پردازندهها چگونه طراحی و ساخته میشوند؟ (قسمت دوم)

در قسمت اول مقاله چرخهی اجرای دستورالعمل در یک پردازنده، مفهوم معماری پردازنده، نحوهی به جریان افتادن دستورالعملها در پایپ لاین، اجزا و عناصر سازندهی یک پردازنده و نحوه ترکیب و تعامل آنها در یک طراحی برای اجرای محاسبات پیچیده را بررسی کردیم. در این قسمت خواهیم دید که چگونه این طراحیهای شماتیک و مبتنی بر معماری بهصورت فیزیکی پیادهسازی شده و تبدیل به تراشههای دنیای واقعی میشوند.

در قسمت پیشین دریافتیم که پردازندهها و تمام مدارهای منطقی دیجیتال دیگر همگی از اجزای بسیار کوچکی با نام ترانزیستور ساخته میشوند. ترانزیستور سوئیچی با کنترل الکترونیکی است که با اعمال ولتاژ به گیت یا قطع ولتاژ میتوان آن را خاموش و روشن کرد و بذین ترتیب حالات صفر و یک منطقی را به زبان ماشین بیان کرد. همانطور که گفته شد، دو نوع ترانزیستور اصلی در مدارهای منطقی یافت میشود: ۱) ترانزیستور nMOS که با شارژ گیت اجازه عبور جریان را میدهد؛ ۲) ترانزیستور pMOS که جریان را در صورت دشارژ گیت از خود عبور میدهد. ساختار زیربنایی یک پردازنده که ترانزیستورها در آن تعبیه شده یا شکل میگیرند، از جنس سیلیکون است. سیلیکون عنصری شیمیایی با نماد Si و عدد اتمی ۱۴ است. سیلیکون بهعنوان یک نیمههادی شناخته میشود؛ چرا که نه بهطور کامل جریان را از خود عبور میدهد و نه عایق جریان است و لذا رفتاری بینابینی دارد. سیلیکونی که در صنایع ساخت تراشه به کار میرود، خلوصی برابر با «نه-نه» یا ۹۹/۹۹۹۹۹۹۹٪ دارد و تقریباً بهصورت بلورهای واحد (تککریستال) عاری از عیب است.

