بررسی عمیق معماری Zen 2، پیشرفتها و ویژگیهای آن (قسمت دوم)

در قسمت قبلی این مقاله، در مورد معماری Zen 2 و ساختار پردازندههای جدید AMD، سطوح عملکرد این پردازندهها در آزمونهای داخلی AMD، شیوههای بهینهسازی معماری برای کار با ویندوز مایکروسافت، IPC پردازندههای Zen 2، نمای کلی معماری جدید AMD، مرحلهی واکشی دستورالعمل و تأثیر واحد پیشبینیگر انشعاب جدید بر تسریع و بهبود اجرای دستورالعملها در پایپ لاین توضیحاتی دادیم. گفته شد که کاهش کش دستورالعمل از ۶۴ کیلوبایت به ۳۲ کیلوبایت و در عین حال افزایش مسیرهای شرکت پذیری از ۴ به ۸ مسیر، تأثیر مطلوبی بر جریان پردازش دادههای مختلف دارد. از سوی دیگر به این موضوع اشاره شد که مهندسان AMD در یک دادوستد مهندسی، با کوچکتر شدن فضای کش دستورالعمل، فضای کش Micro-Op را به دو برابر افزایش دادهاند و نتایج آن را در عمل آزمودهاند. در ادامه این مقاله در مورد Micro-Op یا میکروعملیاتها و روند دیکود (Decode) دستورالعمل بیشتر صحبت خواهیم کرد.
میکروعملیاتها و دیکود دستورالعمل
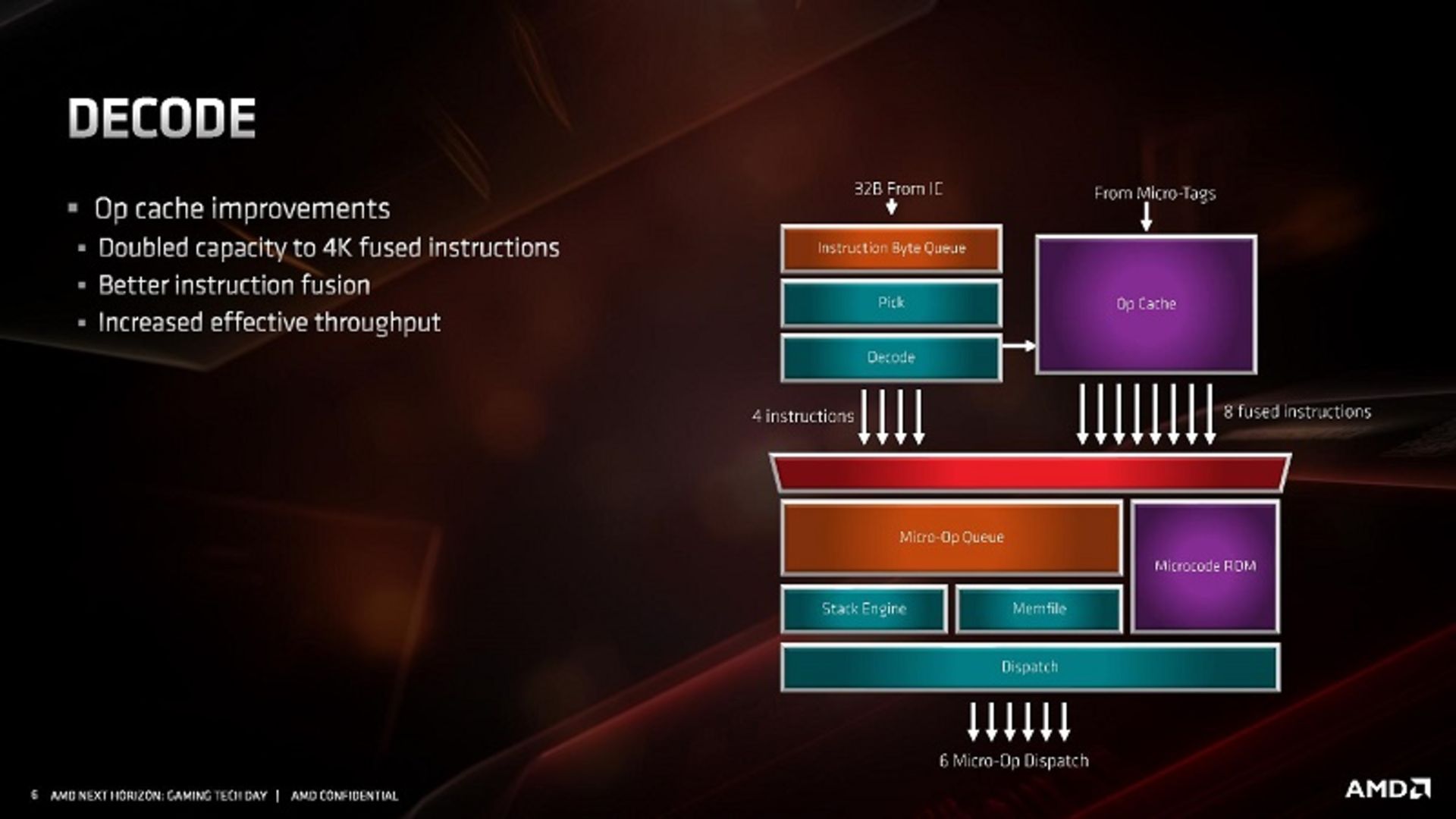
میکروعملیات یا Micro-Op (در این مقاله هر دو واژه به یک معنی -Micro Operation- به کار رفته است) در پردازندههای کامپیوتری، بهمعنی دستورالعملهای سطح پایینی است که در ترکیب با یکدیگر دستورالعملهای پیچیدهی ماشین را تولید و پیادهسازی