لایفوب از دو مدل زبانی رونمایی کرد؛ مدل «تهران» و «شیراز» گامی بلند در پردازش زبان فارسی
تیم هوش مصنوعی شرکت دانشبنیان لایفوب پس از ۶ ماه تلاش موفق به توسعه مدلهای جدید برای پردازش زبان فارسی شده است. این نخستین بار است که یک مدل زبانی براساس دادههای زبان فارسی با تنوع موضوعی و پلتفرمی بهصورت کلان انجام شده و اکنون در راستای مسئولیت اجتماعی در اختیار پژوهشگران و فعالان حوزه هوش مصنوعی قرار میگیرد. «تهران» و «شیراز» نام این مدلهای زبانی است.
شرکت لایفوب در سالهای گذشته برای بومیسازی سرویسهای تحلیل متن مبتنی بر هوشمصنوعی فعالیتهای گستردهای داشته است و با در نظر گرفتن ساختار زبان رسمی فارسی و ادبیات محاورهای کاربران فارسیزبان شبکههای اجتماعی، سرویسهای مختلف مانند تحلیل عواطف و احساسات متون، تشخیص موجودیتهای نامدار و ... را ارائه داده است.
مدل تهران بر افزایش دقت و مدل شیراز بر بهبود سرعت پاسخدهی متمرکز است
مدلهای زبانی توسعه دادهشده در لایفوب، تهران و شیراز نامگذاری شدهاند. مدل تهران بر افزایش دقت و مدل شیراز بر بهبود سرعت پاسخدهی در شرایط محدودیت منابع سختافزاری متمرکز هستند. یکی از نکات مهم این مدل نزدیکی بسیار بالای آن به زبان روزمره مردم در شبکههای اجتماعی است. که باعث میشود خروجیهای آن شفافتر و دقیقتر باشد.
لایفوب بهصورت پیوسته تلاش میکند تا با دادههای انبوه و استاندارد و بهینهسازی مدلهای زبانی، ماشینها را آموزش دهد تا دقیقترین خروجی ممکن را در سامانههای خود به مخاطبان ارائه کند. در همین راستا متخصصان هوش مصنوعی شرکت لایفوب در اواسط سال ۱۴۰۲ با تمرکز بر زبان فارسی توسعه مدل زبانی را آغاز کردند که در اسفند ۱۴۰۲ منتشر شد و در دو مدل در دسترس عموم قرار گرفت. دسترسی به مدلهای زبانی تهران و شیراز در وبسایت لایفوب امکانپذیر است.
برای توسعه این مدل زبانی، ابتدا تیم داده شرکت لایفوب مجموعهای از دادههای متنوع و با حجم بالا جمعآوری و سپس تیم هوش مصنوعی این دیتاست (Dataset) را نرمالسازی کرد و درنهایت مسیر توسعه مدل زبانی آغاز شد.
این مجموعه داده، برآمده از بسترهای مختلف مانند سایتهای خبری، گروهها و کانالهای تلگرامی، پستهای سایتهای پرطرفدار ورزشی، حقوقی، تاریخی، تکنولوژی و... است، که با نام «دیوان» منتشر خواهد شد.