سیلیکون مونوکریستال مورد استفاده در صنایع ساخت تراشه
سیلیکونِ تککریستال با چنین خلوصی معمولاً از طریق فرایند چکرالسکی تولید میشود؛ فرآیندی که در کارخانجات ساخت نیمههادیها یا کارخانههای ریختهگری سیلیکون برای تولید ویفرهای سیلیکونی به کار میرود. در این شیوه ساختار بلورین به نحوی رشد داده میشود که تک بلورهای بیعیبونقصی از عنصر سیلیکون به دست آید. سیلیکون خالص یک نیمههادی ذاتی است که برخلاف فلزات، حفرههای الکترونی و الکترونهای آزادشده از اتمها طی گرمادهی را انتقال میدهد. بنابراین رسانایی الکتریکی سیلیکون با افزایش دما بیشتر میشود. در هر حال سیلیکون خالص رسانایی بسیار کم یا مقاومت بسیار بالایی در برابر عبور الکترونها دارد، به طوری که استفاده از آن بهعنوان یک جزء مداری ناشدنی است. در عمل زیرلایهی سیلیکون را با مقادیر جزئی و کنترلشدهای از عناصر معین ناهمگن میکنند که به این عمل دوپینگ اطلاق میشود. دوپینگ باعث ایجاد مناطقی با تراکم الکترون یا حفرههای الکترونی میشود و رسانایی سیلیکون بهطور چشمگیری افزایش مییابد. از سویی پاسخ الکتریکی این عنصر با کنترل تعداد حاملهای جریان فعال و شارژ مثبت و منفی این حاملها تنظیم میشود. هدف اصلی در اینجا، ایجاد تغییر در نحوهی رفتار الکترونها است، بهطوریکه بتوان آنها را کنترل کرد. همانطور که دو نوع ترانزیستور در ساختار سیلیکون میتوان ایجاد کرد، دو روش دوپینگ متناظر اصلی نیز وجود دارد.
اگر مقدار دقیق و کنترلشدهای از عناصر الکترون دهنده نظیر آرسنیک، آنتیموان یا فسفر را وارد ساختار سیلیکون کنیم، امکان ایجاد نواحی نوع n وجود دارد. از آن رو که نواحی سیلیکون آلوده به این عناصر اکنون مقادیر مازادی از الکترون دارد، این نواحی به نوعی شارژ منفی (negative) خواهد شد. نامگذاری نوع n و حرف n در ترانزیستورهای nMOS از اینجا ناشی میشود. از دیگر سو با افزودن مقادیری از عناصر گیرندهی الکترون نظیر بور، ایندیوم و گالیوم به سیلیکون، نواحی نوع p ایجاد میشود که شارژ مثبت (Positive) خواهد شد و حرف p در نام نوع p و ترانزیستورهای pMOS از همین رو است. برای افزودن این ناخالصیها به ساختار سیلیکون، از فرایندهای خاصی با نام کاشت یون و نفوذ (Diffusion) استفاده میشود که توضیح آنها خارج از حوصلهی این مقاله است.
اکنون که امکان کنترل رسانایی الکتریکی نواحی خاصی از سیلیکون و تغییر بار الکتریکی آنها وجود دارد، میتوان خواص نواحی مختلف را برای ساخت ترانزیستورها با یکدیگر ترکیب کرد. ترانزیستورهایی که در ساخت مدارهای مجتمع و پردازندههای کامپیوتری مورد استفاده قرار میگیرد، با نام MOSFET شناخته میشوند که مخفف عبارت Metal-Oxide-Semiconductor Field Effect Transistor است.
طرحی از ترانزیستور MOSFET با چهار کانکشن Gate ،Drain ،Source و Body
در ساخت مدارهای مجتمع و تراشههای کامپیوتری از ترانزیستورهای MOSFET استفاده میشود
هر ترانزیستور ماسفت (MOSFET) شامل ۴ کانکشن گیت (Gate)، منبع (Source)، درِین (Drain) و بدنه (Body) است که در آن گیت و بدنه با یک لایهی اکسید عایق از یکدیگر جدا شدهاند و منبع و درین از طریق یک کانال شارش الکترون با یکدیگر در ارتباط هستند. گیت از جنس پلی سیلیکون ساخته شده و رسانایی بالایی دارد. این بخش از ترانزیستور به منزلهی سوئیچی برای روشن و خاموشکردن ترانزیستور عمل میکند و ولتاژ متصل به آن میزان رسانایی دستگاه یا به عبارتی پهنای کانال انتقال الکترونی را تعیین میکند. در واقع ترانزیستور ماسفت برای آنکه کار کند، نیاز به برقراری ولتاژ در گیت دارد. جریان الکترونی در حال کنترل بین کانکشنهای منبع و درین ترانزیستور جریان مییابد. در ترانزیستور نوع n (یا n-Channel MOSFET) معمولاً جریان وارد درین شده و از منبع خارج میشود؛ اما در یک ترانزیستور نوع p (یا p-Channel MOSFET) جریان وارد منبع شده و از درین خارج میشود.
جزئیات فنی نحوهی کار ترانزیستورها و روش تعامل نواحی مختلف کاری است که در مدارج عالی دانشگاهی به آن پرداخته میشود و ما در این مقاله فقط مبانی کار را بررسی خواهیم کرد. یک قیاس خوب برای بیان طرز کار ترانزیستور درنظرگرفتن یک پل متحرک در مسیر یک رودخانه است. الکترونها به مثابهی ماشینهایی در ترانزیستور هستند که مایلاند از یک سمت رودخانه به سمت دیگر جریان یابند که این دو سمت را میتوان Source و Drain ترانزیستور دانست. در یک دستگاه nMOS برای نمونه، اگر گیت تحت ولتاژ نباشد و شارژ نشود، میتوان تصور کرد که دهانههای پل متحرک مثال ما بالا رفته است و امکان انتقال الکترونها از طریق کانال وجود ندارد. وقتی دهانههای پل متحرک خود را پایین بیاوریم و گیت را به ولتاژ متصل کنیم، معبر رودخانه باز میشود و الکترونها امکان حرکت آزادانه ازطریق کانال منفی (نوع n) ترانزیستور را مییابند. این همان اتفاقی است که واقعاً در یک ترانزیستور میافتد. با اتصال گیت به ولتاژ و شارژشدن آن، کانالی میان منبع و درین ترانزیستور ایجاد میشود که امکان شارش جریانی از الکترونها یا حفرههای الکترونی را میدهد.
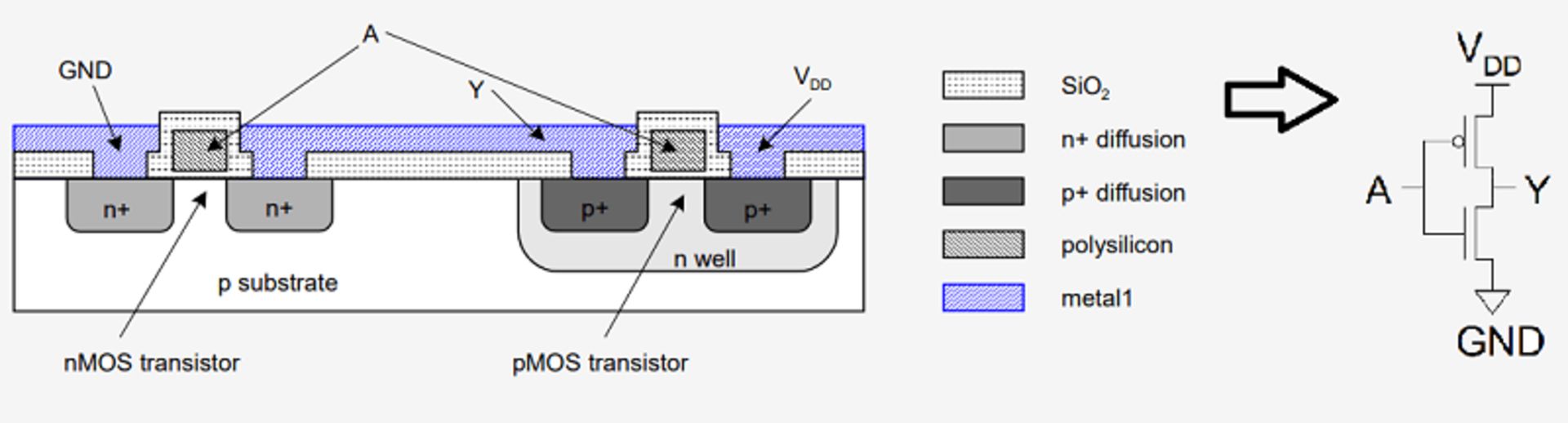
نحوهی ترکیب عملی دو ترانزیستور نوع pMOS و nMOS برای تشکیل یک گیت منطقی وارونگر. مناطق رنگی مختلف میزان رسانایی متفاوتی دارند. به نحوهی ارتباط بخشهای مختلف سیلیکون در سمت چپ و نماد وارونگر در سمت راست دقت کنید. ولتاژ ورودی به گیتهای پلی سیلیکون وارد شده و سیگنال خروجی از طریق لایهی فلزی انتقال مییابد
بنابراین برای ساخت یک تراشهی واقعی باید بتوان به روشی، مناطقی با میزان رسانایی متفاوت با ایجاد تراکم الکترون (n) یا حفرههای الکترونی (p) درست کرد. برای آنکه امکان کنترل دقیق محل قرارگیری نواحی p و n فراهم شود، تراشهسازانی مثل اینتل و TSMC از فرایندی با نام فوتولیتوگرافی استفاده میکنند. فوتولیتوگرافی فرایند چندمرحلهای بهشدت پیچیدهای است و شرکتهای بزرگ مثل اینتل و TSMC میلیاردها دلار برای بهبود و ارتقای این فرایند هزینه میکنند تا ترانزیستورهایی ظریفتر، سریعتر و با بهرهوری انرژی بیشتر تولید کنند. چاپگر بسیار دقیقی را تصور کنید که بتواند الگوهای پیچیدهی مدارهای منطقی را با دقت باورنکردنی در اعماق سیلیکون حک کند.