میکنند. از این رو، گاه به آنها میکرودستورالعمل نیز اطلاق میشود. میکروعملیات عموماً شامل عملیاتهای مبنایی نظیر انتقال داده بین رجیسترها یا بین رجیسترها و باسهای CPU و اعمال محاسباتی و منطقی ساده روی رجیسترها است. در یک پردازنده، سیکل واکشی، دیکود و اجرای دستورالعملها بهطور مرتب پیادهسازی میشود و طی آن دستورالعملهای پیچیده یا ماکرو، در خلال اجرا به بخشهای کوچکتری دیکود یا تجزیه میشود و سپس پردازنده کار پردازش را از طریق رشتههایی از این میکروعملیاتها به پیش میبرد.
اجرای میکروعملیاتها تحت نظارت واحد کنترل CPU انجام میپذیرد. پردازنده با اعمال برخی بهینهسازیها نظیر بازآرایی (Reorder)، ترکیب (Fusion) و کش کردن میکروعملیاتها، در مورد روند اجرای آنها تصمیمگیری میکند. در مرحلهی دیکود، مهمترین عامل کش Micro-Op است. AMD با دوبرابر کردن اندازهی این کش از 2K به 4K ورودی (Entry) دستورالعملهای دیکودشدهی بیشتری را نسبت به گذشته در آن نگهداری میکند. در این حالت میزان بهکارگیری مجدد ورودیها افزایش مییابد. AMD برای تسهیل این بهکارگیری، نرخ گسیل (Dispatch) از کش Micro-Op به بافرها را به ۸ دستورالعمل ترکیبشده (Fused) افزایش داده است. با فرض اینکه AMD بتواند در اغلب موارد دیکودرها را دور بزند و نیازی به تجزیه دستورالعمل نباشد، کش Micro-Op تبدیل به بلوک موثری از تراشهی سیلیکون میشود.
