بررسی هستههای جگوار، برگ برندهی AMD که سونی و مایکروسافت در کنسولهای نسل بعدی از آن استفاده کردهاند

امروزه معماری پردازندهها واقعاً محدود است و توان مصرفی عامل اساسی در این محدودیت به حساب میآید. وقتی مسئله، طراحی یک پردازنده با توان مصرفی مشخص باشد، میتوان از یک معماری کلی استفاده کرد و با اعمال تنظیمات خاص، به توان مورد نظر رسید. بهعنوان مثال دو معماری معروف اینتل برای پردازندهها را در نظر بگیرید، منظورمان سندی بریج و آیوی بریج است. در بازار با پردازندههای مختلفی که محدودهی ۱۳ تا ۱۳۰ وات را پوشش دادهاند روبهرو میشویم. البته بازدهی پردازندههایی که بسیار زیاد یا بسیار کم مصرف میکنند بهینه نیست و معمولاً برای توان مصرفی کم و زیاد، از معماریهای دیگری استفاده میشود.

هر دو کمپانی معروف اینتل و ایامدی از این روش استفاده میکنند، اینتل پردازندههای خانوادهی اتم را با توان مصرفی پایین، پردازندههای سری Core را برای مصرف معمولی و زیاد ارائه کرده است. ایامدی در سال ۲۰۱۰ بابکت (Bobcat) را در نقشه راه پردازندههای کممصرف خود قرار داد و بولدوزرها در ردهی پردازندههای پرمصرف و قدرتمند.
هر دو معماری بابکت و بولدوزر به صورت سالانه به روز شدهاند. در سال ۲۰۱۱ در دو مدل از پلتفرم برَزو (Brazos) یعنی SoCهای آنتاریو و زاکِیت (Zacate) شاهد استفاده از بابکت بودیم. منظور از SoC تراشههایی است که امروزه در تبلتها و گوشیها به کار میروند و علاوه بر پردازندهی اصلی و گرافیکی، شامل حافظه، واسطهایی مثل شبکه و USB، مودم باند پایه و غیره است.
در سال ۲۰۱۲ هم با بروزوی دوم آشنا شدیم. بازهم همان هستههای بابکت ولیکن با تغییراتی استفاده شد. حالا پس از ۲-۳ سال، نوبت به یک بروز رسانی جدی است، چراکه اینتل و معماری ARM هم بهشدت برای به دست آوردن سهم بیشتر از بازار وسایل کممصرف و همراه تلاش میکنند. اینجا است که ایامدی هستههای جگوار را معرفی میکند.
جگوار و بهینهسازی معماری تخصیص دوگانه و خارج از نوبت
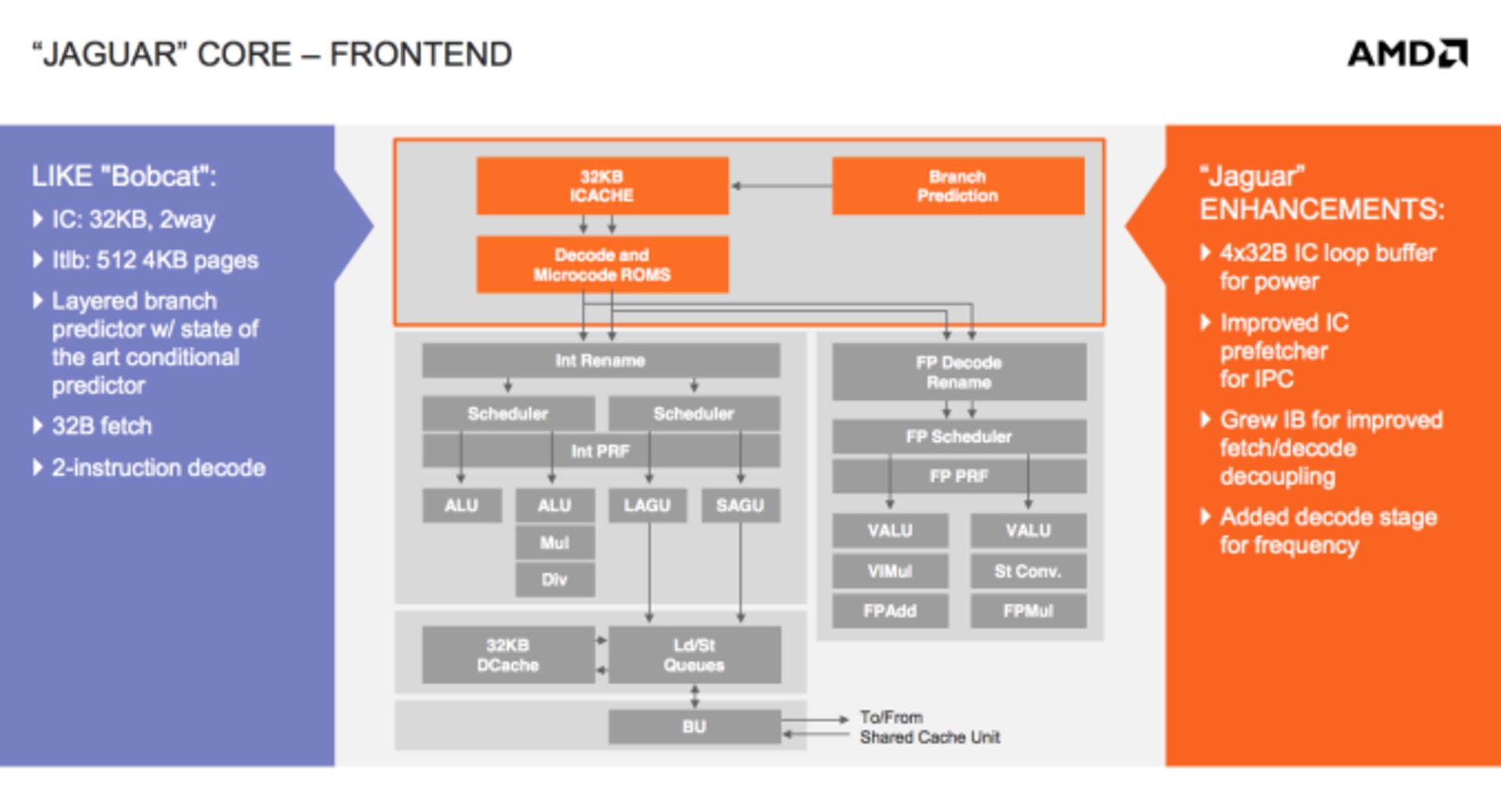
ابتدا سراغ هستههای جگوار میرویم و تنها یک هسته را بررسی میکنیم، شباهت آن با بابکت زیاد است. همان معماری دو تخصیصه و خارج از نوبت که در سال ۲۰۱۰ معرفی شده بود، بازهم مورد استفاده قرار گرفته است. منظور از اجرای خارج از نوبت این است که پردازنده در مواقعی که دادهی ورودی داشته باشد، بدون اتلاف کلاک به اجرای دستورها میپردازد و خود را درگیر تأخیرهای موجود نمیکند. همان کش سطح ۱ یا L1 واسط نهایی و بلوکهای اجرایی هنوز بر قوت خود باقی هستند. در حقیقت ایامدی هم مثل ARM به اجرای خارج از نوبت دستورها روی آورده است. همان چیزی که در Cortex-A15 وجود دارد. وجه تمایز اینتل و ایامدی با Cortex-A15 در تعداد تخصیص است. منظور از Issue (یا تخصیص) در زبان اینتل و آیبیام و دیگران متفاوت است اما معمولاً به انتقال یک دستور پردازشی (یا Instruction) از موقعیتی در پایپلاین (یا کانال اطلاعات) به یک موقعیت دیگر، Issue گفته میشود.
در Cortex-A15 از ۳ تخصیص استفاده میشود به این معنی که در یک سیکل کلاک میتوان سه دستور را جابهجا کرد، اما اینتل و ایامدی بهدنبال کاهش مصرف انرژی بوده و در آخرین نسل اتم یعنی سیلورمونت و نیز جگوار، همچنان از ۲ تخصیص استفاده میشود و افزایش آن به آینده موکول شده است.
گذشته از حرکت به سمت استفاده از لیتوگرافی ۲۸ نانومتری، تمرکز اصلی ایامدی روی افزایش کارایی با همان توان مصرفی قبل بوده است. بابکت در نتبوکها و نتاپها و سایر محصولات ارزانقیمت و نیز ضخیم به کار رفته اما جای آن در محصولات باریکی مثل تبلت خالی است. جگوار قصد ورود اساسی به دنیای تبلت را هم دارد. شاید ایامدی فعلاً در مورد گوشیهای هوشمند برنامهی خاصی ندارد، ولیکن بازار تبلت هم چیز کمی نیست. در تبلتهای ارزانقیمت، ارتباط تلفنی مهم نیست و لذا ایامدی میتواند بعد از اینتل بزرگترین تأمینکنندهی تراشه باشد.
در جگوار از ۴ حلقهی ۳۲ بایتی بهعنوان بافری برای کش دستورها استفاده میشود. وقتی یک حلقه تشخیص داده شد، به جای فراخوانی مجدد دستورها اجرا شده از کش L1، از همین حلقهی کوچک بافر استفاده میشود. تنها مزیت این روش فراخوانی این است که دیگر نیازی به فعالیت کش دستورها در هر بار اجرای یک حلقه نیست و لذا مصرف انرژی کاهش مییابد و کارایی افزایشی نخواهد داشت.
هر معماری جدیدی قبل از تولید انبوه، بارها و بارها مورد آزمایش قرار میگیرد تا گلوگاهها شناسایی شوند و در طراحیهای بعدی، مورد بررسی بیشتر قرار گیرند. برطرف کردن گلوگاهها هم همواره با توجه به هزینهها و زمانبندی عرضهی محصولات جدید صورت میگیرد.