فرایند ساخت ترانزیستورها در یک تراشه با یک ویفر سیلیکونی خالص گرد بهمانند شکل بالا آغاز میشود. پیش از این در مورد میزان خلوص سیلیکون مورد نیاز برای ساخت MOSFETها صحبت کردیم. این ویفر در کورهای حرارت داده میشود تا لایهی نازکی از سیلیکون دیاکسید (SiO2) رویهی ویفر را بپوشاند. در مرحلهی بعد یک لایه پلیمری فوتورزیست حساس به نور روی سطح سیلیکون دیاکسید کشیده میشود. با تاباندن نوری با طول موجهای معین بر لایهی فتورزیست و با روشی به نام ماسک نوری، امکان حذف گزینشی لایهی فتورزیست در نواحی معین برای نفوذ دادن عناصر ناخالصی فراهم میشود. این همان مرحلهی لیتوگرافی است و روش انجام آن شبیه به کار چاپگری است که پودر یا جوهر را در نقاط مشخصی از کاغذ میپاشد؛ هرچند این بار ترسیم ترانزیستورها در ابعادی بسیار کوچکتر صورت میپذیرد.
در مرحلهی بعد ویفر سیلیکون با اسید هیدروفلوریک حکاکی (Etch) میشود تا مقطع سیلیکون دیاکسید را در محلی که لایهی فوتورزیست پاک شده، حل کند. سپس لایهی فتورزیست بهطور کامل حذف میشود. اکنون عناصر دوپینگ به درون ویفر نفوذ داده میشوند و این عناصر با مقادیر کنترلشده تنها در مناطقی نفوذ میکنند که پیشتر شکافهایی در لایهی اکسید ایجاد شده است.

مراحل مختلف فرایند فوتولیتوگرافی برای ایجاد ترانزیستورها در تراشهی سیلیکون
فرایند ماسک نوری، تصویر کردن و دوپینگ بارها و بارها تکرار میشود و هر سطح مشخصهای در یک نیمههادی به آرامی ساخته میشود. سرانجام پس از تشکیل سطح سیلیکون مبنا، کانکشنهای فلزی از بالا برای برقراری ارتباط میان ترانزیستورها ساخته میشود که در مورد این کانکشنها و لایههای فلزی در ادامهی مقاله بیشتر توضیح خواهیم داد.
مسلم است که تراشهسازان از این فرایند برای ایجاد یک ترانزیستور در هر مرتبه تابش استفاده نمیکنند. پس از طراحی یک تراشهی جدید، شرکتهای تراشهساز ماسکهایی را برای هر مرحله از فرایند تولید تدارک میبینند. این ماسکها هر یک حاوی محل تصویر میلیاردها ترانزیستور در یک تراشه تنها در یک مرحله تابش است. تراشههای متعددی در کنار یکدیگر روی بستر واحد ویفر تحت تابش قرار گرفته و در یک مرحله تولید میشوند.
به محض تکمیل فرایند فوتولیتوگرافی ویفر، تراشههای مجزا برش خورده و پکیج شده و در نهایت پکیجهای پردازنده آمادهی عرضه به بازار میشود. بسته به اندازهی Die پردازنده، هر ویفر ممکن است در برگیرندهی صدها تراشه باشد. عموما هرچه تراشههای تولید شده قدرتمندتر باشند، سطح مقطع Die بزرگتری دارند و سازنده تعداد تراشههای کمتری را از یک ویفر استخراج میکند.
تصور اینکه بتوان تراشههایی حجیم که هم بسیار قدرتمند بوده و هم حاوی صدها هسته باشد، تولید کرد؛ اگرچه آسان است، ولی در عمل چنین کاری ممکن نیست. در حال حاضر بزرگترین عاملی که مانع از ساختن تراشههای بزرگ و بزرگتر میشود، عیوب و نواقص ساختاری است که در خلال فرایندهای ساخت در سیلیکون ایجاد میشود. طرحهای مدرن در برگیرندهی میلیاردها ترانزیستور است و اگر تنها بخشی از یک ترانزیستور تخریب شود، ممکن است کل تراشه غیر قابل مصرف گردد. با بزرگتر شدن اندازهی پردازندهها، احتمال ایجاد ساختارهای معیوب در سیلیکون نیز بیشتر میشود.

بهرهی واقعی که شرکتها از فرآیندهای ساخت سیلیکون برمیگیرند، معمولاً در صندوقچهی اسرار تراشهسازان باقی میماند، اما بهرهی ۷۰ تا ۹۰ درصد در این مورد تخمین خوبی به نظر میرسد. فرامهندسی تراشهها با منابع بیشتر، عملی رایج در میان تراشهسازان است، چرا که آنها میدانند بخشی از اجزا ممکن است در تراشهی نهایی بهدرستی کار نکند. برای مثال اینتل ممکن است تراشهای هشت هستهای را طراحی کند، اما محصول نهایی را در قالب تراشهای شش هستهای به فروش برساند، چرا که آنها احتمال میدهند یکی دو هسته طی فرآیندهای ساخت از میان رفته باشد. تراشههایی که در انتها، میزان عیوب آنها آشکارا کمتر از دیگر تراشهها است، جداسازی شده و با قیمتهای بالاتری به فروش میرسند؛ این فرایند دستچینکردن یا Bining نام دارد.
یکی از مهمترین مفاهیم در بازاریابی آمیخته با ساخت تراشه عبارتِ «اندازهی مشخصه» یا Feature Size است. برای مثال اینتل در حال کار روی فرایند ساخت ۱۰ نانومتری است و AMD توسعه فناوری ۷ نانومتری خود را در دست اقدام دارد و شرکت تایوانی TSMC کار روی فرایند ۵ نانومتری را کلید زده است. اما معنی این اعداد و ارقام چیست؟ آیا کوچکتر بودن این اعداد نشان از فناوری ساخت پیشرفتهتری دارد؟ از چشماندازی تاریخی، اندازه مشخصهی بیانگر حداقل فاصله میان درِین و منبع یک ترانزیستور است. با پیشرفت تکنولوژی ترانزیستورها فشردهتر و ظریفتر شدند و امکان گنجاندن تعداد بسیار بیشتری از آنها در یک تراشه فراهم شد. هرچه ترانزیستورها کوچکتر شدند، به سرعتهای سوییچ بالاتری نیز دست یافتند. امروزه رقم چند میلیارد ترانزیستور در پردازندههای پیشرفتهی بازار سختافزار، شگفتیآور نیست.