در مقایسه پردازندههای Zen 2 با پردازندههای رقیب، افزایش اندازهی کش میکروعملیات به 4K جذابتر نیز میشود. اینتل در خانوادهی Skylake از کش Micro-Op با ظرفیت 1.5K ورودی استفاده میکند. این شرکت در پردازندههای ۱۰ نانومتری Ice Lake میزان کش میکروعملیات را به 2.25K ورودی ارتقا داده است؛ اما این تراشه در ادامهی سال جاری به کامپیوترهای قابل حمل راه یافته و پس از آن ممکن است به بازار سرور نیز راه پیدا کند. AMD با معماری هستهی Zen 2 از هماکنون شکاف وسیع میان بازار پردازندههای مصارف عام و سازمانی را پر کرده است. در حال حاضر ظرفیت کش Micro-Op پردازندهی ARM A77 معادل 1.5K ورودی است و این اولین باری است که ARM در طراحی پردازندههای موبایل خود از این نوع کش استفاده میکند.
ظرفیت کش Micro-Op در معماری Zen 2 از مقدار متناظر در پردازندههای اینتل بسیار بیشتر است
دیکودرها در معماری Zen 2 تغییری نکرده و همچنان ۴ دیکودر کامپلکس در دسترس است که در مقایسه با ۱ دیکودر کامپلکس و ۴ دیکودر سادهی اینتل، منابع درخور توجهی را تشکیل میدهد. دستورالعملهای دیکود شده در کش Micro-Op ذخیره شده و بهدنبال آن توسط Dispatch به صف Micro-Op گسیل میشوند.
AMD تصریح کرده است که الگوریتم ترکیب میکروعملیاتهای خود را در معماری جدید بهبود بخشیده؛ هرچند جزئیاتی در مورد میزان تأثیر آن بر سطح عملکرد بیان کرده است. معماری Zen 2 برخلاف Zen و Zen+ با پشتیبانی از AVX2 نیاز به شکستن یک دستورالعمل AVX2 به دو Micro-Op ندارد. به عبارت دیگر دستورالعملهای AVX2 در سراسر پایپلاین به فرم Micro-Op واحد شناسایی میشود.
با عبور از دیکودرها، صفهای Micro-Op و Dispatch در معماری جدید قادر است در هر سیکل کلاک زمانبندهای (Schedulers) صحیح و اعشاری را با شش Micro-Op تغذیه کند. البته با توجه به اینکه AMD در معماری Zen از زمانبندهای عدد صحیح (Integer) و اعشاری (Floating Point) مستقلی استفاده میکند، توازن کمی به هم میخورد؛ چرا که زمانبند عدد صحیح میتواند ۶ میکروعملیات را در هر سیکل کلاک بپذیرد، در حالیکه زمانبند عدد اعشاری تنها میتواند ۴ میکروعملیات را بپذیرد. واحد Dispatch قادر است بهطور همزمان میکروعملیاتها را به هر دو بخش گسیل کند.
بخش محاسبات اعشاری
پیشرفت کلیدی معماری Zen 2 در بخش محاسبات اعشاری پشتیبانی کامل از دستورالعملهای AVX2 است. AMD پهنای باند واحدهای اجرایی این بخش را از ۱۲۸ به ۲۵۶ بیت افزایش داده و امکان اجرای محاسبات AVX2 را در یک سیکل کلاک فراهم کرده است. تا پیش از این چنین محاسباتی به دو دستورالعمل مجزا تجزیه میشد و هر دستورالعمل در یک سیکل کلاک اجرا میشد. بهرهمندی از واحدهای ذخیره و بارگذاری ۲۵۶ بیتی این روند را بهبود بخشیده است؛ بهطوریکه واحدهای FMA بهطور پیوسته در معماری جدید تغذیه میشود.

AMD میگوید با توجه به زمانبندی توأم با پایش انرژی در معماری جدید، افت فرکانس از پیش تعریفشدهای هنگام استفاده از دستورالعملهای AVX2 در پردازندههای جدید وجود ندارد. البته امکان کاهش فرکانس بسته به دما و الزامات ولتاژ وجود دارد؛ اما ایجاد این شرایط بهصورت خودکار و مستقل از دستورالعملهای در حال اجرا است.