ایامدی در طراحی جگوار از همان واسط نهایی ۲ تخصیص استفاده کرده و به جای استفاده از کش مایکرو-آپ یا کش ردگیری، به استفاده از یک بافر حلقهی دستورها روی آورده است تا تدریجاً در طراحیهای بعدی، زمان و هزینهی لازم برای اعمال تغییرات بیشتر را پیدا کند.
ایامدی کش پیشفراخوانی دستورها را هم بهینهتر کرده، علت استفاده از پهنای باند بیشتر نیست بلکه زمان بیشتری در طراحی و اعمال آن گذاشته شده است. اندازهی بافر دستورها بین کش دستورها و دیکودر (یا رمزگشا) از نظر اندازه پیشرفت کرده اما در هنوز تا رسیدن به مراحل فراخوانی و رمزگشایی بسیار مستقلی که در بولدوزر سراغ داریم، فاصلهی زیادی وجود دارد.
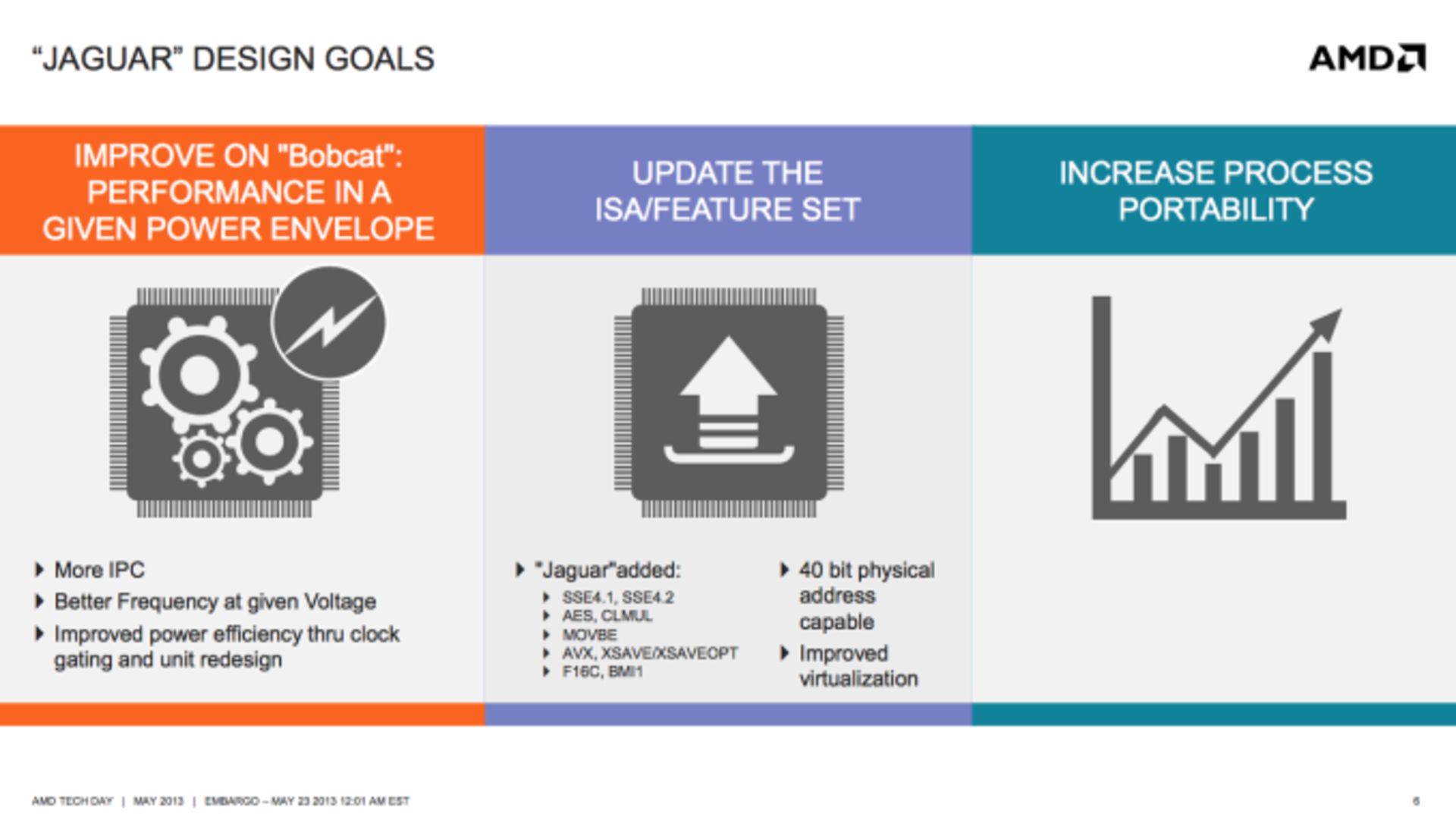
در جگوار از سلسله دستورها جدیدتری پشتیبانی به عمل آمده که SSE4.1 ،SSE4.2 ،AES ،CLMUL ،MOVBE ،AVX ،F16C و BMI1 جزء آن است، آدرسدهی فیزیکی ۴۰ بیتی نیز پشتیبانی شده است.
آخرین تغییری که در جگوار رخ داده، اضافه شدن یک مرحلهی رمزگشایی دیگری است که هدف از آن افزایش فرکانس است. در بابکت یکی از مشکلات اساسی که فرکانس ماکسیمم را محدود میکرد، دیکودر بوده، بنابراین اضافه شدن یک مرحلهی جدید رمزگشایی، فرکانس جگوارهای ۲۸ نانومتری را افزایش خواهد داد.
اجرای محاسبات اعداد صحیح و ممیز شناور
از نظر اجرای محاسبات اعداد صحیح، واحدها و پایپلاین تقریباً مشابه بابکت هستند. بزرگترین تغییر در این بخش استفاده از مقسم سختافزاری است که در نسل اول APUهای ایامدی یعنی Llano استفاده میشود. بابکت دارای مقسم اینتیجر مایکروکدشدهای بود که در هر سیکل کلاک، یک بیت را پردازش میکرد. در جگوار مقسم با قدرت ۲ برابر وجود دارد. با توجه به اینکه سختافزار با کلاک فعالیت میکند و لذا اگر استفادهای از آن نشود، مصرف انرژی هم بیشتر نخواهد بود.
بافرهای زمانبندی و مرتبکننده در جگوار بزرگتر شدهاند. منابع اجرای خارج از نوبت هم افزایش یافتهاند و بخش زمانبندی دچار تغییراتی شده است.
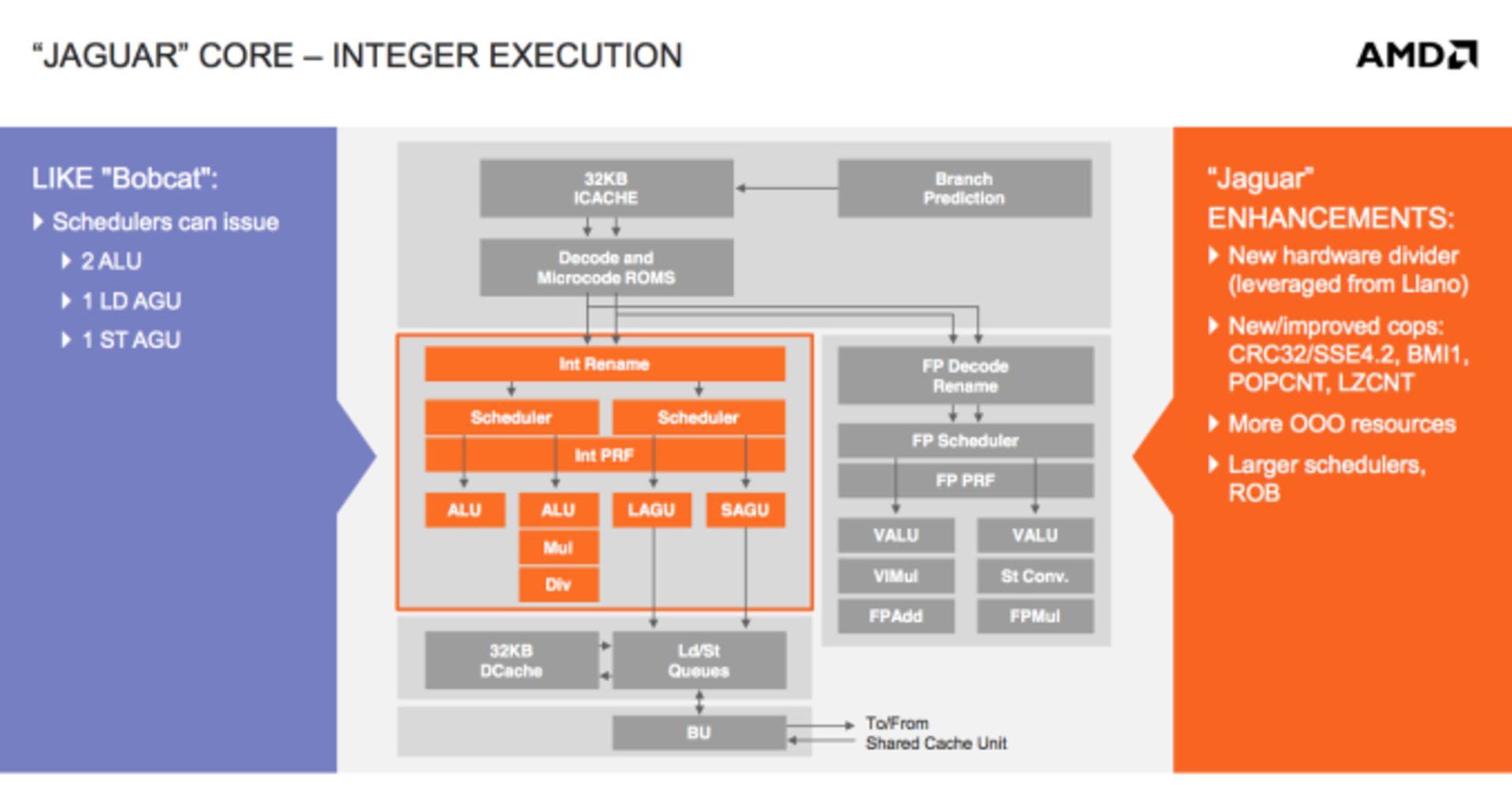
در بابکت مشکل خاصی در اجرای اینتیجر وجود نداشت اما در مورد ممیز شناور وضعیت کاملاً متفاوت بود. محاسبات ممیز شناور سنگین در بابکت نسبت به اتمهای اینتلی کندتر بودند. علت تا حدی به بهرهمندی اتم از هایپر تردینگ برمیگردد. ایامدی برای حل مشکل اجرای ممیز شناوری را بهینه کرده و البته تعداد هستههای پردازشی را افزایش داده که نقش عامل دوم مهمتر است.
