Zen دوبرابر شده است. هر پردازنده علاوه بر چیپلتهای محاسباتی، دربرگیرندهی یک Die ورودی/خروجی (I/O) واحد بوده، ارتباط میان چیپلتها و این Die از طریق لینکهای Infinity Fabric (یا IF) برقرار میشود. Die ورودی خروجی بهعنوان گذرگاهی مرکزی برای برقراری تمامی ارتباطات میان تراشهی پردازنده و منابع سیستم عمل میکند. این Die میزبان تمامی مسیرهای ارتباطی PCIe و همچنین کانالهای حافظه و لینکهای Infinity Fabric برای ارتباط میان چیپلتها یا بین پردازندههای مجزا است. Die ورودی/خروجی در پردازندههای سرور EPYC Rome بر پایهی فناوری ساخت ۱۴ نانومتری Global Foundries تولید شده؛ اما در پردازندههای سری ۳۰۰۰ رایزن برای ساخت این Die از فناوری ساخت ۱۲ نانومتری این شرکت استفاده میشود. با وجود یک Die ورودی/خروجی، هر پردازندهی رایزن مبتنی بر Zen 2 به ۲۴ مسیر ارتباطی PCIe 4.0 (با چیدمان ۴+۴+۱۶) دو کانال حافظه دسترسی دارد.

در مقابل، پردازندههای EPYC Rome نیز با طراحی مشابه و چیپلتهای Zen 2 ساخته شده، حداکثر از ۸ چیپلت در ساختار خود برخوردار هستند که تعداد هستههای پردازنده را به ۶۴ هسته میرساند. در اینجا نیز، چیپلتهای محاسباتی امکان برقراری بیواسطهی ارتباط با یکدیگر را نداشته و هر چیپلت بهطور مستقیم تنها با Die ورودی/خروجی مرکزی در ارتباط است. Die ورودی/خروجی این بار به ۸ کانال حافظه دسترسی داشته و از ۱۲۸ مسیر ارتباطی PCIe 4 پشتیبانی میکند.

سطح عملکرد پردازندههای Zen 2
سطح عملکرد خام پردازندههای Zen 2 در مقایسه با Zen+ به میزان ۱۵ درصد بهبود یافته است
AMD در رویداد کامپیوتکس اعلام کرد تراشههای Zen 2 را طوری طراحی کرده است که در مقایسه با پلتفرم Zen + سطح عملکرد خام آن ۱۵ درصد بهبود یافته است. همزمان این شرکت مدعی است که در توان مصرفی یکسان، Zen 2 بهبود عملکردی بالاتر از ۲۵ درصد داشته و در بهترین شرایط با نیمی از توان مصرفی به سطح عملکرد یکسانی با Zen + دست مییابد. با ترکیب این موارد در بنچمارکهای گزینشی، AMD مدعی است سطح عملکرد پردازندههای مبتنی بر Zen 2 برحسب هر وات توان مصرفی، در مقایسه با نسل قبل ۷۵ درصد بهبود یافته و میزان این بهبود در مقایسه با پردازندههای رقیب ۴۵ درصد است.
این اعدادی است که شرکت سازنده ارائه کرده و هنوز نمیتوان بدون دسترسی به پردازندههای Zen 2 آنها را تأیید یا رد کرد. AMD زمان نسبتا زیادی را برای تقویت معماری Zen 2 و ایجاد تغییرات در آن صرف کرده تا نشان دهد که هر نسل از محصولات این شرکت روندی رو به رشد را در مقایسه با نسلهای قبلی محصولات میپیماید. AMD بنا بهگفتهی دست اندرکاراناش قصد دارد صرفنظر از رقابت خود با اینتل، در هر نسل پردازندههای رایزن تا جایی که میتواند، مرزهای فناوری را به پیش راند. AMD تصریح کرده است که آنها علاقهمند به ارائهی بهروزرسانیهای گسسته و پارهای و پیش افتادن و بازماندنهای مداوم از رقیب در جریان رقابت نیستند؛ چراکه این رویه ممکن است باعث کندشدن سرعت سیر فناوری شود. مدیران AMD گفتهاند که آنها زمان عرضهی محصولات Zen 2 او را طوری انتخاب کردهاند که با عرضهی محصولات رقابتی ۱۰ نانومتری Ice Lake اینتل تقارن زمانی داشته باشد. آنها میگویند که همچنان از نقشهی راه برنامهریزیشدهی خود جلوتر هستند.
AMD پردازندههای سری ۳۰۰۰ رایزن را در آزمایشگاههای خود با نرمافزار Cinebench آزموده است. Cinebench نرمافزار بنچمارک پردازنده برحسب محاسبات ممیز شناور است که AMD از گذشته تا به حال پردازندههای خود را برای کاوش میزان عملکرد FP (شامل FP32 و…) و سطح عملکرد حافظهی کش با آن آزمایش کرده است. با وجود این، Cinebench غالبا در جریان بنچمارک، درصد بالایی از زیرسیستم حافظه را دخالت نمیدهد.
در جریان رویداد CES 2019 در ژانویه، AMD بهطور زنده پردازندهی بینام ۸ هستهای Zen 2 را با نرمافزار Cinebench R15 آزمود و نتایج آن را با بنچمارک یک پردازندهی ۸ هستهای حرفهای Core i9-9900K اینتل مقایسه کرد. در حالی که نمرات بهدستآمدهی دو سیستم تقریبا مشابه یکدیگر بود، پردازندهی نسل سوم رایزن توانسته بود فقط با حدود یکسوم توان مصرفی پردازندهی اینتل در آن بنچمارک، موفق به کسب چنین نتیجهای شود. AMD در جریان کامپیوتکس ۲۰۱۹ در ماه مه، جزئیات زیادی از پردازندههای ۸ و ۱۲ هستهای نسل سومی خود و اطلاعاتی از نحوهی عملکرد آنها در بنچمارک Cinebench R20 را در دو بخش سینگل ترد (Single-Threading) و مالتی ترد (Multi-Thread) با مخاطبان خود در میان گذارد.