پیشرفت کلیدی معماری Zen 2 در بخش محاسبات اعشاری پشتیبانی کامل از دستورالعملهای AVX2 است
در واحد محاسبات اعشاری، صفها تا ۴ میکروعملیات را در هر سیکل کلاک از واحد Dispatch میپذیرند. این میکروعملیاتها واحد رجیستر فیزیکی را با ظرفیت ۱۶۰ ورودی تغذیه میکنند. پس از آن دستورالعملهای میکرو به سوی ۴ واحد اجرایی روانه میشوند که میتوان آنها را طی فرایند ذخیره و بارگذاری با ۲۵۶ بیت داده تغذیه کرد.
بهبودهای دیگری در واحدهای FMA گذشته از دو برابر شدن ظرفیت آنها لحاظ شده است. AMD میگوید این واحدها با تخصیص حافظهی بهتر، سطح عملکرد خالص را در محاسبات فیزیکی تکرارشونده و برخی تکنیکهای پردازش صوتی بهبود بخشیدهاند. بهبود دیگر صورتگرفته در این بخش، کاهش تأخیر ضرب اعشاری از ۴ به ۳ سیکل کلاک است که پیشرفتی در خور توجه به شمار میرود.
بخش محاسبات صحیح، ذخیره و بارگذاری
زمانبندهای واحد عدد صحیح میتواند تا شش Micro-Op را در هر سیکل کلاک قبول کند. این دستورالعملها ۲۲۴ ورودی بافر بازآرایی (Reorder Buffer) را تغذیه میکنند. واحد عدد صحیح از نظر فنی ۷ واحد اجرایی دارد که شامل ۴ محاسبه گر منطقی (ALU) و ۳ واحد تولید آدرس (AGU) است. زمانبندها متشکل از ۴ صف ALU با ۱۶ ورودی و یک صف AGU با ۲۸ ورودی است. با وجود این، واحد AGU قادر به تغذیهی فایل رجیستر با سه Micro-Op در هر سیکل کلاک است. AMD براساس شبیهسازی توزیع دستورالعمل در یک نرمافزار عادی، ظرفیت صف AGU را در معماری جدید افزایش داده است. این صفها فایل رجیستر چند منظوره با ظرفیت ۱۸۰ ورودی را تغذیه میکنند؛ اما عملیاتهای خاص ALU را نیز تعقیب میکنند تا از اجرای عملیاتهایی با ظرفیت ایجاد وقفه ممانعت کنند.
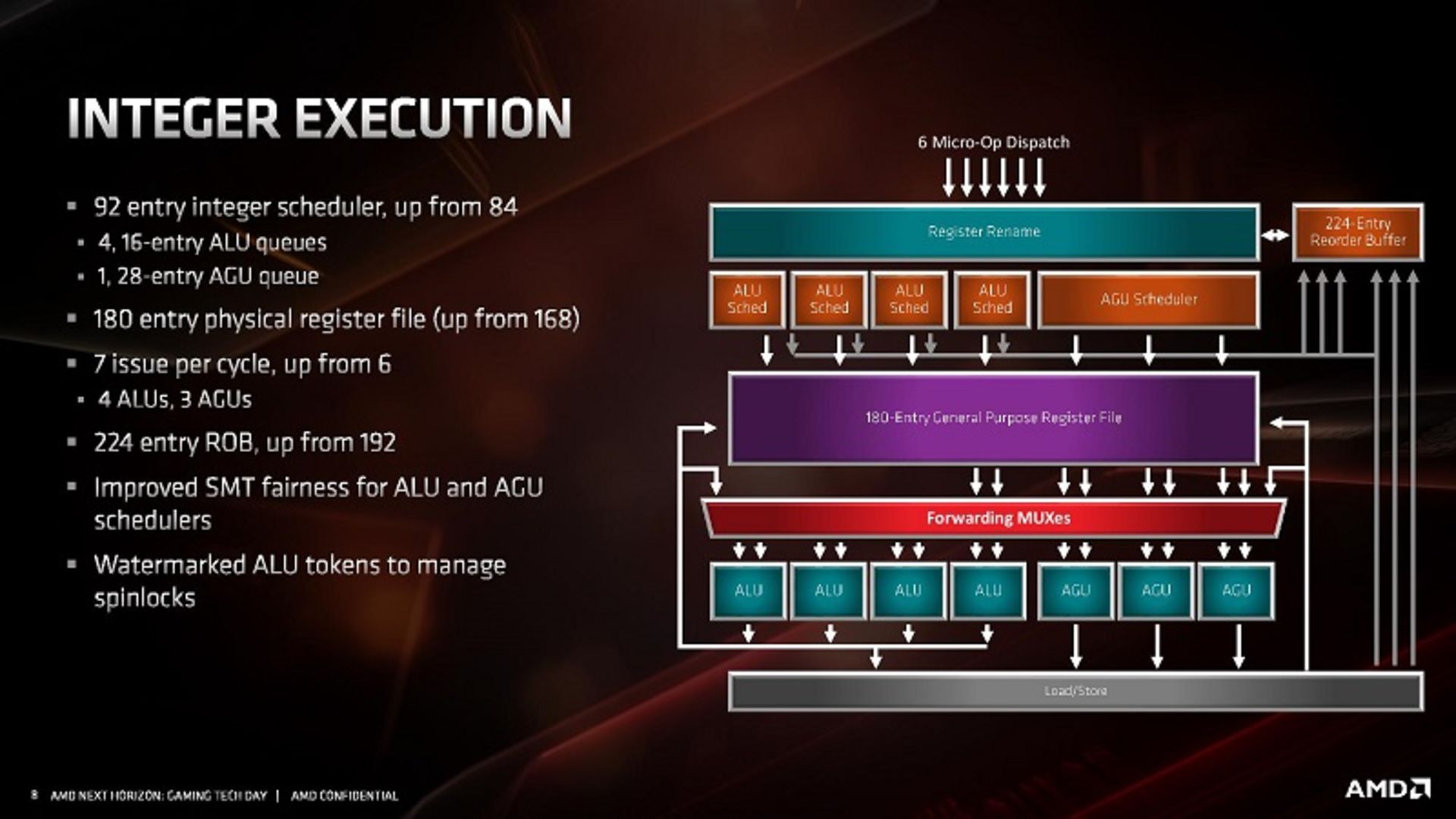
سه AGU واحد ذخیره و بارگذاری را تغذیه میکنند. این واحد میتواند در هر سیکل از ۲ بار خواندن ۲۵۶ بیتی و ۱ بار نوشتن ۲۵۶ بیتی پشتیبانی کند. ۳ واحد AGU براساس دیاگرام ارائهشده توسط AMD معادل یکدیگر نیستند. AGU2 تنها میتواند واحد ذخیره را تغذیه کند؛ درحالیکه AGU0 و AGU1 قادر به تغذیهی هر دو واحد ذخیره و بارگذاری هستند. ظرفیت صف واحد ذخیره از ۴۴ ورودی به ۴۸ ورودی ارتقا یافته و TLBها برای کش کردن داده نیز افزایش یافته است. پهنای باند واحد ذخیره و بارگذاری جنبهی بارز معماری Zen 2 است که اکنون از ۱۶ به ۳۲ بایت ارتقا یافته است.