در بابکت از واحدهای ۶۴ بیتی برای اجرای ممیز شناور استفاده میشود. بنابراین برای اجرای یک عمل ممیز شناوری ۱۲۸ بیتی، باید از دو مرحلهی کوچکتر استفاده میشد. در جگوار از واحدهای ۱۲۸ بیتی استفاده شده است. دستورها AVX به صورت ۲ عمل ۱۲۸ بیتی انجام میشوند اما سایر اعمال ۱۲۸ بیتی، بدون مرحلهمرحله شدن و استفاده از پایپلاین، در یک مرحله انجام میشود. بنابراین افزایش پهنای بردار علت افزایش کارایی در بحث محاسبات ممیز شناور است.
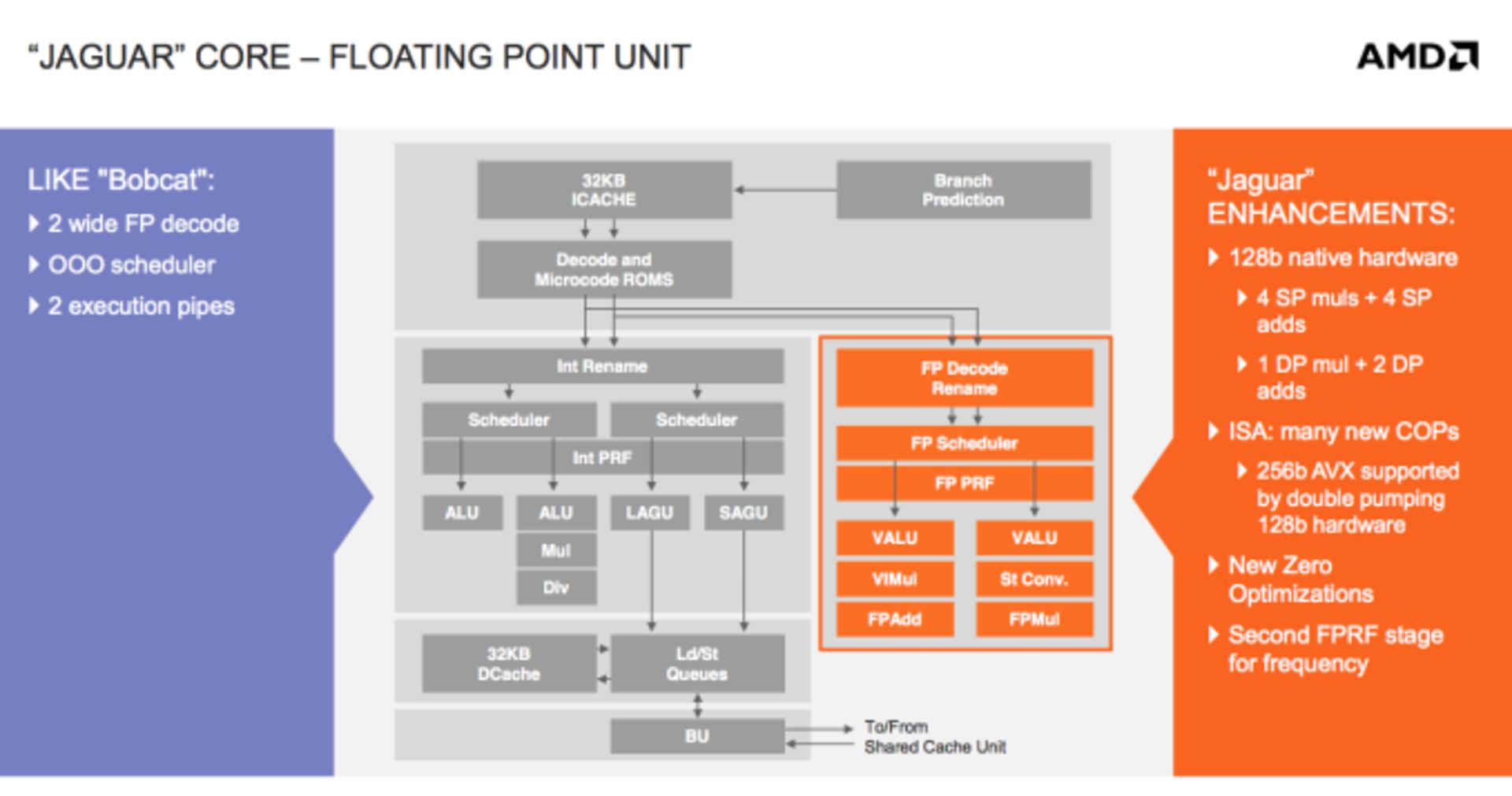
ایامدی به خاطر استفاده از بردارهای ۱۲۸ بیتی در واحد پردازش ممیز شناور یا FPU مجبور شده به پایپلاین هم یک مرحلهی دیگر اضافه کند چراکه افزایش اندازهی FPU باعث افزایش زمان جابجایی از یک موقعیت به موقعیت دیگر میشود و لذا به یک مرحلهی اضافی نیاز داریم.
ذخیرهسازی و بارگذاری
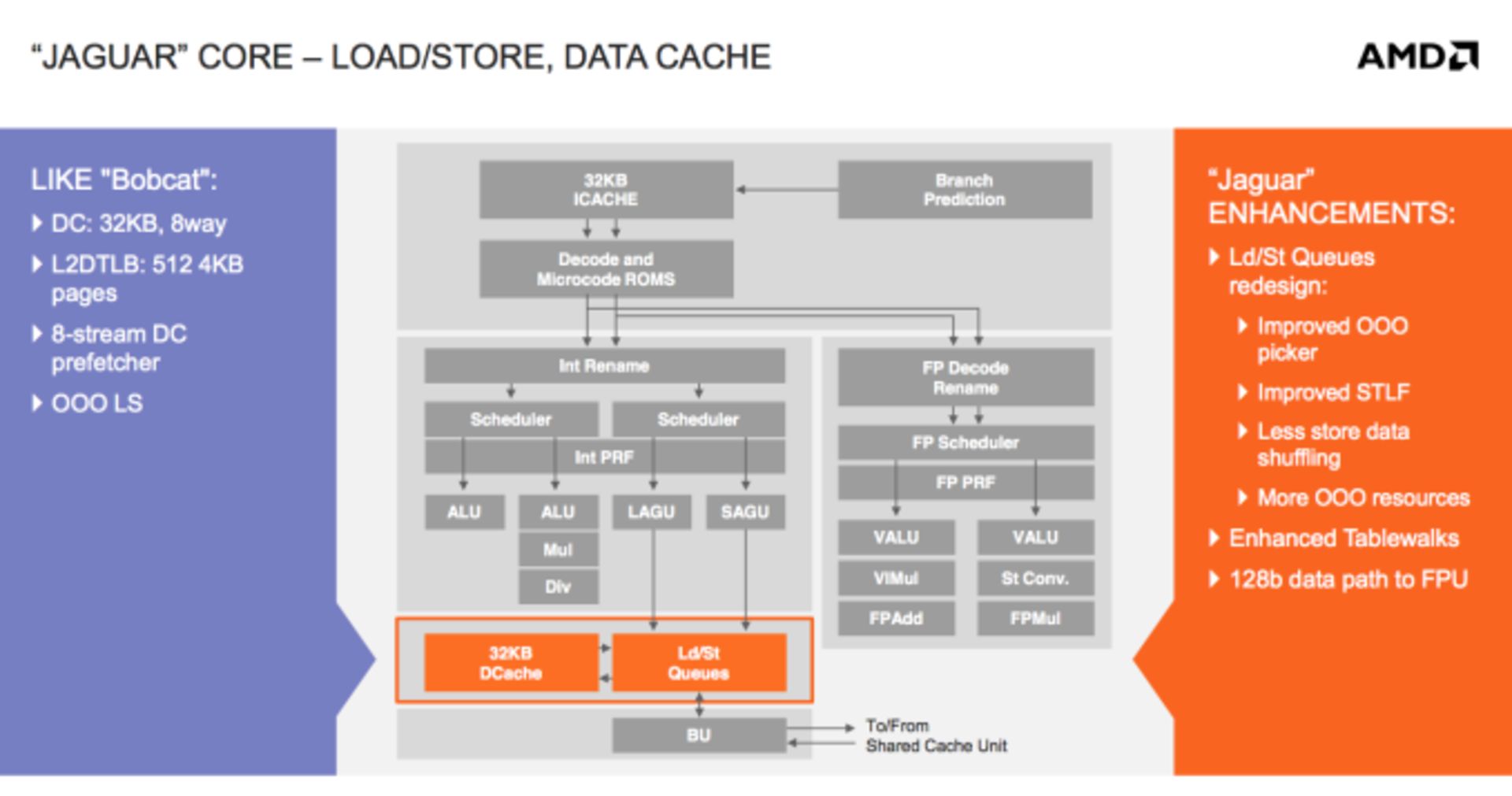
ایامدی مدعی است که عملکرد جگوار از نظر تعداد دستوراتی که در یک کلاک اجرا میشوند، ۱۵ درصد بهینهتر شده است. علت اصلی استفاده از واحد ذخیرهسازی و بارگذاری خارج از نوبت جدیدی است که از مدتها پیش مشخص بود جای بهینهسازی زیادی دارد. این دومین نسل واحد ذخیرهسازی و بارگذاری خارج از نوبتی است که ایامدی معرفی کرده و نتیجهی خوبی هم داشته است.