تصویری از Die پردازندهی AMD با معماری Zen، میلیاردها ترانزیستور چنین ساختار پیچیدهای را ایجاد کردهاند تا امکان انجام میلیاردها محاسبه در هر ثانیه را داشته باشد
باید دانست که برخی از شرکتها ممکن است بُعد و اندازهی دیگری را سوای فاصلهی استاندارد یادشده، مبنای نامگذاری فناوری ساخت خاص خود کرده باشند و برای همین فناوریهای ساخت شرکتهای مختلف، بهراحتی بر یکدیگر انطباقپذیر نیست. ممکن است دو فرایند ناهماندازه از دو شرکت مختلف، مثلاً فناوری ۱۰ نانومتری اینتل و ۷ نانومتری AMD، در پایان سبب تولید ترانزیستورهایی با اندازه و ابعاد یکسان شود. از دیگر سو همهی ترانزیستورها در یک فرایند ساخت معین هماندازه نیستند. طراحان ممکن است براساس داد و ستدهای مهندسی، برخی از ترانزیستورها را با ابعادی بزرگتر از دیگران بسازند. در یک فرایند طراحی معین، یک ترانزیستور کوچکتر سریعتر نیز خواهد بود، چرا که شارژ و دشارژ گیت آن زمان کمتری میبرد. با این حال، ترانزیستورهای کوچکتر تنها تعداد بسیار کمی از خروجیها را به دست میدهند. چنانچه بخش معینی از مدار منطقی، نظیر یک پین خروجی برای انجام کاری در نظر گرفته شود که نیازمند اعمال توان بالایی است، ترانزیستورهای آن قسمت را باید بزرگتر ساخت. ترانزیستورهای خروجی ممکن است بارها بزرگتر از ترانزیستورهای مدارهای منطقی داخلی، پیشبینی شده و ساخته شوند.
شبکهی پیچیده ای از لایههای فلزی متعدد با تقاطعهای بسیار امکان برقراری ارتباط میان تمامی ترانزیستورها را فراهم میکنند
طراحی و ساخت ترانزیستورها تنها نیمی از مسیر ساخت یک تراشه را میپیماید. سیمها یا اتصالات فلزی باید اجزای مختلف را بر طبق شماتیک به یکدیگر متصل کند. این اتصالات با استفاده از جایگذاری لایههای فلزی روی ترانزیستورها در تراشه گنجانده میشود. بزرگراه چندطبقهای را تصور کنید که ارتباط میان طبقات با شیبهای ورودی و خروجی برقرار شده، راههای مختلف بهصورت متقاطع از درون یکدیگر عبور میکنند. این دقیقا همان اتفاقی است که درون یک تراشه و در ابعادی بسیار کوچکتر میافتد. فرایندهای مختلف تعداد لایههای اتصال درونی متفاوتی را روی ترانزیستورها ایجاد میکند. هرچه ترانزیستورها کوچکتر شوند، با ایجاد لایههای فلزی بیشتر سعی میشود راه برای عبور تمامی سیگنالها گشوده باشد. گزارشها حاکی از آن است که فناوری ساخت ۵ نانومتری پیشروی TSMC دربرگیرنده ۱۵ لایهی فلزی است. یک بزرگراه عمودی ۱۵ طبقه را تصور کنید که جادههای آن با یکدیگر در ارتباط است و تمام تقاطعهای ناهمسطح را در چنین شبکهای در نظر بگیرید؛ در این صورت تصوری تقریبی از شبکهی اتصالات فلزی در یک تراشه برای برقراری ارتباط میان اجزای سازندهی آن به دست خواهید آورد.

تصویر میکروسکوپی زیر شبکهای متشکل از ۷ لایهی فلزی را نشان میدهد. هر یک از لایهها مسطح است و هرچه بالاتر رویم، لایهها ضخیمتر میشوند تا از میزان مقاومت بکاهند. مابین لایهها استوانههای فلزی کوچکی با نام Via تعبیه میشود که کاربرد آن جهش از لایهای به لایهی دیگر است. هر لایهی فلزی معمولاً نسبت به لایهی زیرین مسیر متفاوتی را دنبال میکند تا از ایجاد ظرفیتهای خازنی ناخواسته تا حد امکان پرهیز شود. این امکان وجود دارد که لایههای فلزی فرد برای ایجاد اتصالات افقی به کار رود و از لایههای فلزی زوج برای ساخت اتصالات عمودی استفاده شود.

رشتههای فلزی برای ایجاد ارتباط میان ترانزیستورها در چندین لایه طراحی و ساخته میشوند، استوانههای کوچک عمودی Viaهایی هستند که کاربردشان جهش از لایهای به لایهی دیگر است
همان گونه که میتوان تصور کرد، پیادهسازی تمامی این معابر سیگنال و لایههای فلزی آن هم با سرعتی سرسامآور بسیار دشوار است. برای غلبه بر این مشکل، برنامههای کامپیوتری خاصی طراحی شده است تا بهطور خودکار ترانزیستورها را در اعماق تراشه جایگذاری و مسیریابی کند. بسته به پیچیدگی یک طراحی، برنامهها حتی میتوانند توابعی را که با کدهای سطح بالای C نوشته شده، در قالب مکانهای فیزیکی جز به جز رشتههای اتصال و ترانزیستورها ترجمه و اعمال کنند. معمولاً تراشهسازان به کامپیوترها اجازه میدهند عمده طراحی را بهصورت خودکار درون تراشه تصویر کنند. سپس عامل انسانی طراحی پیادهسازیشده را به دقت زیر نظر گرفته، بخشهای بحرانی را بهصورت دستی تنظیم و بهینهسازی میکند.
تراشهسازان برای ساخت یک تراشهی جدید، کار طراحی را با سلولهای استانداردی آغاز میکنند که شرکتهای ریختهگر نیمههادی در اختیار آنها میگذارند. برای مثال، اینتل و TSMC طرح اجزای زیربنایی نظیر گیتهای منطقی یا سلولهای حافظه را در اختیار طراحان میگذارند. طراحان این سلولهای استاندارد را با یکدیگر ترکیب میکنند تا در انتها طرحی کامل از تراشهای که قرار است ساخته شود، به دست آید. در مرحلهی بعد آنها طرح خود را به کارخانهی ریختهگر میفرستد، جایی که در آن سیلیکون خام تبدیل به تراشههای عملیاتی میشود. این طرح در برگیرندهی جانمایی ترانزیستورها و لایههای اتصال فلزی است. این جانماییها در ماسکهای نوری که در مورد آن صحبت کردیم، تصویر شده و از این ماسکها در فرایند فوتولیتوگرافی استفاده میشود. در ادامه با ارائهی مثالی از یک تراشهی بسیار ابتدایی، خواهیم دید که این فرایند طراحی چه شکل و شمایلی دارد.