حافظهی کش در معماری جدید
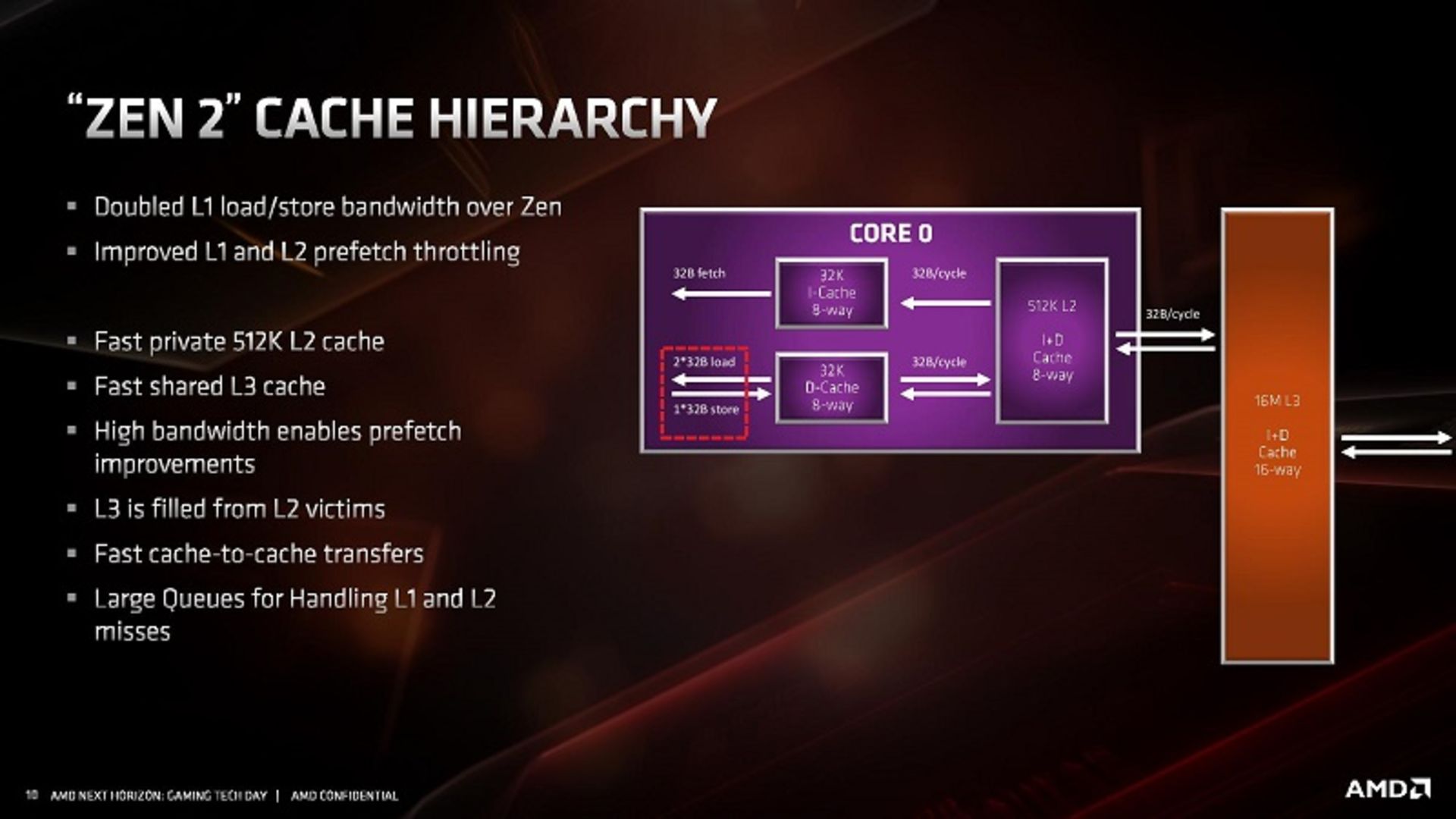
همانطور که پیش از این گفته شد، تغییر بزرگ در بخش کش معماری Zen 2 کاهش اندازهی کش دستورالعمل از ۶۴ به ۳۲ کیلوبایت و افزایش مسیرهای شرکت پذیری از ۴ به ۸ مسیر است. چنین تغییری AMD را قادر به حفظ فضا و افزایش ظرفیت کش Micro-Op از 2K ورودی به 4K ورودی کرده است. AMD بر این باور است که چنین تغییری باعث توازن عملکرد بهتر در کار با بارهای کاری امروزی میشود.