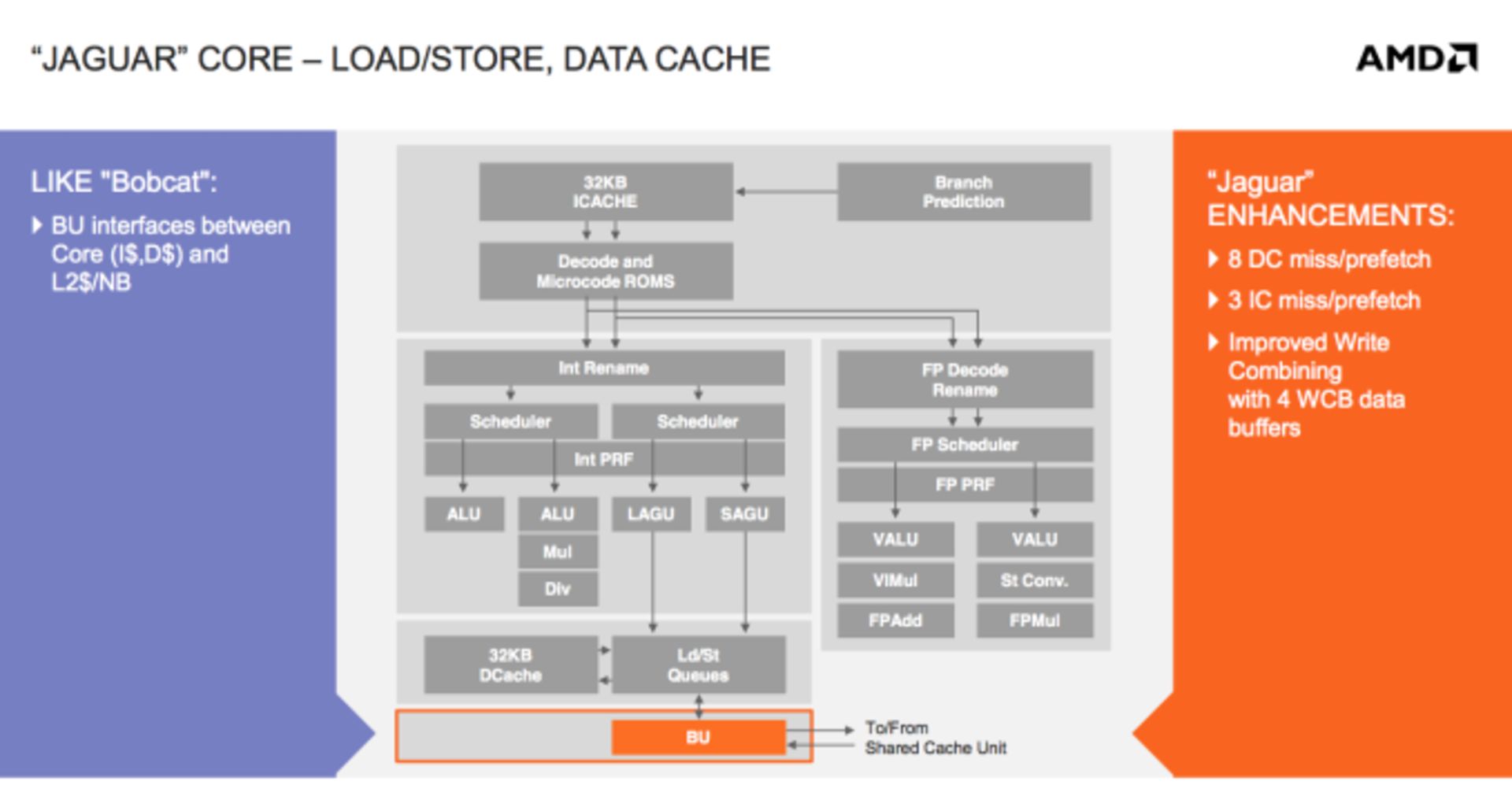
واحد محاسبه
بابکت ساختار چندهستهای سادهای دارد. هر یک از هستهها، کش ۵۱۲ سطح دوم مختص به خود را دارند و تمام ارتباطات بین هستهای ازطریق باس روی هر هسته اتفاق میافتد. ساختار کش مثل معماریهای قبلی ایامدی، انحصاری است.
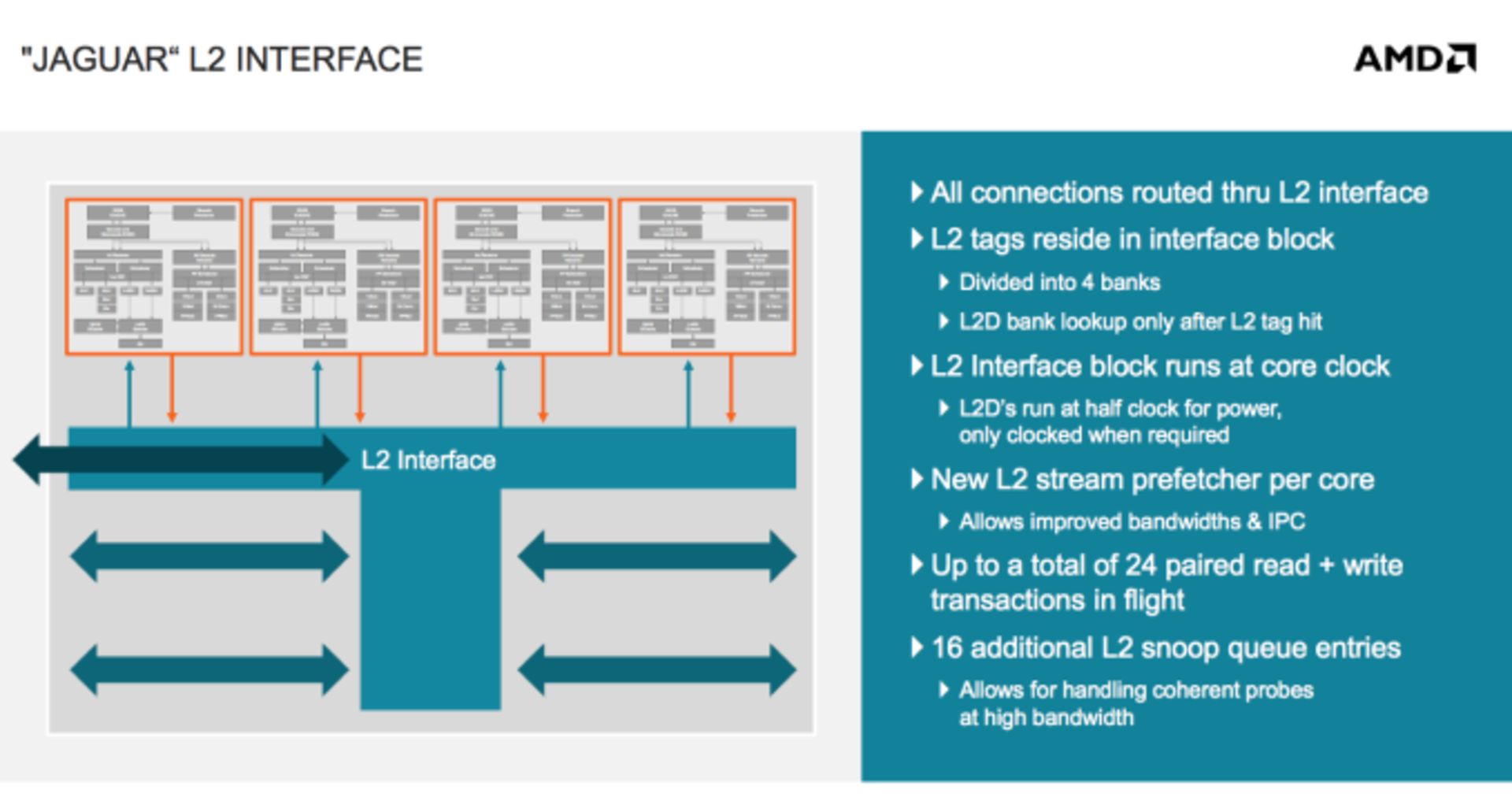
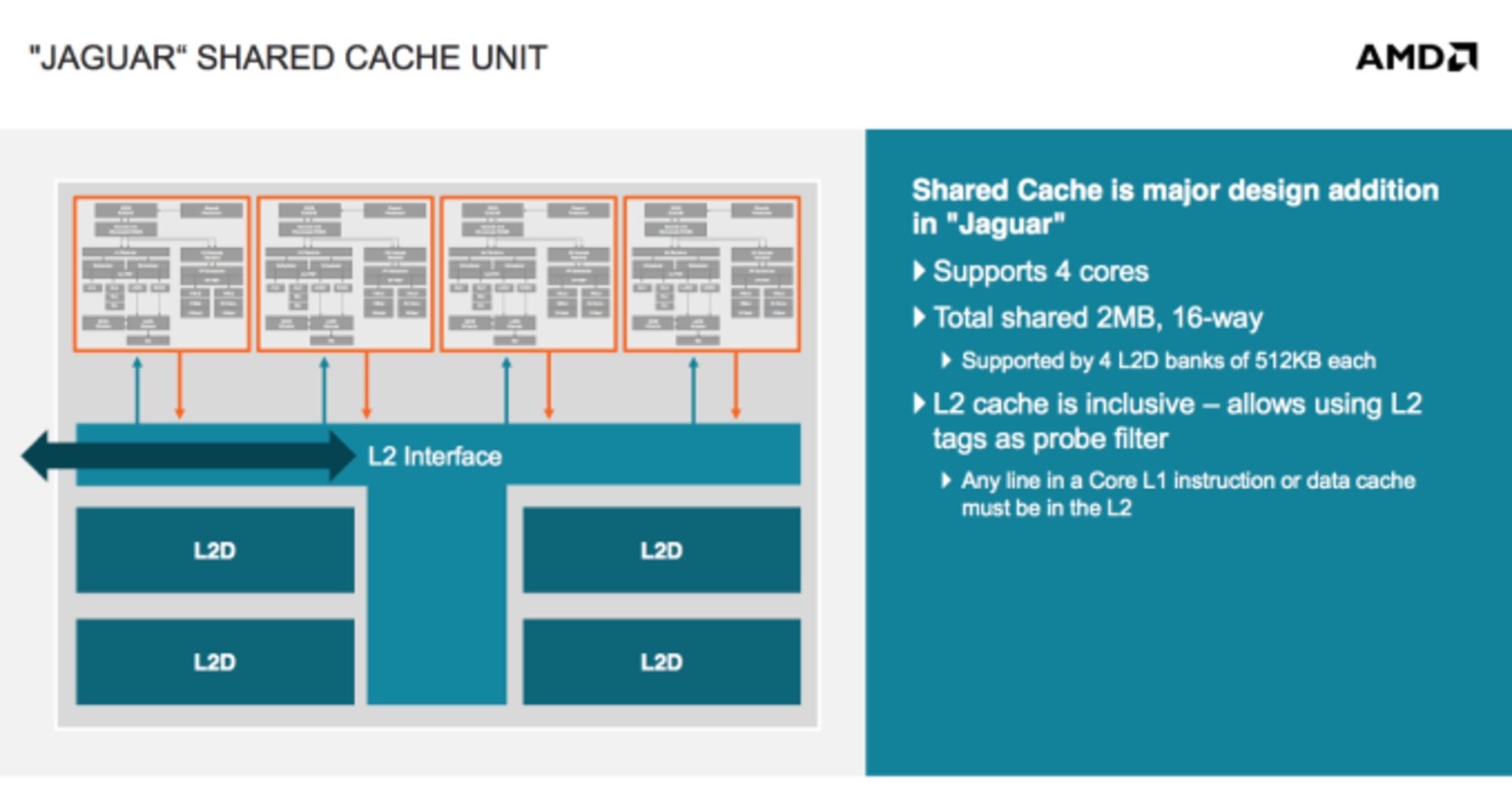
در جگوار همهچیز دگرگون شده است. ایامدی یک واحد محاسباتی جگوار را با نهایتاً ۴ هسته تعریف کرده که یک کش بزرگ و مشترک بینشان وجود دارد. کش L2 نهایتاً میتواند ۲ مگابایت و ۱۶ جهتی باشد. این کش اولین کش غیرانحصاری یا به عبارت بهتر اشتراکی در تاریخ معماریهای این کمپانی است.