طرحی از سلول استاندارد وارونگر
در شکل بالا طرح جانمایی (Layout) یک گیت منطقی وارونگر را که بهعنوان یک سلول استاندارد شناخته میشود، میبینیم. مستطیل سبز هاشورخورده در بالای این تصویر یک ترانزیستور pMOS است. مستطیل شفاف سبزرنگ در پایین، ترانزیستور nMOS را نشان میدهد. سیم قرمزرنگ عمودی گیت پلی سیلیکون است و نواحی آبیرنگ قسمتی از لایه فلزی ۱ و نواحی با رنگ ارغوانی بخشی از لایه فلزی ۲ است. سیگنال ورودی A از سمت چپ تصویر وارد شده و سیگنال خروجی Y از سمت راست خارج میشود، دقت کنید که لایهی فلزی ۱ در این طرح ساده مسیر حرکت سیگنالهای ورودی و خروجی است. اتصالِ توان (ولتاژ) و زمین در بالا و پایین لایهی فلزی ۲ تصویر شده است.
با ترکیب چندین گیت منطقی از این نوع، یک واحد حسابی یک بیتی مبنا به دست میآید که در شکل زیر تصویر شده است. این طراحی امکان جمع، تفریق و اعمال منطقی را روی ۲ ورودی یک بیتی دارد. سیمهای آبی کمرنگ هاشورخورده به حالت عمودی، بخشهایی از لایهی فلزی ۳ هستند. مربعهای بزرگتر در دو انتهای این سیمها، Viaهایی است که دو لایه را به یکدیگر متصل میکند.

طرح جانمایی یک واحد حسابی یک بیتی
در آخرین مرحله، با قراردادن بسیاری از این سلولها و در حدود ۲۰۰۰ ترانزیستور در کنار یکدیگر، به ساختار یک پردازندهی چهاربیتی مبنا میرسیم که با ۸ بایت رم روی چهار لایهی فلزی همراه شده است. با نگاهی به پیچیدگی ساختار پردازندهای به این سادگی، شاید بتوان تصوری از دشواری طراحی یک پردازندهی ۶۴ بیتی با چند مگابایت حافظهی کش، هستههای متعدد و بیش از ۲۰ مرحله پایپ لاین داشت. با این فرض که پردازندههای امروزی ۵ تا ۱۰ میلیارد ترانزیستور و دهها لایهی فلزی را در خود جای دادهاند، اگر بگوییم چنین قطعهای میلیونها بار پیچیدهتر از مدار نمایشدادهشده در شکل زیر است، سخن به گزاف نگفتهایم.

طرح جانمائی یک پردازندهی سادهی چهار بیتی مبنا همراهبا ۸ بایت رم
با همهی آنچه گفته شد، شاید اکنون بینش بهتری از پیچیدگی پردازندهی جدید خود و علت مبالغ نسبتاً بالایی که برای این قطعهی فناورانه میپردازید، به دست آورده باشید. همچنین علت وقفههای طولانی مدت شرکتهایی نظیر اینتل و AMD در معرفی و عرضهی محصولاتی جدیدتر و قدرتمندتر را بهتر درک خواهید کرد. ۳ تا ۵ سال زمان میبرد تا یک تراشه از میز طراحی روانهی قفسههای فروشگاهها شود. به عبارتی پردازندههای توانای امروزی حاصل سالها پیشبرد گام به گام فناوری و تجربهاندوزی است و لذا ما نمیتوانیم مدت زیادی یک تراشه را حتی با فناوری ساخت پیشتاز امروزی خود، همچنان در بالاترین جایگاهها تصور کنیم.
خطمشیهای فعلی و آینده در معماری پردازندهها
با وجود پیشرفتهای ادامهدار و ارتقای تدریجی هر نسل از پردازندههای جدید یک تراشهساز، پردازندهها برای مدتهای طولانی هیچ پیشرفت صنعتی چشمگیری به خود ندیدهاند. تبدیل تیوبهای وکیوم به ترانزیستورها یک پیشرفت بزرگ بود؛ به همین شکل حرکت از اجزای جداگانه به سوی مدارهای مجتمع گامی بلند به شمار میرفت. اما از آن زمان، حرکتهای و پیشرفتهای مشابهی با این ابعاد دیگر در دنیای پردازندهها دیده نشده است. درست است که ترانزیستورها کوچکتر شدهاند، سرعت تراشههای کامپیوتری بیشتر شده و سطح عملکرد صدها برابر افزایش یافته، اما در عین حال شاهد کندیها و عقبگردهایی آشکار در روند ساخت تراشهها نیز هستیم.
براساس قانون مور تعداد ترانزیستورهای پردازندههای کامپیوتری هر ۱۸ ماه یک بار دو برابر میشوند
از آنجایی که شرکتهای تراشهساز اطلاعات چندانی از پژوهشهای فعلی و جزئیات فناوریهای کنونی خود ارائه نمیدهند، داشتن درکی دقیق از آنچه درون یک پردازنده میگذرد، دشوار است. اما میتوان با نگاهی به روند مطالعات کنونی در این صنعت، به درکی از چشمانداز و دورنمای ساخت تراشهها در دنیای کامپیوتر دست یافت.
یکی از گزارههای مشهور صنعت ساخت پردازنده قانون مور است. این قانون میگوید، تعداد ترانزیستورهای گنجاندهشده در پردازندهها، تقریباً هر ۱۸ ماه یک بار دو برابر میشود. اگرچه این قانون برای مدتهای طولانی پابرجا بود، اما اکنون مدتی است که با فرود و فرازهایی روبهرو شده است. با هرچه کوچکتر شدن ترانزیستورها، به مرز و محدودههایی نزدیک میشویم که قوانین فیزیک دیگر امکان گذر از آن را فراهم نمیکند. بدون یک فناوری جدید تکاندهنده در صنعت ساخت تراشه، باید به فکر راههای جدیدی برای تسریع عملکرد پردازندهها در مسیر آینده باشیم.
روند پیشروی نسل به نسل تراشهها در خلال ۱۲۰ سال گذشته،۷ نقطه آخر در این نمودار مربوط به پردازندههای گرافیکی انویدیا است
یکی از راهکارهایی که شرکتهای تراشهساز برای تداوم روند پیشرفتهای خود و بهبود سطح عملکرد برگزیدهاند، افزایش شمار هستههای یک پردازنده بهجای ارتقای فرکانس است. به همین دلیل بهجای آنکه شاهد تراشههای دو هستهای با فرکانس ده گیگاهرتز باشیم، تراشههای ۸ یا ۱۰ هستهای با فرکانسهای بسیار کمتر را در بازار میبینیم. در یک کلام میتوان گفت، پردازندههای امروزی بهجز در بخش افزایش تعداد هستهها، جای پیشرفت چندانی ندارند.
رویکرد نسبتاً جدید دیگری که در دنیای پردازندهها دیده میشود، استفاده از چیپلتهای متعدد روی یک لایهی اینترپوزر است. چیپلت بلوک مجزایی از مدارهای مجتمع است که بخشی از یک تراشهی چند چیپلتی را میسازد. تراشهسازانی مانند AMD در پردازندههای رایزن بهجای ساخت تراشههایی با مقطع پهناور و شامل هستههای متعدد، منابع ترانزیستور موجود در یک تراشه را میان چندین چیپلت توزیع میکنند. پیش از این دانستیم که ساخت تراشهای گسترده با هستههای متعدد احتمال ایجاد عیوب ساختاری و ناکارآمد شدن یک تراشه را زیاد میکند. برخی از این چیپلتها محاسباتی هستند که دربرگیرندهی هستهها و تردها و سطوح مختلف حافظهی کش هستند. این چیپلتهای محاسباتی معمولا با چگالی ترانزیستور بالاتر و فناوری ساخت پیشرفتهتری تولید میشوند. AMD چیپلتهای محاسباتی نسل سوم رایزن را با فناوری ساخت ۷ نانومتری میسازد. در این میان چیپلتی نیز برای قرارگیری منابع ارتباطی پردازنده با دنیای بیرون نظیر کنترلرها، کانالهای ورودی/خروجی و مسیرهای ارتباطی PCIe بهطور مجزا ساخته میشود. این چیپلت معمولاً با فناوری ساخت ارزانتر و بزرگتری (مثلاً ۱۴ نانومتری) ساخته میشوند. ساخت پردازندههای چند چیپلتی راهکار تراشهسازان برای غلبه بر محدودیتهایی است که تبعیت از قانون مور تحمیل میکند. در پردازندههای رایزن ارتباط میان چیپلتهای محاسباتی و چیپلت ورودی/خروجی از طریق لینکهای Infinity Fabrics برقرار میشود. لایهی اینترپوزر اگرچه چگالی کمتری نسبت به چیپلتها دارد، اما بستر مناسبی برای صدها مسیر و معبر اتصال و برهمکنش میان اجزای پردازنده است. شرکتهایی مانند AMD با فناوری پردازندههای چندچیپلتی و اینتل با فناوری تجمیع تراشهی سهبعدی Foveros میکوشند تا با روشهایی ابتکاری همچنان در مرزهای قانون مور حرکت کنند.