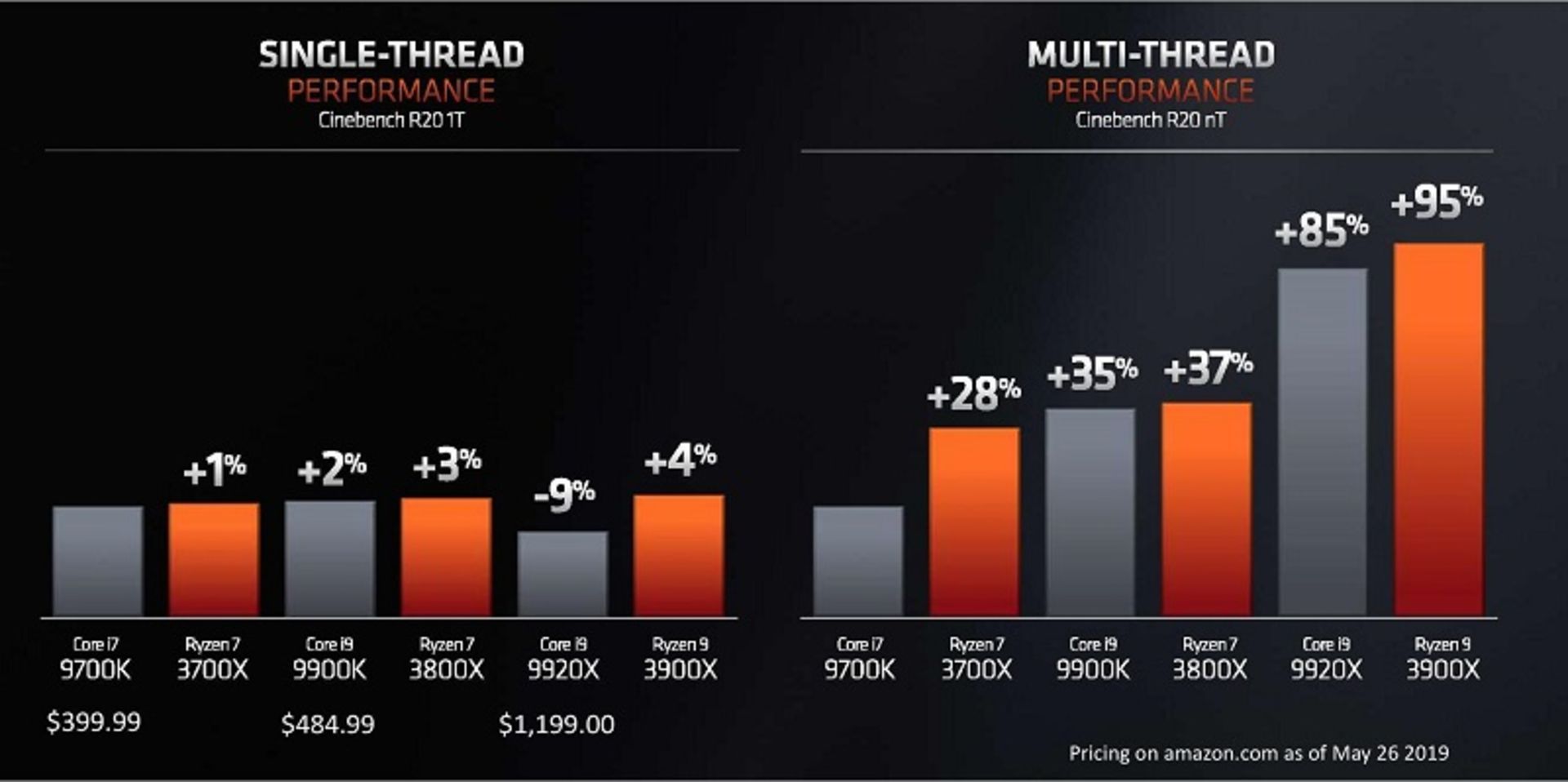
AMD با نشاندادن تصویری از نتایج این بنچمارک تصریح کرد که پردازندههای سری ۳۰۰۰ رایزن این شرکت با توان مصرفی کمتر و قیمت بسیار کمتر در مقایسه با پردازندههای اینتل، در هر دو بخش بنچمارک عملکرد بهتری داشتند. براساس نتایج این بنچمارک، پردازندهی ۴۹۹ دلاری Ryzen 9 3900X در بخش سینگل ترد در مقایسه با پردازندهی ۱۲۰۰ دلاری Core i9 9920X اینتل بسیار بهتر عمل کرده است. در این بخش، پردازنده ۳۹۹ دلاری Ryzen 9 3800X در مقایسه با Core i9-9900K با برچسب قیمت ۴۹۰ دلاری امتیاز بهتری کسب کرده است.
براساس نتایج آزمایشهای داخلی AMD، در بخش مالتی ترد Ryzen 9 3900X در مقایسه با مدل پردازندهی گرانقیمت Core i9 9920X حدود ۱۰ درصد سریعتر بوده و پردازندهی Ryzen 9 3800X باز هم در مقایسه با Core i9-9900K نتایج بهتری کسب کرده است.
AMD عملکرد پردازندههای خود را در بخش گیمینگ نیز آزموده و سطح عملکرد تراشههای Zen 2 را با نسل دوم پردازندههای رایزن مقایسه کرده است. براساس نتایج ارائهشدهی این تراشه ساز، پردازندهی Ryzen 7 3800X در مقایسه با پردازندهی نسل قبل Ryzen 7 2700X در عناوین مختلف گیم توانسته باعث بهبود ۱۱ تا ۳۴ درصدی نرخ فریم خروجی شود. این آزمایشها در رزولوشن 1080p انجام شده و از نظر شرکت سازنده آنچه باعث این پیشرفت شده، شامل افزایش IPC و افزایش فرکانس مؤثر پردازنده و افزایش دو برابری میزان حافظهی کش L3 است.