در گذشته ایامدی همیشه از کش انحصاری استفاده میکرد، کپی کردن اطلاعات کش L1 در کش L2 هم تأثیر زیادی نداشت چراکه L2 هم یک کش انحصاری و مختص به هستههای خاص بود.
اما تأثیر کش اشتراکی که ایامدی برای اولین بار استفاده کرده چه قدر است؟ تعداد دستورها اجرا شده در یک سیکل بین ۵ تا ۷ درصد بیشتر از بابکت خواهد بود.
بنابراین تا به اینجای کار، نتیجهی استفاده از کش اشتراکی و واحد ذخیرهسازی و بارگذاری خارج از نوبت نسل دوم، ۲۲ درصد سرعت بیشتر است.
اما در کاربردهای چند تردی چه اتفاقی میافتد؟ منظور از چند تردی، پردازشهایی است که به صورت موازی توسط هستههای مختلف اجرا میشوند. معماری جدید کش در جگوار و ارتباط بین هستهای با تأخیر کمتر، در کاربردهای چند تردی به مراتب مؤثرتر واقع میشود و لذا به نتیجهی عالی زیر میرسیم:
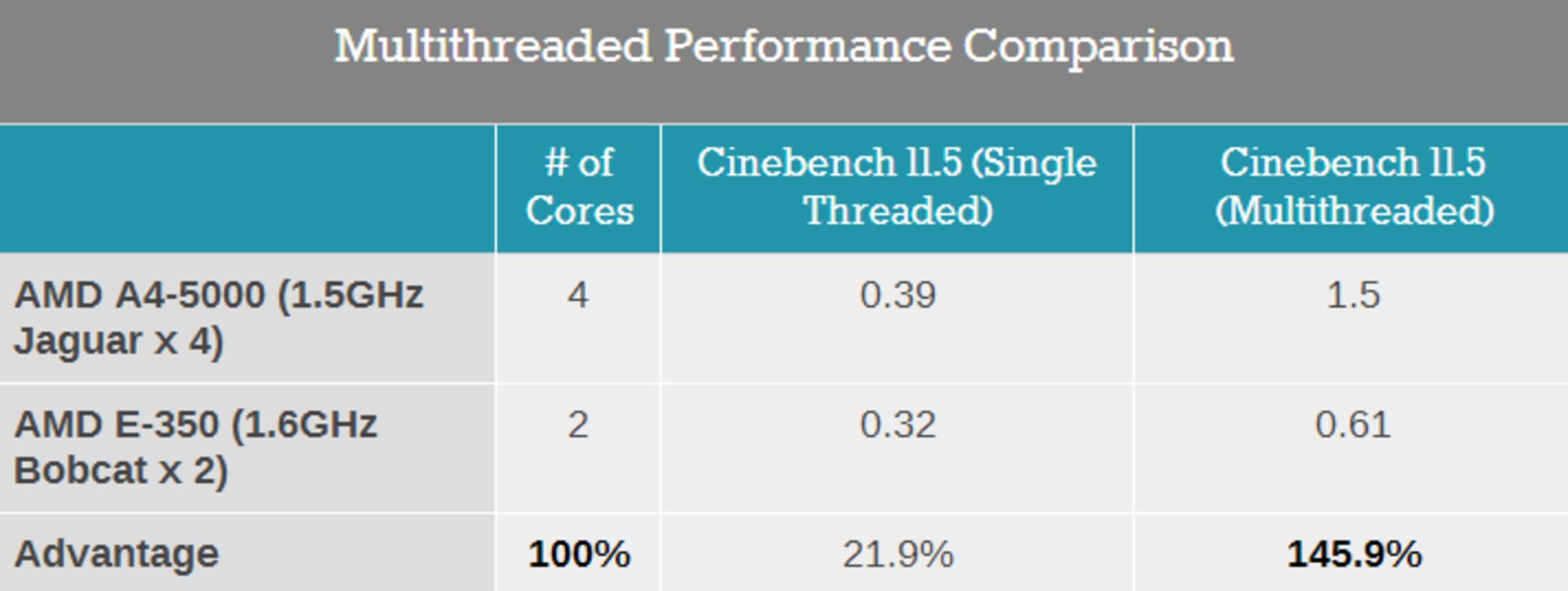
در کاربرد تک تردی یا به عبارتی در مقایسهی یک هسته، سرعت پردازش ۲۱ درصد بیشتر شده ، حتی با اینکه سرعت کلاک از ۱.۶ به ۱.۵ گیگاهرتز تقلیل یافته است. اما در کاربردهای چند هستهای، سرعت پردازش حدوداً ۲.۵ برابر شده که نشان از عملکرد بهتر دارد.
کش L1 همان مقدار ۳۲ کیلوبایت قبلی است و تغییر نداشته است.
چیدمان فیزیکی و ترکیب پردازنده
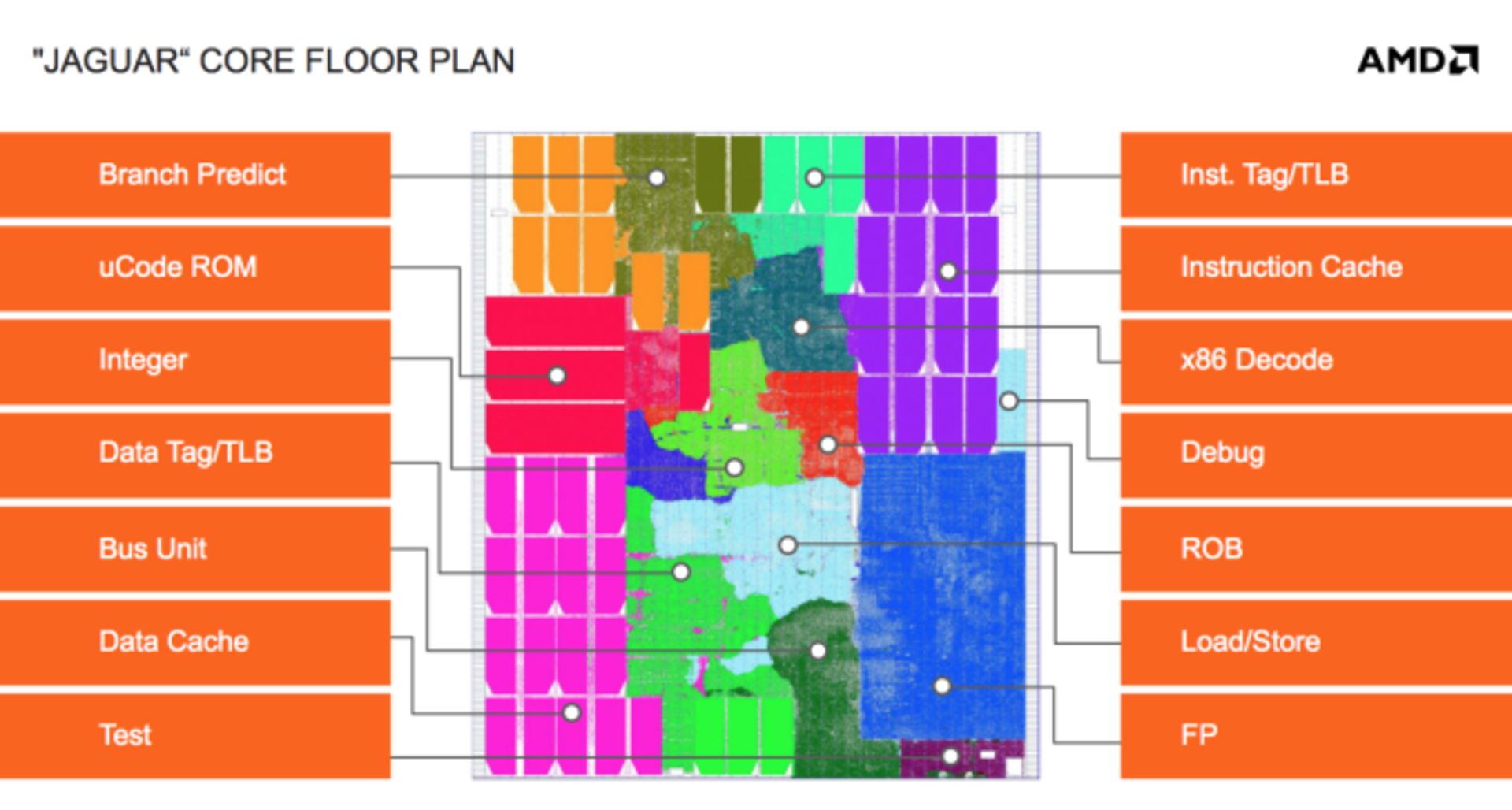
بابکت اولین هستهی پردازندهای است که ایامدی بهراحتی تولید کرده و این موضوع نتیجهی خرید کمپانی ATI است. ایامدی در جگوار بازهم موفقتر ظاهر شده و تعداد مایکروهای یکتایی که در طراحی لازم است را کاهش داده و لذا تراشه بهشدت ساده شده است. منظور از مایکرو طبقات و بخشهای مختلفی است که با رنگهای متفاوت در تصویر فوق نشان داده شده است.