تراشهی چندچیپلتی Zen 2، هر یک از چیپلتهای کوچکتر شامل ۸ هستهی پردازنده بوده و چیپلت بزرگتر در مرکز چیپلت I/O است
یکی از بخشهایی که چشمانداز خوبی در آینده برای آن متصور است، پردازش کوانتومی است. پردازش کوانتومی یک فناوری نوپا است و کارشناسان متبحر زیادی هنوز برای گسترش مرزهای آن در جهان تربیت نشده است. برخلاف افسانههایی که در مورد این فناوری مطرح است، پردازش کوانتومی چیزی نیست که شما را قادر به رندر صحنههای یک بازی با سرعت ۱۰۰۰ فریمبرثانیه کند. در حال حاضر مزیت اصلی کامپیوترهای کوانتومی، امکان اجرای الگوریتمهای پیچیدهتری است که در گذشته ناممکن بوده است.
در یک کامپیوتر معمولی، روشن و خاموش بودن یک ترانزیستور، معادل یکی از دو دادهی اساسی ۰ و ۱ است. اما در یک کامپیوتر کوانتومی با مفهوم Superposition روبهرو هستیم، به این معنا که یک بیت همزمان میتواند مقدار صفر و یک را اختیار کند. با این ویژگی جدید، دانشمندان علوم کامپیوتر میتوانند روشهای محاسبه جدیدی را توسعه دهند و مسائلی را حل کنند که در حال حاضر قابلیتهای محاسباتی کافی برای حل آن نداریم. به عبارت دیگر، کامپیوترهای کوانتومی حتی ممکن است چندان سریعتر از کامپیوترهای امروزی نباشند؛ اما این کامپیوترها در برگیرندهی مدلهای محاسباتی جدیدی هستند که امکان حل انواع مختلفی از مسائل را فراهم میکنند.