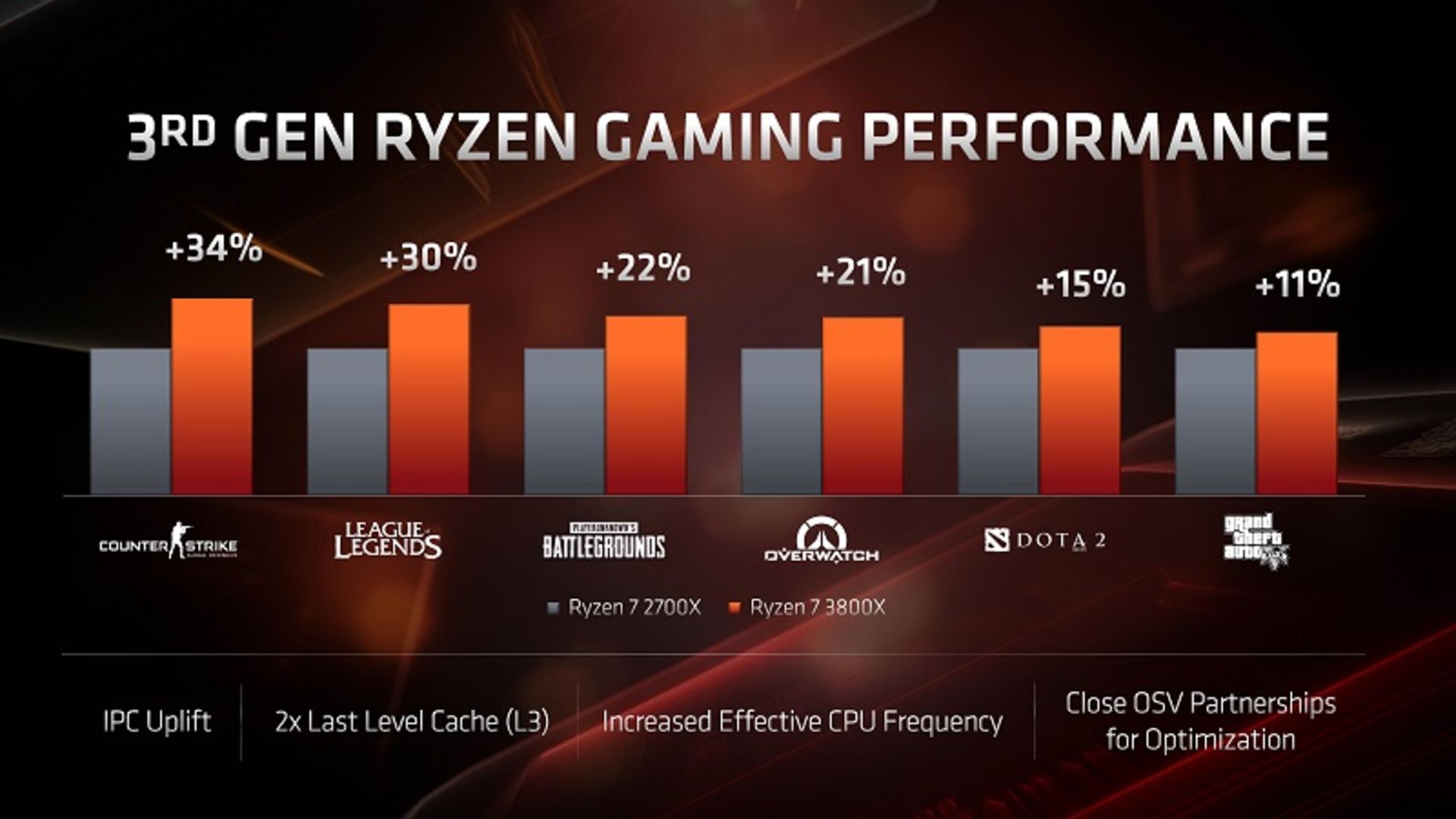
پردازندههای نسل سوم رایزن در مقایسه با نسل دوم، باعث بهبود خروجی ۱۱ تا ۳۴ درصدی در گیمینگ میشود
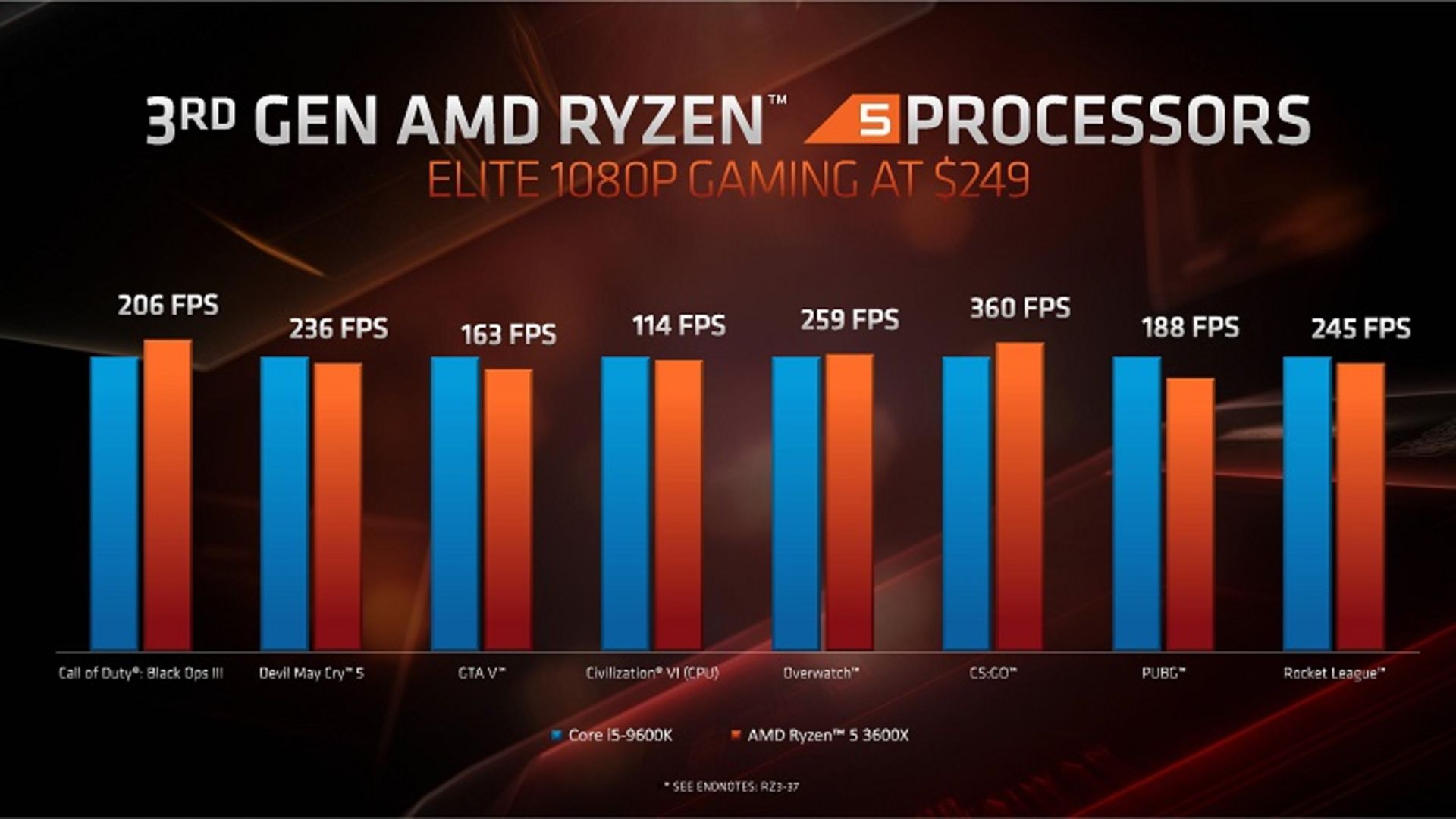
AMD عملکرد پردازندههای نسل سوم رایزن را در گیمینگ با پردازندههای اینتل نیز مقایسه کرده و این بار هم برای مقایسه از پردازندهی مشابه رقیب از نظر تعداد هستهها و ردهی قیمتی استفاده کرده است. در تصویر ارائهشدهی AMD دو پردازندهی Ryzen 5 3600X و Core i5-9600K در بازهی قیمتی ۲۵۰ دلاری با تعداد هستههای یکسان، در عناوین مختلف گیم به مصاف یکدیگر رفتهاند. پردازندهی نسل سوم رایزن در برخی عناوین بهتر از تراشهی رقیب عمل کرده و در تعدادی از عناوین مغلوب آن شده است.