حالا ایامدی میتواند جگوار را بین کارخانههای مختلف جابهجا کند. البته استفاده از مایکروهای عمومی، مساحت را افزایش میدهد اما در عوض تولید مایکروها سادهتر میشود. در نهایت مساحت یک هستهی ۲۸ نانومتری جگوار تنها ۳.۱ میلیمتر مربع است درحالیکه یک هستهی بابکت که لیتوگرافی ۴۰ نانومتری داشت، ۴.۹ میلیمتر مربعی بود.
با توجه به تصویر زیر پیچیدگی بیشتر بابکت نسبت به جگوار کاملاً مشهود است:
کبینی (Kabini)، تراشهای برای دنیای نوتبوکها
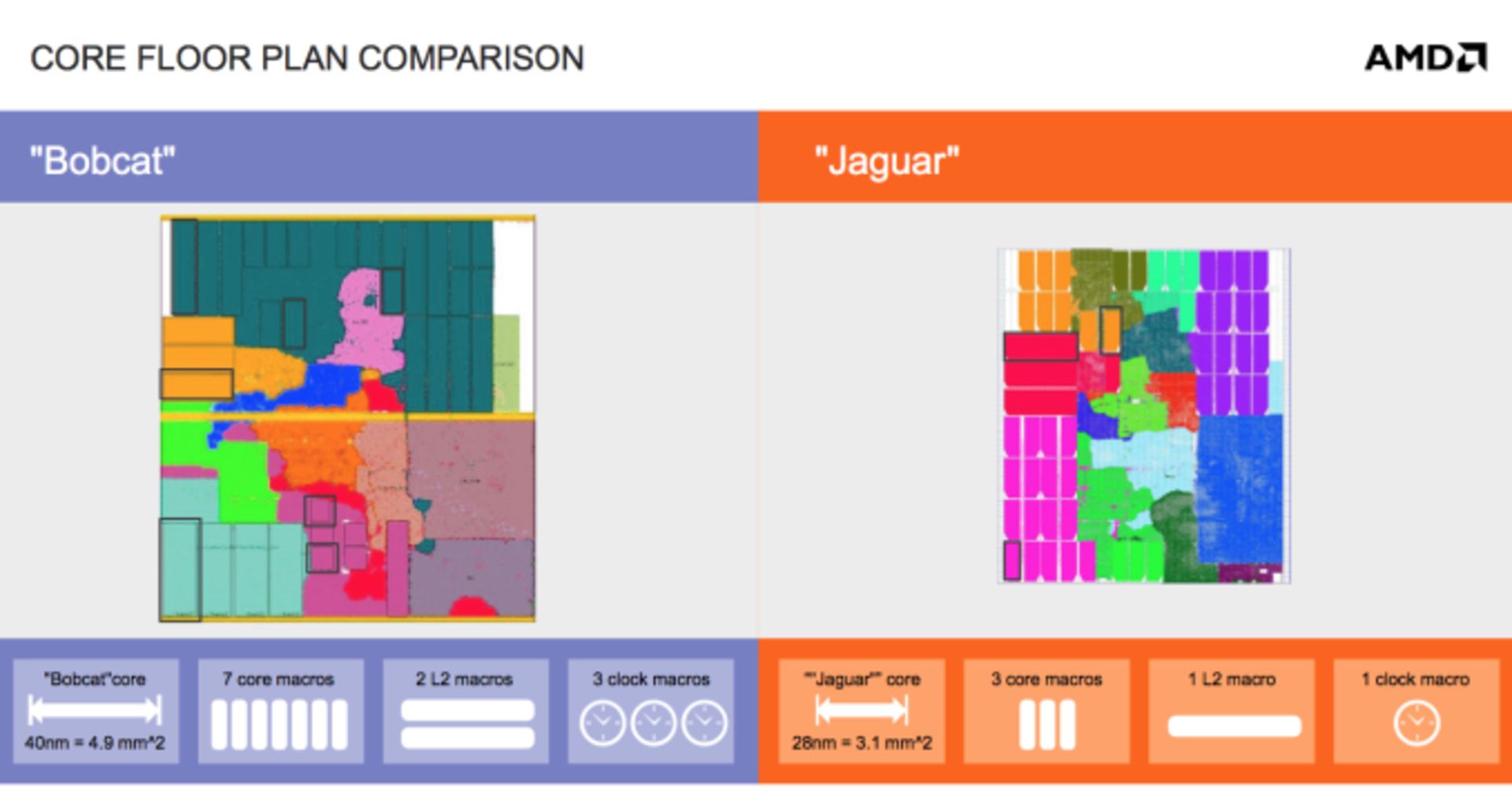
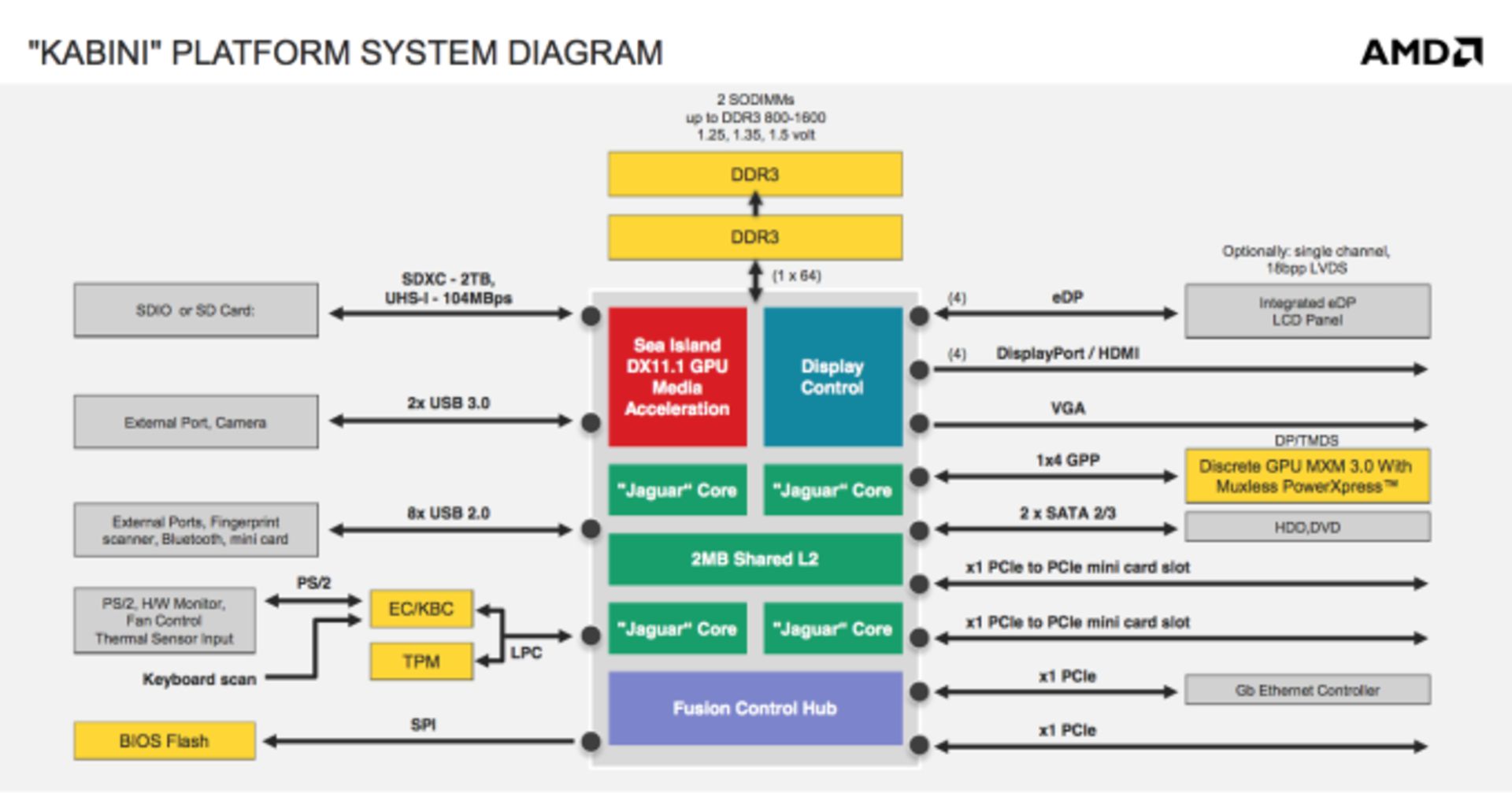
ایامدی قرار است دو نوع ایپییو براساس هستههای جگوار تولید کند. کَبینی و تِسمش. اگر با مفهوم APU و تفاوت آن با CPU و GPU آشنایی ندارید، به مقالهی اختصاصی زومیت سری بزنید. کبینی بهزودی در نوتبوکهای نسبتاً ارزان و البته بسیار باریک مورد استفاده قرار خواهد گرفت. اگر به تعریف APU نگاهی داشته باشیم، متوجه میشویم که تسمش و کبینی هیچ کدام یک ایپییو نیستند چراکه اجزای موجود آنها را در تعریف SoC یا سیستم روی چیپ قرار میدهد. هاب I/O در قالب یکپارچهی این تراشهها به کار رفته است و لذا بهتر است بگوییم:
کبینی اولین سیستم روی چیپ ۴ هستهای X86 است.