این فناوری هنوز تا رسیدن به خانهها و فراگیرشدن راه درازی در پیش دارد؛ بنابراین ما در این مقاله بیشتر بهدنبال شناخت روندهایی هستیم که پردازندههای دنیای واقعی را در مسیر آینده بهبود میبخشد. اگرچه امروزه دهها پروندهی تحقیقاتی فعال در این زمینه گشوده شده است؛ اما ما در این مقاله به بررسی بخشی از این روندهای پژوهشی خواهیم پرداخت که بیشترین تأثیرها را از خود برجای مینهد.
روند در حال رشدی که ما تا به امروز تأثیر زیادی از آن پذیرفتهایم، مفهومی با نام پردازش نامتجانس است. با این روش، چندین المان محاسباتی مختلف در یک سیستم واحد گرد هم آمده، روند پردازش را بهبود میبخشد. بسیاری از ما با داشتن یک پردازنده گرافیکی (GPU) مجتمع در سیستم خود از مزایای پردازش نامتجانس بهرهمند شدهایم. CPU قطعهای با قابلیت سفارشیسازی بالا است و میتواند گستره وسیعی از محاسبات را با سرعت منطقی اجرا کند. از سوی دیگر GPU بهطور اختصاصی برای اجرای محاسبات گرافیکی نظیر ضرب ماتریسی توسعه یافته است. این قطعهی سختافزاری در انجام این کار بسیار توانا است و چنین محاسباتی را بارها سریعتر از CPU انجام میدهد. با برداشتن بار اجرای محاسبات گرافیکی از دوش CPU و گذاردن آن به عهدهی GPU، روند اجرای بارهای کاری تسریع میشود. برای برنامهنویسان ارتقای نرمافزار با بهینهسازی الگوریتمها ساده است، اما بهبود کار قطعات سختافزاری کاری بسیار پیچیدهتر است.
پردازندههای گرافیکی تنها حوزهای نیست که در آن از شتابدهندهها برای پردازش دستورالعملهای خاص استفاده میشود. بیشتر گوشیهای هوشمند امروزی دربرگیرندهی دهها شتابدهندهی سختافزاری هستند که اجرای وظایف انحصاری و ویژه را تسریع میکنند. این سبک پردازش را دریای شتابدهندهها مینامند و مثالهایی از آن شامل پردازندههای رمزنگاری، پردازندههای تصویر، شتابدهندههای یادگیری ماشین، دیکودرها و انکودرهای ویدئو، پردازندههای بیومتریک و موارد دیگر است.
با تخصصیشدن بیشازپیش بارهای کاری، طراحان سختافزار شتابدهندههای بیشتر و بیشتری را در تراشههای خود میگنجانند. تأمینکنندگان سرویسهای پردازش ابری نظیر AWS شروع به تأمین کارتهای FPGA برای توسعهدهندگان کردهاند تا بارهای کاری مطلوب آنها را در فضای ابری سریعتر به پیش ببرند. در حالی که المانهای پردازش رایج نظیر CPU و GPU معماری داخلی ثابتی دارند، FPGA دارای معماری دستورالعمل منعطفی است. این قطعهی سختافزاری قابل برنامهریزی را میتوان به نحوی پیکربندی کرد که منطبق بر نیازهای پردازشی کاربران باشد.
اگر کاربر خواستار قابلیت تشخیص تصاویر باشد، امکان پیادهسازی الگوریتمهای متناظر در این قطعه سختافزاری وجود دارد. اگر کاربری بخواهد طرز کار یک قطعه سختافزاری جدید را پیش از ساخت شبیهسازی کرده و بیازماید، امکان اجرای این آزمایش با FPGA وجود دارد. FPGA سطح عملکرد و بهرهوری توانی بیشتری در مقایسه با پردازندههای گرافیکی ارائه میدهد، اما در این زمینه به پای مدارهای مجتمع اپلیکیشن محور یا ASICها نمیرسد. شرکتهایی نظیر گوگل و انویدیا ASICهای یادگیری ماشین اختصاصی خود را برای تسریع روند تشخیص و تحلیل تصاویر توسعه دادهاند.
با نگاهی به تصاویر Die برخی از پردازندههای نسبتاً جدید، میتوان دریافت که بیشتر سطح مقطع یک پردازنده را بخشهای دیگری به جز هستهها اشغال کرده است. میزان فزایندهای از این مقطع با شتابدهندههای مختلف پر شده است. با این کار بسیاری از بارهای کاری ویژه با سرعت بیشتری عملیاتی شده و بهعلاوه تا حد زیادی در توان مصرفی صرفهجویی خواهد شد.