یکی از نکات مهمی که در ساخت پردازندههای سری ۳۰۰۰ رایزن با معماری Zen 2 به چشم میخورد، افزایش سقف فرکانس در این پردازندهها در مقایسه با نسلهای پیشین است. مایکل کلارک طراح ارشد معماری رایزن در خلال ارائهی جزئیات معماری جدید شرکت AMD، تصریح کرد مهاجرت به فناوری ساخت ۷ نانومتری موفقیتآمیزتر از چیزی بود که در ابتدا پیشبینی میشد. AMD در تراشههای Zen 2 از یک سو حداکثر ولتاژ را در مقایسه با گذشته کاهش داده و از سوی دیگر امکان افزایش سرعت کلاک را فراهم کرده است. سقف فرکانس قابلدستیابی که در تراشههای ۱۲ نانومتری نسل دوم رایزن ۴۳۵۰ مگاهرتز بود، اکنون در نسل سوم این تراشهها به ۴۶۰۰ مگاهرتز رسیده است.

نکتهی مهم در اینجا این است که مهندسان AMD در گامهای اول توسعه انتظار افزایش سرعت کلاک پردازندههای ۷ نانومتری Zen 2 را در مقایسه با گذشته نداشتند. محدودیت در افزایش سرعت کلاک اشکالی ذاتی در فرایند فشردهسازی تراشههای مدرن است. با کوچکترشدن فناوری ساخت، سطوح ولتاژ موردنیاز کاهش یافته و کاهش ولتاژ میتواند تأثیر منفی بر فرکانس کاری مطلق پردازندهها بگذارد. با وجود این، در پردازندههای Zen 2 فناوری ساخت ۷ نانومتری TSMC در کنار مهندسی تحسینبرانگیز AMD باعث شده که تراشههای جدید امکان کار در فرکانس های بالاتری را در مقایسه با تراشه های رایزن ۱۲ و ۱۴ نانومتری داشته باشند. این یکی از قوتهای معماری Zen 2 است.
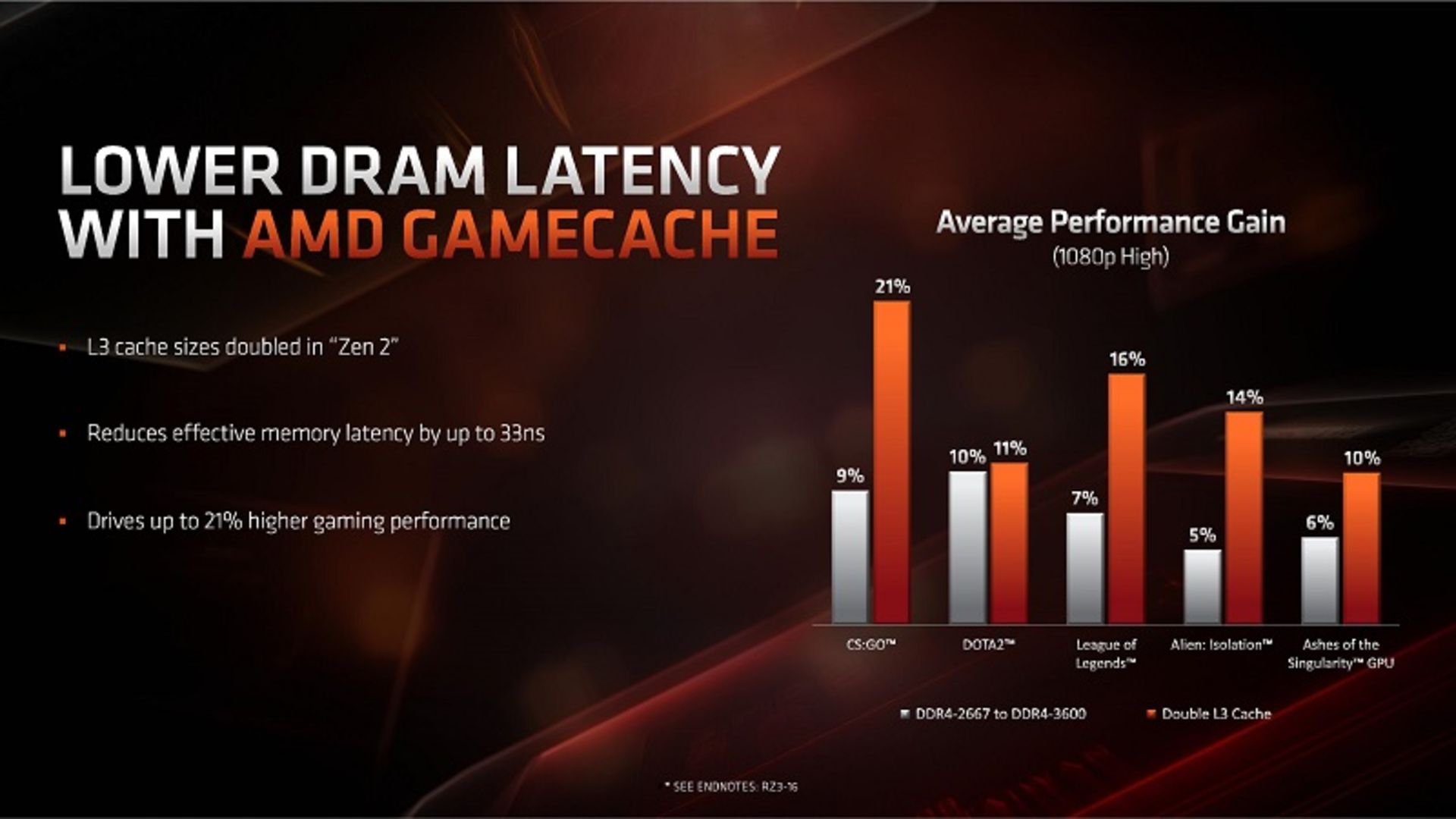
یکی از نکات مثبت دیگر در ساخت تراشههای Zen 2 دوبرابرشدن آخرین سطح حافظهی کش (کش L3) است. میزان این حافظه از ۲ مگابایت به ازای هر هسته اکنون به ۴ مگابایت به ازای هر هستهی پردازنده رسیده است. به گفتهی AMD، دوبرابرشدن میزان کش L3 باعث بهبود ۱۱ تا ۲۱ درصدی سطح عملکرد در گیمینگ 1080p با اتکا بر یک پردازندهی گرافیکی مجزا شده است. بهبود ساختار دستورالعملها در معماری Zen 2 نیز به بهبود این ارقام کمک شایانی کرده است.
بهینهسازیهای Zen 2 برای کار با ویندوز
یکی از نکات مهمی که باعث ایجاد اشکالاتی در پردازندههایی غیر از اینتل برای کار با ویندوز مایکروسافت میشود، چیدمان بهینهسازیها و زمانبند سیستمعامل است. در گذشته دیدیم که چگونه ویندوز مایکروسافت با جانمایی معماری پردازندههای غیر اینتل مانند معماری بولدوزر AMD، معماری هستههای هیبریدی کوالکام روی پردازندههای اسنپدراگون و اخیرا پردازندههای تردریپر AMD با چینش Multi-Die تطبیق نمییافت. در آخرین مورد، شاهد دامنههای تأخیر حافظهی مختلفی در روند اجرای محاسبات عادی بودیم.