کبینی در دو سری با پیشوند A و E عرضه میشود، نسخههایی با پیشوند A دارای ۴ هسته و سری E دارای ۲ هستهی جگوار هستند. لیست کبینیهای فعلی به صورت زیر است:
اما به پردازندهی گرافیکی مجتمع بپردازیم، از ۲ واحد محاسباتی با معماری Graphics Core Next یا GCN استفاده میشود. موتور هندسی خاصی با توان پردازش ۴/۱ دستورها اولیه در هر کلاک مورد استفاده قرار گرفته تا تولید چنین پردازندههای کوچک و کممصرفی امکانپذیر شود. انجام محاسبات با دقت مضاعف با نرخ ۱۶/۱ پشتیبانی شده گرچه در زمان اجرا با دقت عادی و نرخ ۸/۱ مشکلاتی به چشم میخورد.
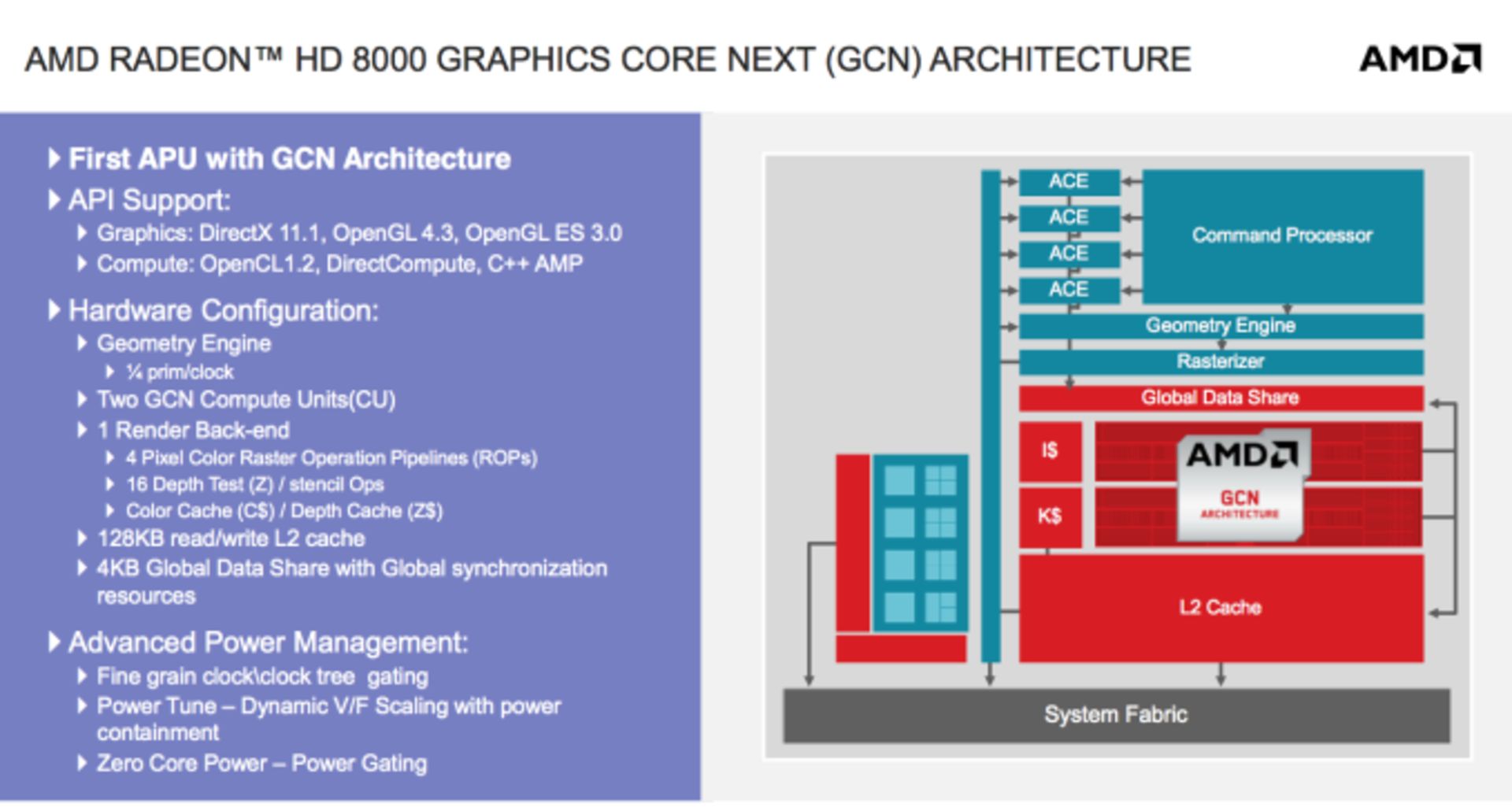

کنترلر مموری ۶۴ بیتی DDR3 در کبینیها به کار رفته و توان مصرفی مدلهای مختلف بین ۹ تا ۲۵ وات است. با اینکه جگوار از فرکانس کاری پویا (Dynamic) پشتیبانی میکند، این قابلیت یعتی Turbo Mode را در کبینیها نمیبینیم. تمام سرعتهای مذکور، بیشترین سرعت هستهها هستند و به بار پردازشی وابسته نمیباشند.
تمش (Temash) یک پردازندهی معمولی برای تبلتها

تسمشها توان مصرفی کمتری دارند و بین ۳.۹ تا ۹ وات انرژی مصرف میکنند. مدل ۴ هستهای A6-1450 دارای توربو کور است و فرکانس هستههای آن دائماً در حال تغییر است. یکی از ویژگیهای جالب توربو کور در این تراشه، اشتراک توان مصرفی بین پردازندهی اصلی و گرافیکی است. به این معنی که اگر پردازنده کمبار باشد، توان دردسترس را دراختیار پردازندهی گرافیکی قرار میدهد و پردازندهی گرافیکی همچنین قابلیتی دارد.
مدل A4-1200 هم توان مصرفی جالب دارد، کمتر از ۴ وات که برای تولید تبلتهایی مثل آیپد مناسب است. ایامدی در هیچ کدام از مدلهای معرفی شده، تعداد هستههای گرافیکی را کاهش نداده و تنها فرکانس کاری را تغییر داده است.
ایکسباکس وان و پلی استیشن ۴
در هر دو کنسول نسل بعدی مایکروسافت و سونی، از پردازندهها و به عبارت دقیقتر سیستم روی چیپهایی مبتنی بر جگوار استفاده شده است. در هر دو کنسول دو واحد ۴ هستهای جگوار دیده میشود. کش مشترک L2 در هر واحد ۲ مگابایت است. ارتباط بین دو واحد ۴ هستهای در حد ایدئال نیست و لذا سازندگان بازی سعی میکنند بار پردازشی روی یکی از واحدهای ۴ هستهای باشد.
با نگاهی به کبینی محدودهی فرکانس کاری جگوارهای ۲۸ نانومتری مشخص میشود: ۱ تا ۲ گیگاهرتز. اما همیشه یک نقطهی بهینه برای رسیدن به بالاترین بازدهی وجود دارد که در مورد جگوار فرکانس ۱.۶ گیگاهرتز است. با افزایش ۲۵ درصدی فرکانس یعنی رسیدن به سرعت ۲ گیگاهرتز، مصرف انرژی ۶۶ درصد افزایش مییابد که نشان میدهد فرکانس ۲ گیگاهرتز به هیچ وجه بازده بهتری ندارد.
تفاوت بین کبینی و تسمش با پردازندهای که در کنسولهای موردبحث به کار رفته تنها در آدرسدهی یکپارچهی حافظه و وابستگیهای خاصی است که در معماری این دو کنسول میبینیم. قطعاً باس حافظه هم بسیار متفاوت است اما هستههای جگوار دقیقاً یکی هستند.
نتیجهگیری نهایی
همانطورکه گفتیم ایامدی مدعی است که یک هستهی جگوار از نظر کارایی با سرعت کلاک مساوی، ۲۲ درصد سریعتر از بابکت است. بابکت دروازهی ورود به وسایل همراه بوده و در حال حاضر در بیش از ۵۰ میلیون دستگاه مشغول کار است. مصرف انرژی جگوار نیز با استفاده از لیتوگرافی ۲۸ نانومتری و سایر بهینهسازیها، به مراتب بهتر از بابکت است. بنابراین انتظار داریم که تسمش در ورود به دنیای تبلتها موفقتر از دو برزویی که در سالهای قبل رونمایی شدند، ظاهر شود.