تصاویری از Die برخی از پردازندههای امروزی مبتنی بر معماری آرم که در هر یک هسته های پردازنده بخش نه چندان بزرگی از کل مقطع را اشغال کرده است
از گذشته تا به حال، تراشههای مخصوصی برای پردازش محتوای ویدئویی به کمک پردازندهها آمده است. اما این روش به هیچ عنوان بازدهی کافی ندارد؛ چرا که هر بار سیگنال متناظری باید از تراشه اصلی خارج شده و از طریق سیمهای فیزیکی روانهی تراشه دیگری شود و نتیجه پردازش دوباره به پردازنده بازگردد. با چنین فرآیندی میزان مصرف انرژی به ازای هر بیت داده بهشدت افزایش مییابد. اگر المان پردازش مورد نظر درون تراشهی پردازندهی اصلی گنجانده شده باشد، برای ایجاد ارتباط با این المان در یک تراشهی واحد، ۳ تا ۴ برابر بهره وری توانی بهتری در مقایسه با روش قبلی خواهیم داشت. با یکپارچهسازی چنین شتابدهندههایی در پردازندهی اصلی، شاهد رشد فزایندهی تراشههایی با مصرف توان بسیار ناچیز در سالهای اخیر بودهایم.
اما مشکل دیگری وجود دارد و این است که شتابدهندهها خود بخشهای کامل و بیعیبونقصی نیستند. هرچه تعداد بیشتری از آنها را به طراحی خود اضافه کنیم، از انعطافپذیری تراشهها کاسته شده و به بهای دستیابی به حداکثر کارایی در بارهای کاری ویژه، سطح عملکرد کلی تراشه افت میکند. در چنین حالتی، تمامی تراشه تبدیل به گردایهای از شتابدهندهها میشود و دیگر با یک پردازندهی سودمند روبهرو نیستیم. داد و ستدهای مهندسی بین سطح عملکرد در حالات ویژه و سطح عملکرد عمومی یک تراشه همواره باید بهخوبی تنظیم و تعدیل شود. به این عدم تطابق میان سختافزار تعمیم یافته و بارهای کاری ویژه، شکاف ویژهکاری (Specialization Gap) اطلاق میشود.
اگرچه عدهای تصور میکنند ما به بالاترین سطوح امواج یادگیری ماشین و پردازندههای گرافیکی دست یافتهایم، میتوان همچنان انتظار داشت که سهم بیشتری از محاسبات برای اجرا به شتابدهندههای ویژهکار محول شود. با رشد روزافزون محاسبات ابری و هوش مصنوعی، به نظر میرسد که پردازندههای گرافیکی تاکنون بهترین راهحل برای نیل به ظرفیتهای عظیم محاسبات دادهی موردنیاز است.
حوزهی دیگری که طراحان در پی استخراج سطح عملکرد بالاتری از آن هستند، حوزهی حافظه است. از گذشته تا به حال سرعت خواندن و نوشتن حافظه بزرگترین گلوگاه برای پردازندهها بوده است. اگرچه حافظههای بزرگ و سریع کش راهگشا هستند، اما همچنان خواندن اطلاعات از رم یا درایو SSD دهها هزار سیکل کلاک به طول میانجامد. به همین دلیل، مهندسان غالباً فرایند دسترسی به حافظه را کاری پرهزینهتر نسبت به انجام محاسبات واقعی در پردازندهها میدانند. اگر پردازنده بهدنبال جمع دو مقدار عددی با یکدیگر باشد، ابتدا باید آدرسهایی از حافظه را که اعداد در آن ذخیره شدهاند، محاسبه کرده و دریابد در کدام سطح از سلسلهمراتب حافظه این دادهها قرار گرفتهاند، دادههای موجود در ثباتها را بخواند، محاسبهی مورد نظر را اجرا کند، آدرس مقصد را محاسبه کرده و پاسخ عملیات را در هر جایی که به آن نیاز است، بنویسد. این فرایند چندمرحلهای برای دستورالعملهایی که اجرای آنها یک تا دو سیکل طول میکشد، بسیار ناکارآمد است.
ایدهی نوآورانهای که حجم زیادی از پژوهشها را به خود اختصاص داده، تکنیکی با نام انجام محاسبه در مجاورت حافظه (Near Memory Computing) است. در این روش بهجای واکشی بیتهای محدود داده از حافظه و رساندن آن به پردازنده برای انجام محاسبه، واحدهای پردازش کوچکی مستقیماً درون کنترلرهای حافظهی رم یا SSD تعبیه میشود. انجام محاسبات سبکتر در محلی نزدیک به حافظه، پتانسیل صرفهجویی زیادی در انرژی و زمان ایجاد میکند؛ چرا که نیازی به انتقال هرباره و همیشگی دادهها نیست. از آنجایی که کنترلر درست در کنار تراشههای حافظه قرار دارد، واحدهای پردازش یادشده دسترسی مستقیم به دادههای مورد نیاز خود دارند. اگرچه این ایده هنوز به مرحلهی بلوغ و پختگی نرسیده است، نتایج حاصل از آن به نظر نویدبخش میرسد.
یکی از دشواریهای محاسبه در مجاورت حافظه که باید بر آن غلبه شود، محدودیتهایی است که در فناوری ساخت وجود دارد. پیش از این گفتیم که فرایند ساخت سیلیکون کاری بسیار پیچیده با دهها مرحله است. پردازندهها از ابتدا به نحوی طراحی میشوند که دربرگیرندهی المانهای منطقی سریع یا شامل المانهای ذخیرهسازی فشرده باشند. اگر بخواهیم تراشهی حافظهای با فرایند ساخت پردازش محور تولید کنیم، با چالش چگالی ناکافی در تراشه روبهرو هستیم. حال اگر بخواهیم پردازندهای با فرایند ساخت مختص ذخیرهسازی تولید کنیم، نتیجهی کار سطح عملکرد و تایمینگ بسیار ضعیف خواهد بود.
طرحی شماتیک از روند تجمیع سهبعدی لایههای متوالی ترانزیستورها
تکنیک تجمیع سهبعدی ترانزیستورها راهی برای ساخت تراشه های حافظهی بسیار سریع با امکان انجام محاسبه در نزدیکی حافظه است
یک راهحل بالقوه برای غلبه بر این مشکل، تکنیکی با نام تجمیع سهبعدی است. پردازندههای رایج از یک لایه ترانزیستور بسیار گسترده برخوردار هستند، اما این طراحی محدودیتهای خود را دارد. همانطور که نام این تکنیک ایجاب میکند، تجمیع سهبعدی عبارت است از انباشت چندین لایه ترانزیستور روی یکدیگر با هدف بهبود چگالی ترانزیستورها و کاهش تأخیر. در این شیوه از ستونهایی عمودی که طی فرآیندهای متفاوتی ساخته میشوند، برای ایجاد ارتباط میان لایهها استفاده میشود. اگرچه این پیشنهاد دیر زمانی است که مطرح شده؛ در ابتدا صنعت بنا به مشکلات عمدهای که در راه اجرای آن وجود داشت، چندان از آن استقبال نکرد؛ اما بهتازگی شاهد درخشش فناوری ذخیرهسازی 3D NAND و بازگشایی پروندههای مطالعاتی در این زمینه هستیم.
علاوه بر تغییراتی که در فیزیک و معماری تراشهها در سالهای گذشته صورت پذیرفته، خط مشی دیگری که کل صنعت ساخت نیمههادی را متاثر ساخته، مقولهی امنیت است. تا همین اواخر هم بحث امنیت پردازندهها چندان در کانون توجه قرار نداشت. تحکیم امنیتی، جوششی از این واقعیت است که در دنیای کامپیوترها باید امنیت بیشتری داشته باشیم. در دنیای پردازندهها این واقعیت گریبانگیر شرکتهای تراشهساز، بهویژه اینتل شده است.
حفرههای اسپکتر و ملت داون شاید معروفترین مثالهایی باشد که به ما نشان میدهد، هر اقدامی برای افزایش سرعت کار پردازنده، بدون درنظرگرفتن منافذ امنیتی آن ممکن است عواقب ناخوشایندی داشته باشد. در حال حاضر پردازندههای مدرن تأکید بسیار بیشتری بر مبحث امنیت دارند و امنیت یکی از حلقههای اصلی طراحی تراشهها است. افزایش میزان امنیت پردازندهها ممکن است سطوح عملکرد را تا حدی متاثر سازد، اما با درنظرگرفتن آسیبهایی که حفرههای امنیتی میتواند به بار آورد، بهتر است به همان اندازهای که به کارایی یک تراشه اهمیت میدهیم، بر امنیت آن نیز متمرکز شویم.

خلاصه ای از آنچه در این دو مقاله خواندیم
در مجموع این دو مقاله سعی کردیم درکی مستحکم و پایدار از شیوههای طراحی و ساخت پردازندهها در ذهن خوانندگان گرامی زومیت ایجاد کنیم. بحث را با شناخت روش اجرای دستورالعملها در یک پردازنده شروع کردیم و با معماریهای مجموعه دستورالعمل آشنا شدیم. دیدیم که چگونه یک پردازنده قادر است در هر سیکل کلاک دستورالعملهای متعدد را در مراحل مختلف پایپلاین به جریان اندازد. پس از آن با اصلیترین مفاهیم پردازنده شامل ترانزیستورها، گیتهای منطقی، سیگنال کلاک و واحدهای عملیاتی شامل هستهها، تردها، حافظهی کش و پیشبینیگر انشعاب آشنا شدیم و طرز کار هر یک را به سادهترین شکل ممکن تبیین کردیم. سلسلهمراتب حافظه و نحوهی تعامل پردازنده با حافظهی سیستم را توضیح دادیم و سپس به سراغ روش طراحی پردازندهها رفتیم. در مرحله بعد با فرایندهای تبدیل طراحیها به تراشههای فیزیکی و فوتولیتوگرافیِ قطعات سیلیکونی آشنا شدیم و سرانجام در مورد خطمشی حال و آیندهی پردازش و زمینههای مطالعاتی گستردهی آن صحبت کردیم.
در پایان از شما همراهان گرامی زومیت می خواهیم پیشنهادها و نظرات خود را در مورد محتوای این مقالات با ما در میان بگذارید.