تغییرات عمده در بخش حافظهی کش دوبرابرشدن کش L3، نصف شدن ظرفیت کش دستورالعمل و دوبرابرشدن کش Micro-Op است
در معماری Zen 2 کش L1-D همچنان ۳۲ کیلوبایت و ۸ مسیره است و L2 نیز کشی با ۵۱۲ کیلو بایت ظرفیت و ۸ مسیر است. اندازهی کش L3 که یک کش غیرفراگیر (Non-Inclusive) است، دو برابر شده و برای هر کامپلکس هسته (CCX) از ۸ به ۱۶ مگابایت افزایش یافته است. AMD کش L3 را با بهاشتراکگذاری یک بلوک ۱۶ مگابایتی میان هستههای هر CCX، بهجای ایجاد دسترسی به L3 از هر یک از هستهها مدیریت میکند. به دلیل افزایش ظرفیت کش L3 تأخیر اندکی افزایش یافته است. تأخیر حافظهی کش L1 همچنان ۴ کلاک، تأخیر L2 معادل ۱۲ کلاک و تأخیر L3 اکنون بالغ بر ۳۵ تا ۴۰ سیکل کلاک است. گفتنی است که افزایش تأخیر یک خصوصیت ذاتی حجم کشهای بزرگتر بوده و این برای AMD به منزلهی یک دادوستد مهندسی است.
AMD تصریح کرده که در معماری جدید خود اندازهی صفها را برای مدیریت خطاهای L1 و L2 افزایش داده؛ هر چند این شرکت توضیحی در مورد اندازهی دقیق این صفها نداده است.
Infinity fabric
با حرکت به سوی نسل دوم معماری Zen، با نسخهی جدیدی از Infinity Fabric که در واقع نسل دوم آن به شمار میرود، روبهرو میشویم. یکی از مهمترین پیشرفتهای IF2 پشتیبانی از نسل چهارم پروتکل ارتباطی PCIe است و بدینترتیب پهنای باس IF جدید از ۲۵۶ به ۵۱۲ بیت افزایش مییابد.

بنا بر گفتههای AMD، بهرهوری توانی کلی IF2 به میزان ۲۷ درصد بهبود یافته و در مجموع باعث کاهش توان مصرفی به ازای هر بیت نقل و انتقال داده شده است. با افزایش لینکهای IF در پردازندههای EPYC با معماری Zen 2 و حرکت داده از چیپلتهای متعدد به Die ورودی/خروجی این مسئله اهمیت بیشتری نیز مییابد.
یکی از ویژگیهای IF2 این است که کلاک آن از کلاک DRAM مجزا شده است. در معماریهای نسل قبل Zen فرکانس IF همبسته با فرکانس DRAM بود که البته مزایایی دربرداشت و امکان کار حافظه با فرکانسهای بسیار بالاتر وجود داشت؛ اما هرگونه محدودیت در IF بهمعنی آن بود که هر دو المان با ماهیت Lock-Step کلاک، دچار محدودیتهایی میشد.
AMD در نسل جدید معماری پردازندههای خود، نسبتهایی را برای IF2 تعریف کرده است. چنانچه نسبت ۱:۱ اعمال شود، کلاک IF2 نرمال بوده و تا سقف کلاک DRAM افزایش مییابد و چنانچه نسبت ۱:۲ اعمال شود، کلاک IF2 به نصف DRAM تقلیل مییابد. نسبت نرمال بایستی بهطور خودکار در فرکانسهای حول DDR4-3600 تا DDR4-3800 (فرکانس پیشنهادی AMD) فعال شود و در این حالت کلاک IF2 منطبق بر کلاک DRAM میشود. در غیر اینصورت با کاهش کلاک IF2 به نصف، تأثیر مستقیم آن بر پهنای باند Infinity Fabric درخورتوجه خواهد بود. بایستی توجه داشت که در حالت دوم، حتی اگر فرکانس DRAM بالا باشد، با کاهش فرکانس IF بهرهی عملکرد خام ناشی از وجود حافظههای سریعتر محدود میشود. AMD توضیح میدهد چنانچه با نصب حافظههای DDR4-3600 نسبت ۱:۱ تحصیل شود، روش بهتری در مقایسه با بهینهسازی تایمینگها در یک فرکانس مشخص است.