البته جگوار نقاط ضعفی هم دارد که نشان میدهد سازنده در رونمایی و عرضهی آن کمی عجله داشته است که با توجه به اوضاع بازار، بیمورد هم نیست. بزرگترین اشکال جگوار در توربو کور نسبتاً ضعیف است. چیزی که در اجرای پردازشهای تکهستهای معجزه میکند. قابلیت کنترل و مانیتور دما و توان مصرفی هم از نقاط ضعف جگوار است که در آینده پیشرفت خواهد کرد.
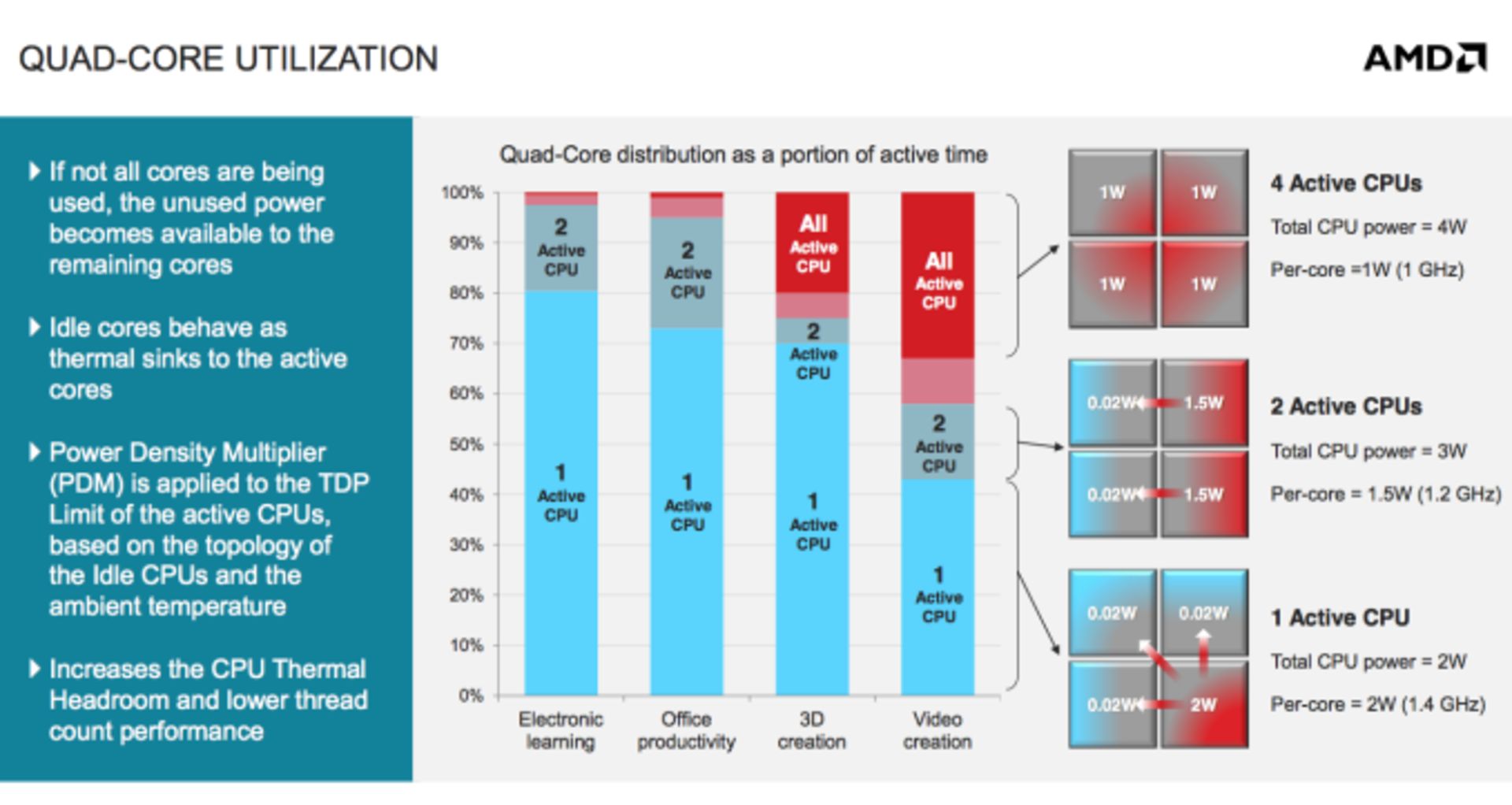
در مجموع وضعیت جگوار بسیار خوب به نظر میرسد. توان مصرفی هستههای جگوار در بار پردازشی سبک به کمتر از ۲ وات کاهش مییابد. سایر بخشهای یک تبلت، این توان را به رقم ۴ تا ۷ وات میرسانند. به نمودار زیر توجه کنید:
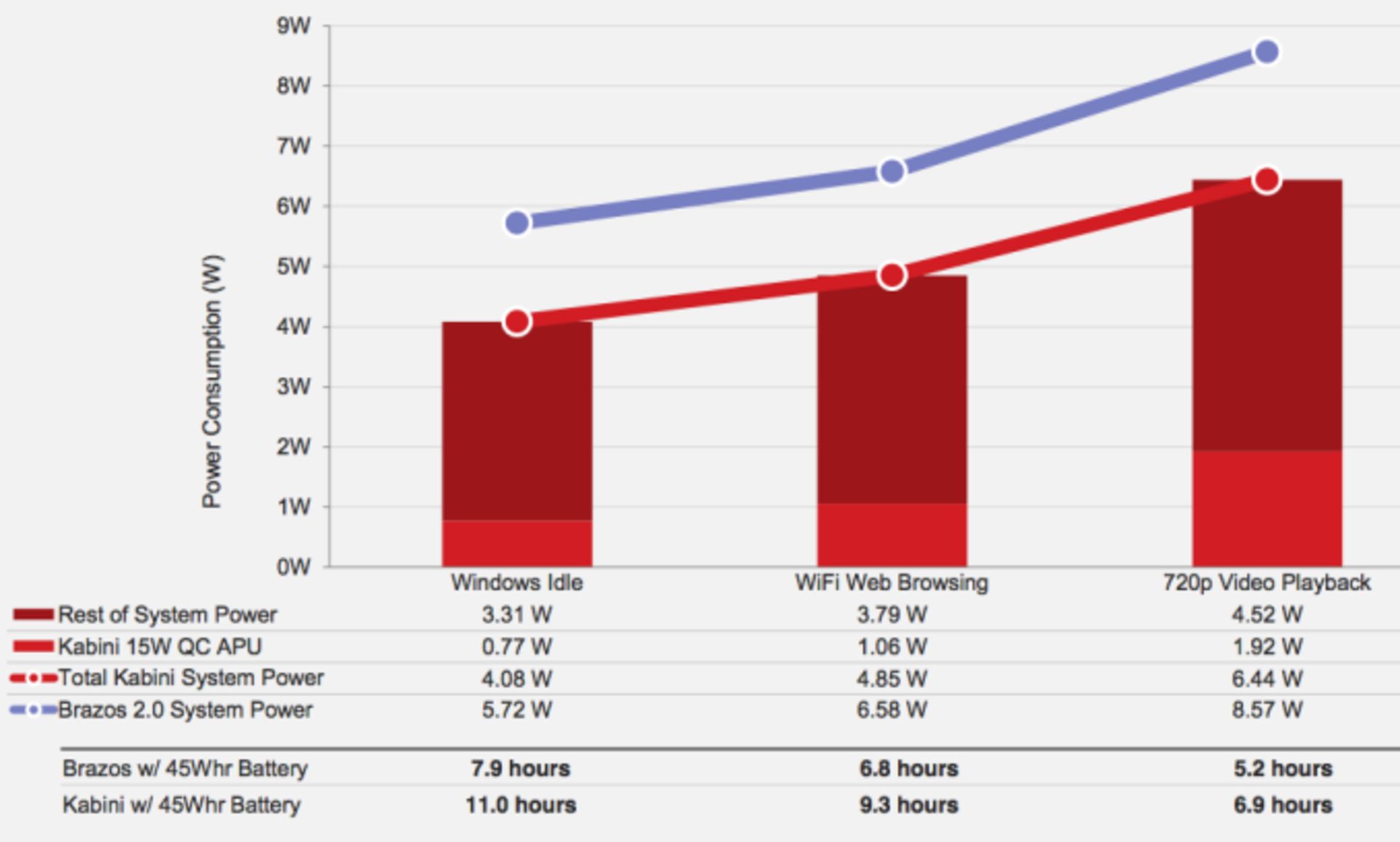
توان مصرفی پلتفرم کبینی با ۴ هسته، در حالت بیکار ۰.۷۷ وات است و در مجموع کلی سیستم حدود ۴ وات مصرف میکند. همین رقم در مورد بروزی ۲.۰، حدود ۶ وات بود. جالب است که با استفاده از یک باتری ۴۵ واتساعتی که در نوتبوکهای امروزی مرسوم است، میتوان حدود ۷ ساعت از سیستم برای پخش ویدیوی استفاده کرد.
در این محدودهی قیمتی، فعلاً رقیبی برای جگوار وجود ندارد. اتمهای فعلی ۳۲ نانومتری اینتل که از هستههای سالتوِل (Saltwell) استفاده میکنند، کمی قدیمی شدهاند و ARM هم چیزی در این حد سریع ارایه نکرده است. بنابراین منطقی است که مایکروسافت و سونی در تصمیمی مشابه سراغ تراشهای ۸ هستهای با هستههای جگوار بروند.
تا چند ماه بعد که اینتل معماری سیلورمونت خود با لیتوگرافی ۲۲ نانومتری را روانهی بازار کند، ایامدی با خیال راحت مشغول فروش محصولات خود خواهد بود و از موقعیتی که در چند سال اخیر کمتر به آن رسیده لذت میبرد، منظورمان برتری در کارایی CPU است.