AMD در روند توسعهی آخرین پردازندههای خود و با هدف شناسایی توپولوژی غیرعادی هستههای Zen 2 بهوسیلهی ویندوز، ارتباط نزدیکی با مایکروسافت برقرار کرد. این دو شرکت در کنار هم کار کردند تا مطمئن شوند فرایند تخصیص حافظه و ترد در نبود روش هدایت مناسب از طریق برنامهی در حال اجرا، به بالاترین بهرهوری در روند پردازش در ویندوز منجر شود. در نسخهی دهم مه ویندوز ۱۰، مایکروسافت برخی ویژگیهای اضافی را به ساختار سیستمعامل خود اضافه کرده تا معماری Zen 2 و جانمایی جدید تراشههای سیلیکون سری ۳۰۰۰ رایزن در این محیط به بهترین نحو عمل کند. بهینهسازیهای جدید در دو جبهه انجام پذیرفته است.
۱. گروهبندی ترد
اولین تغییر در روند تخصیص تردها اعمال شده است. وقتی پردازنده گروه هستههای مختلفی دارد، تردهای پردازشی را به روشهای گوناگونی میتوان به این هستهها تخصیص داد که هر کدام از این روشها معایب و مزایای خود را دارد. فرایند تخصیص ترد بستگی زیادی به گروهبندی ترد و پخش ترد دارد.
گروهبندی ترد حالتی است که در آن تردهای جدید تکثیر و از آنجا مستقیما به هستههایی تخصیص داده میشود که در مجاورت هستههای پرشده با تردهای در حال پردازش قرار دارد. با این شیوه، تردهای در حال پردازش در مجاورت یکدیگر قرار میگیرند و امکان ارتباط ترد به ترد بهخوبی ایجاد میشود. این شیوه باعث ایجاد محلهایی با تجمع توان بالا میشود؛ بهویژه اگر در پردازندهای با تعداد هستههای زیاد، تنها تعداد اندکی از هستهها در حال کار باشد.

پخش ترد حالت دیگری است که در آن هستههای در حال فعالیت تا هر اندازهی ممکن از یکدیگر دور باشند. در پردازندههای نسل سوم AMD پخش ترد بهمعنی تکثیر ترد اضافی در یک چیپلت جداگانه یا در یک CCX مجزا و تا حد امکان دور از تردهای مرتبط است. در چنین حالتی، امکان حفظ سطح عملکرد بالای پردازنده بدون ایجاد مناطق تجمع توان وجود دارد و معمولا بهترین حالت عملکرد توربو در پردازش تردهای چندگانه در این شرایط ایجاد میشود.
ریسک حالت پخش ترد این است که ممکن است برنامهای دو ترد را تکثیر کند و این تردها در دو سوی مختلف تراشه پردازش شود. در پردازندهی تردریپر، در چنین حالتی ممکن است ترد دوم در بخشی از CPU پردازش شود که در آن قسمت میزان تأخیر حافظه بالا است. این وضعیت باعث پیدایش نایکنواختی در سطح عملکرد بالقوه در اجرای دو ترد میشود، حتی اگر هستههایی که این تردها بدان تخصص یافته فرکانس بالاتری داشته باشند.