جمعبندی
ساختن هستهای با معماری Zen 2 چیزی بیشتر از طراحی و ساختن هستهی پردازنده بهتنهایی است. فعل و انفعالات میان هستهها و چیپلتها، طراحی و هماهنگی SoC و پلتفرم نیاز به کار اجزای متعدد داخلی در کنار یکدیگر دارد تا سطحی از تشریک مساعی و همافزایی خلق شود که بهطور جداگانه امکان دستیابی هر یک از اجزا به آن نخواهد بود. آنچه AMD با طراحی چیپلتی و معماری Zen 2 انجام داده، نهتنها در بهرهگیری از مزایای نود سیلیکون فشردهتر نویدبخش ظاهر میشود، بلکه راهی به سوی دگرگونی آیندهی محاسبات میگشاید. با کاهش ابعاد تراشه و فشرده شدن فرایند ساخت، مهمترین خروجی کار کاهش توان مصرفی است. این مهم به دو طریق قابل انجام است: ۱. سطح عملکرد متعارف با توان کمتری حفظ شود ۲. با افزایش سطوح توان، سطوح عملکرد بالاتری به بار آید. در طول زمان نیز شاهد چنین رویهای در طراحی هستههای جدیدتر بودهایم. مهندسان طراح یا راههای افزایش توان تراشههای خود را هموار میکنند تا به سطوح عملکرد بالاتری دست یابند یا با افزودن قسمتهای جدیدی به هسته در تلاش برای افزایش نرخ اجرای دستورالعملها هستند. پیادهسازی رویهی اخیر ساده نیست و نیازمند دادوستدهای فراوان مهندسی است. مثالی از این قاعده در طراحی و معماری هستههای Zen 2 دیده میشود. آن هم دادوستدی است که AMD در بخش کش پردازنده به اجرا درآورده است. AMD کش دستورالعمل L1 را کاهش داده و با این کار امکان افزایش دو برابری کش Micro-Op را یافته است. بدین ترتیب تراشهساز آمریکایی انتظار افزایش سطح عملکرد و بهبود توان مصرفی را بهصورت توامان دارد.
از مجموع آنچه در این مقاله گفته شد، برمیآید که Zen 2 بهعنوان عضوی از خانوادهی معماری Zen، شباهت زیادی با نسلهای قبلی خود دارد. با این حال AMD گفته است Zen 2 در مقایسه با Zen+ به میزان ۱۵ درصد سطح عملکرد بهتری دارد. با تغییرات اعمالشده در هستههای Zen 2 چنین کاری قطعاً شدنی است. کاربرانی که بر سطح عملکرد پردازنده تمرکز زیادی دارند، قطعاً مجذوب عملکرد پردازندههای Zen 2، بهویژه پرچمدار این سری پردازندهی ۱۶ هستهای Ryzen 9 3950X خواهند شد؛ پردازندهای که با توان مصرفی ۱۰۵ وات، سطوح عملکرد را در حوزهی پردازندههای مصارف عام بهخوبی جابهجا میکند. پیشبینی میشود که AMD با قدرت عرضهی پردازندههای EPYC Rome را با معماری Zen 2 و ساختار چندچیپلتی در ماههای آینده آغاز کند. این پردازندههای سرور با ویژگیهایی نظیر سطح عملکرد دو برابری FP و QoS و سطح عملکرد مالتی تردینگ بینظیر ۶۴ هسته بهطور همزمان، عرضه خواهند شد تا معادلات بازار پردازندههای سرور را به نفع خود برهم زنند؛ بهویژه اگر AMD روش قیمتگذاری جذاب و رقابتی خود را در سبد محصولات سازمانی نیز رعایت کند.
نظرات