AMD برای بهبود عملکرد مالتیتردینگ، از روش پخش ترد صرفنظر کرده و به روش گروهبندی ترد روی آورده است
به دلیل آنکه نرمافزارها و بهویژه بازیهای ویدئویی مدرن بهجای تکیه بر فرایند پردازش سینگل تردینگ، به روش تکثیر و پردازش مالتیتردینگ روی آوردهاند و ایجاد ارتباط میان این رشتهها امری ضروری است، AMD در پردازندههای جدید خود از تکنیک پخش رشتهی هیبریدی صرفنظر کرده و به تکنیک گروهبندی رشته روی آورده است. این بدان معنا است که در روش همکاری جدید سیستمعامل و پردازندهی Zen 2، تا زمانی که یک CCX بهطور کامل از رشتههای پردازشی مرتبط با یکدیگر پر نشده، امکان دستیابی CCXهای دیگر به سایر رشتهها وجود ندارد. AMD بر این باور است که با وجود ظرفیت ایجاد تجمع توانی در یک چیپلت، در این حالت در حالی که چیپلتهای دیگر غیرفعال مانده، بدین روش سطح عملکرد کلی را میتوان بهبود بخشید. در پردازندههای Matisse در حالتی که تعداد رشتهها محدود بوده، بهویژه در حوزهی درخشان فناوری یعنی گیمینگ، با این روش میتوان به سطح عملکرد بهینهای دست یافت. دیدن میزان تأثیر این شگرد AMD بر سطح عملکرد پردازندههای پیش روی EPYC Rome یا پردازندههای آینده تردریپر خالی از لطف نخواهد بود. AMD برای تبیین میزان تأثیر روش گروهبندی رشتههای پردازشی، پردازندهی Zen 2 خود را در بازی rocket League در رزولوشن 1080p و با حداقل تنظیمات گرافیکی آزموده و ۱۵ درصد بهبود در نرخ فریم را گزارش کرده است.
۲. جهش کلاک (Clock Ramping)
AMD با بهبودهایی که در ساختار معماری Zen 2 ایجاد کرده، زمان موردنیاز برای جهش سرعت کلاک پردازندههای نوین خود را از حالت ایدهآل به حالت بارگذاری کامل بهشدت کاهش داده است. AMD در طراحی پردازندههای نسل سوم رایزن از گامهای افزایش فرکانس ظریفی به کوچکی ۲۵ مگاهرتز استفاده میکند که در مقایسه با گامهای ۱۰۰ مگاهرتزی اینتل، دقت و انعطاف بیشتری دارد. ارتقای فرکانس از کف به سقف آن در کوتاهترین زمان ممکن به پردازندههای AMD در روند پردازش بارهای کاری با تکثیر انفجاری (Burst Workloads) مانند WebXPRT کمک خواهد کرد. به گفتهی AMD، زمان ارتقای فرکانس پردازندههای این شرکت از ۳۰ میلی ثانیه در تراشههای Zen به ۱ تا ۲ میلی ثانیه در تراشههای Zen 2 رسیده است؛ اما برای پیادهسازی این ویژگی در نسل جدید پردازندههای این شرکت، بهروزرسانی بایوس مادربرد و ارتقای ویندوز ۱۰ به نسخه دهم مه ضروری است. بنابر آنچه گفته شد، زمان ارتقای فرکانس پردازندههای نسل سوم رایزن ۲۰ برابر کاهش یافته است. این رقم بسیار سریعتر از ارقامی است که اینتل در تلاش برای دسترسی به آن در پردازندههای خود است.

ابزار پیادهسازی این قابلیت در تراشههای جدید AMD CPPC2 یا Collaborative Power Performance Control 2 است. سنجشهای AMD حاکی از آن است که این ویژگی میتواند زمان بارگذاری بارهای کاری انفجاری و دیگر اپلیکیشنها را بهبود بخشد. AMD براساس آزمایشهایی که خود انجام داده تصریح کرده است که با این روش زمان بارگذاری و اجرای برنامهها ۶ درصد بهبود مییابد.
ساختار امنیتی پردازندههای Zen 2
جنبهی دیگر پیشرفتهای معماری ۲۰۱۹ تراشه ساز آمریکایی، افزایش سطح الزامات امنیتی پردازندههای مدرن این شرکت است. آن طور که گزارش شده است، تعداد درخورتوجهی از کدهای مخرب Side Channel بر آخرین پردازندههای AMD تأثیری نخواهند داشت. دلیل اصلی این مسئله نحوهی مدیریت بافرهای TLB است که همواره و پیش از آنکه برهمنهی این کدها مسئلهساز شود، نیازمند بررسیهای امنیتی اضافی است. گذشته از این، AMD پلتفرم امنیتی مبتنی بر سختافزاری را تدارک دیده که از پردازندههای Zen 2 در مقابل نقاط آسیبپذیری بالقوهی آنها محافظت میکند.

AMD با تکیه بر واحد سختافزاری اضافی با همکاری سیستمعامل یا منیجرهای حافظهی مجازی نظیر Hypervisorها سعی در غلبه و کنترل بدافزار Speculative Store Bypass معروف به Spectre v4 دارد. AMD انتظار هیچگونه تغییری در سطح عملکرد پردازندههای جدید خود را با این بهروزرسانیها ندارد. مسائل امنیتی جدیدی نظیر Foreshadow و Zombieload آخرین پردازندههای AMD را تحتتأثیر قرار نمیدهد.
پیشرفت Zen 2 از نظر IPC
آنچه AMD در معماری Zen 2 بر آن تأکید زیادی میکند، افزایش تعداد دستورالعملهای اجراپذیر در هر سیکل کلاک در مقایسه با نسلهای گذشته این معماری است. AMD میگوید رقم IPC در معماری جدید Zen 2 در مقایسه با نسل قبل Zen + حدود ۱۵ درصد افزایش یافته است. IPC که مخفف عبارت Instruction per Clock است، بهمعنی میانگین تعداد دستورالعملهای اجراپذیر در هستههای پردازنده در هر سیکل کلاک است. محاسبهی IPC در یک ماشین کار نسبتا پیچیدهای است. برای انجام این کار مجموعهای بخصوص از کدها برای اجرا به ماشین داده میشود و تعداد دستورالعملهای سطح ماشین برای تکمیل اجرای آن کدها محاسبه میشود. در گام بعد، با استفاده از زمانسنجهای سطح بالا تعداد سیکلهای کلاک موردنیاز برای کاملکردن آن تعداد دستورالعمل روی سختافزار واقعی اندازهگیری میشود. با تقسیم تعداد دستورالعملها بر تعداد سیکلهای کلاک اندازهگیریشده، رقم IPC ماشین مورد نظر محاسبه میشود. با ضرب IPC اندازهگیریشده در سرعت کلاک (بر حسب هرتز) و تعداد هستههای پردازنده، تعداد دستورالعمل اجراشدنی در هر ثانیه یا تعداد عملیاتهای ممیز شناوری محاسبه میشود که در هر ثانیه بهوسیلهی پردازندهی مدنظر اجراشدنی است. در نهایت، تعداد دستورالعملهای اجراشدنی بهوسیلهی پردازنده در هر ثانیه که با واحد گیگافلاپس یا میلیارد عمل اعشاری در ثانیه بیان میشود، معیاری از سطح عملکرد پردازندهی مدنظر است.
IPC در معماری Zen 2 در مقایسه با Zen + به میزان ۱۵ درصد افزایش یافته است
تعداد دستورالعملهای اجراپذیر در هر سیکل کلاک برای پردازنده عدد ثابتی نیست و بستگی به نحوهی تعامل و برهمکنش نرمافزار و برنامهی در حال اجرا با بخش سختافزاری سیستم دارد. با وجود این، طراحان تراشه سعی میکنند با تکیه بر روشهایی مانند استفاده از چندین واحد محاسبهگر منطقی (ALU) در هر هسته و پایپلاینهای دستورالعمل کوتاهتر، عدد IPC را در مقایسه با مقدار متوسط آن افزایش دهند.
مجموعه دستورالعملها (Instruction Set) نیز بر عدد IPC پردازنده تأثیرگذار است. هرچه مجموعه دستورالعملها سادهتر باشد، IPC پردازنده افزایش مییابد و هرچه با دستورالعملهای پیچیدهتری روبهرو باشیم، بالتبع IPC کاهش پیدا میکند. بنابراین، IPC پردازنده برای اجرای محاسبات ممیز شناور با دقت واحد (FP32) در مقایسه با اجرای محاسبات با دقت مضاعف (FP64) عدد بزرگتری است. آنچه میزان کارایی پردازنده را مشخص میکند، ترکیبی از IPC و سرعت کلاک و تعداد هستهها است. سازندگان پردازنده عموما عدد IPC را در مشخصات رسمی آن ذکر نمیکنند. AMD نیز دربارهی پردازندههای Zen 2 به ذکر افزایش ۱۵ درصدی IPC در مقایسه با معماری Zen بسنده کرده است.
نگاهی دقیقتر به معماری Zen 2
با نگاهی کلی به ساختار و تغییرات اعمالشده در ریزمعماری Zen 2، طرح و نقشهای دیده میشود که مشابهتهای زیادی با ساختار معماری بنیادین Zen دارد. Zen 2 عضوی از خانوادهی معماری Zen است و همان طور که گفته شد، معماریای نیست که از نو پیریزی شده باشد یا الگوی متفاوتی در پردازش x86 ارائه دهد. Zen 2 هستههایی پربازدهتر و گستردهتر دارد و توان عملیاتی را در اجرای دستورالعملها بهبود میبخشد. نمای کلی معماری هستههای Zen 2 در شکل زیر دیده میشود.

در اولین نگاه، هر هستهی Zen 2 بسیار شبیه به نسلهای قبلی به نظر میرسد. مهمترین تغییرات معماری Zen 2 و البته تأثیرگذارترین آنها عبارت است از:
- پیشبینیگر انشعاب جدید (Branch Predictor) با عنوان TAGE
- افزایش کش میکروعملیاتها (Micro-Ops) به دوبرابر
- دوبرابرشدن میزان کش L3
- افزایش منابع عدد صحیح (Integer) در هسته
- افزایش منابع ذخیره و بارگذاری (Load/Store)
- پشتیبانی از دستورالعملهای AVX-256 یا AVX2 بدون افت فرکانس
AMD برای بهبود IPC در معماری Zen 2 تأکید زیادی بر واحد جدید پیشبینیگر انشعاب هستهها میکند. پیشبینیگر مداری دیجیتالی است که میکوشد مسیر و مقصد پیشروی از طریق انشعاب خاص (مثل پذیرش ساختار شرطی در میان کدهای در حال اجرا) را پیش از آن حدس بزند که نتایج آن بهطور قطعی معلوم شود. هر انشعاب با ساختار شرطی (مثل If-then-else) پیادهسازی میشود. اگر ساختار شرطی اختیار نشود (Not Taken)، اجرای رشته عملیات فعلی ادامه خواهد یافت و اگر اختیار (Taken) شود، رشته دستورالعمل جدیدی متناسب با آن واکشی (Fetch) شده و به معرض اجرا گذارده میشود. با وجود این، پیشبینیگرها پردازنده امکان پیشبینی نتایج انشعاب، واکشی دستورالعمل بعدی زودتر از موعد از حافظه و اجرای آن را بی آنکه منتظر بازگشت نتایج انشعاب شود، خواهد داشت. چنانچه نتایج پیشبینی انشعاب درست باشد، جریان اجرای دستورالعملها در پایپلاین بهبود مییابد. در صورت پیشبینی نادرست بین ۱۰ تا ۲۰ سیکل کلاک برای واکشی، دیکود و اجرای دستورالعمل جدید تلف میشود. واحد پیشبینی انشعاب باید قادر به حدسزدن آدرس دستورالعمل بعدی در حافظه برای فراخوانی آن پیش از تکمیل اجرای دستورالعمل جاری باشد. پیشبینیگرها نقش اساسی در پردازندههای امروزی برای دستیابی به سطح عملکردی قابل قبول و افزایش IPC در در معماریهای پایپلاینی ایفا میکنند.
پیشبینیگر TAGE در هستهی Zen 2 حامل تاریخچهی انشعاب طولانیتری در مقایسه با نسخهی قبلی خود است که باعث پیشبینی دقیقتر و آمادهسازی دستورالعملها با بازدهی بیشتر و امکان خطای کمتر میشود. AMD در معماری جدید از بافرهای مقصد انشعاب (BTB) بزرگتری استفاده میکند. مقصد انشعاب عبارت است از نتیجهی نهایی اجرای دستورالعمل در صورت پذیرش یا عدم پذیرش ساختار شرطی. با افزایش بافرهای مقصد انشعاب امکان تعقیب رشتههای دستورالعمل و درخواستهای کش تسهیل میشود. اندازهی کش L1 BTB با ۵۱۲ ورودی (در مقایسه با ۲۵۶ ورودی سابق) دوبرابر میشود و کش L2 BTB نیز با 7K ورودی در مقایسه با گذشته ظرفیتی در حدود دو برابر دارد. کش L0 BTB همچنان ۱۶ ورودی را به خود اختصاص میدهد. هدف نهایی کاهش ۳۰ درصدی نرخ پیشبینیهای اشتباه در این چرخه و صرفهجویی در توان مصرفی پردازنده است.
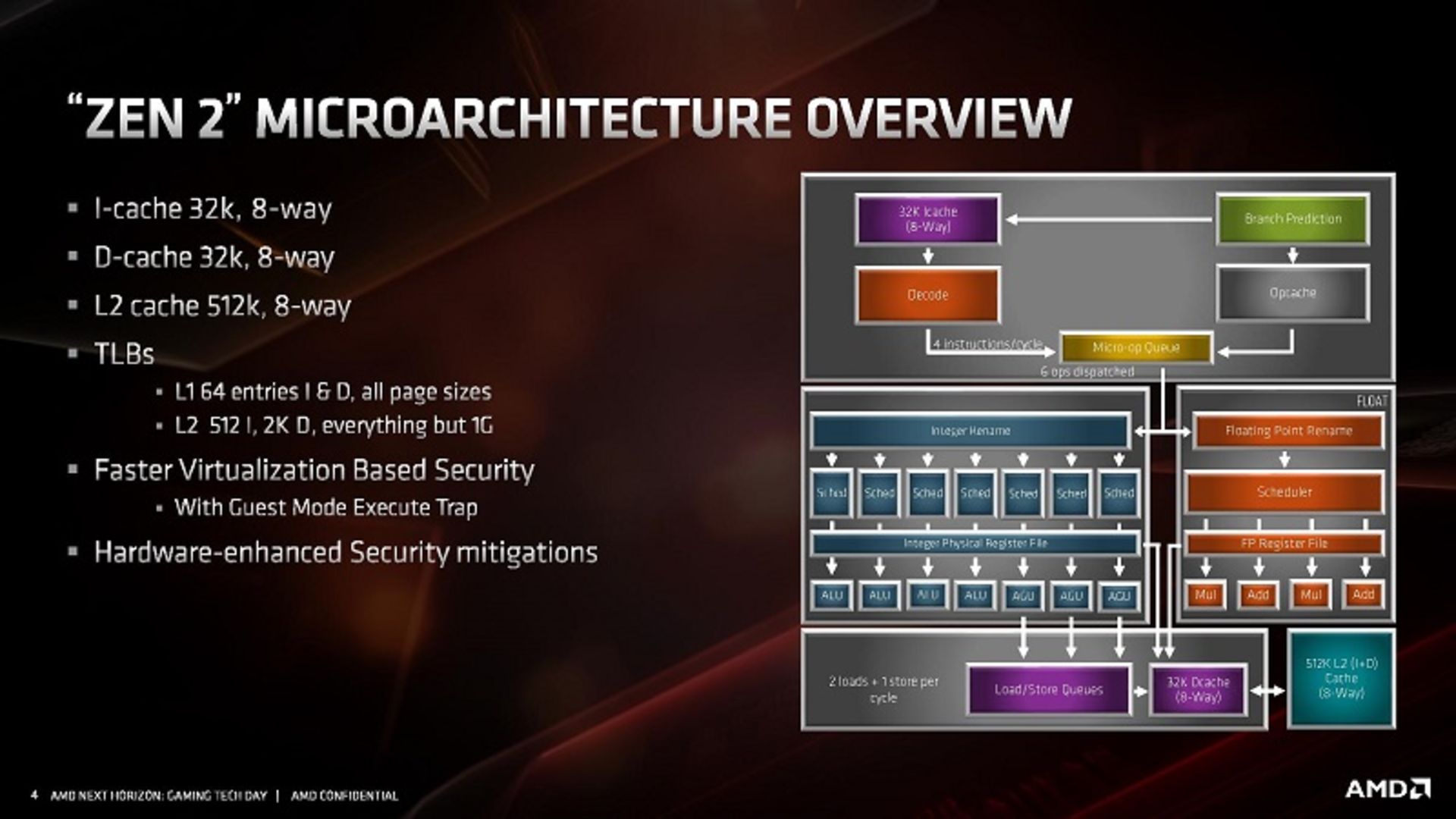
تغییر مهم دیگر در معماری کاهش کش دستورالعمل L1 به ۳۲KB و در عین حال دوبرابرکردن شرکتپذیری از ۴ مسیر (4Way) به ۸ مسیر (8Way) است. این تغییر مهم بهدنبال تحلیل اپلیکیشنهای متعدد و با بررسی حجم مجموعه دادههای (Dataset) متناظر اعمال شده است. بهگفتهی مایک کلارک، کاهش کش دستورالعمل تأثیر چندانی بر سطح عملکرد نمیگذارد و بیشتر مجموعهی دادهها بهجای یک کش دستورالعمل بزرگتر، به مسیرهای شرکتپذیری بیشتری نیاز دارند. کش جدید با شیوهی واکشی (Fetch) بهبود یافته و میزان بهکارگیری (Utilisation) بهتری ارائه شده است و البته روش جدید بازدهی توانی بهتری نیز دارد. یکی از مزایای کاهش کش دستورالعمل، امکان دوبرابرکردن کش Micro-Op است. این دو ساختار نزدیک به یکدیگر درون هسته قرار دارند و با توجه به محدودیتهای فضا در معماری ۷ نانومتری، دادوستدهای مهندسی در بزرگی و کوچکی این ساختارها مستدل است. AMD میگوید کش L1 کوچکتر با وجود کش Micro-Op بزرگتر باعث بهبود کارایی پردازنده در بیشتر سناریوهای آزمایشی شده است. دوبرابرشدن کش Micro-Op و ترکیب آن با افزایش منابع ذخیرهسازی و بارگذاری، باعث افزایش ظرفیت فراخوانی و اجرای دستورالعملها شده است. موارد ذکرشده همراه با دوبرابرشدن کش L3، پشتیبانی از میکروعملیاتهای AVX2 و واحد پیشبینیگر انشعاب بهبودیافته، در مجموع باعث بهبود ۱۵ درصدی IPC در معماری Zen 2 شده است.
نظرات