مدل تهران
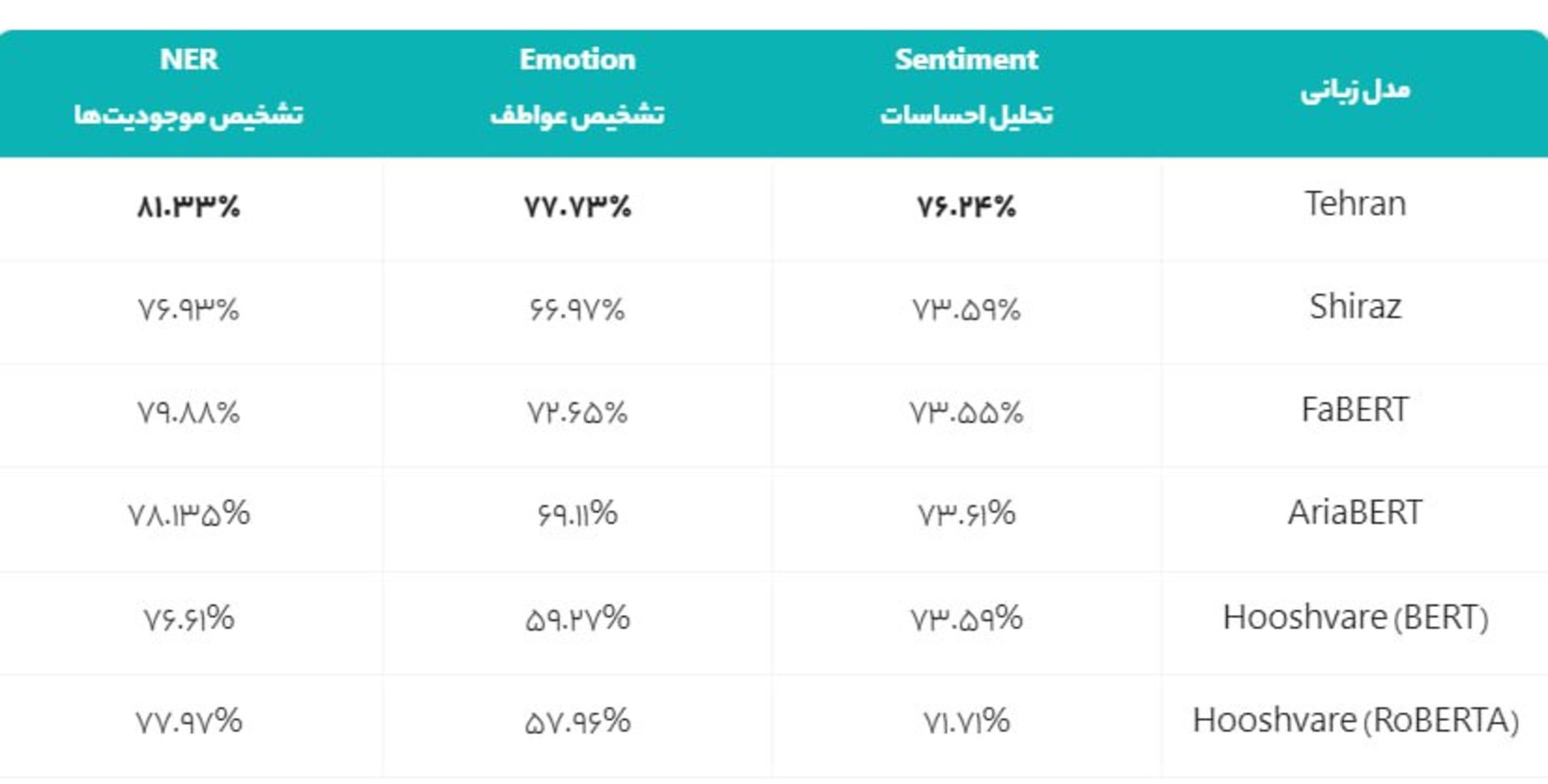
مدل زبانی تهران بر پایه معماری RoBERTA آموزش داده شده و شامل بیش از ۱۲۳ میلیون پارامتر است که بهترین نتایج را در مقایسههای انجامشده نسبت به سایر مدلهای زبانی فارسی گزارش کرده است. این مدل برای توسعه سرویسهای مختلف و استفاده غیررایگان به سایر سازمانها ارائه میشود.
مدل شیراز
مدل شیراز هم بر پایه معماری Mobile BERT آموزش داده شده و بیش از ۲۵ میلیون پارامتر را در برمیگیرد که با سرعت پاسخدهی بیش از ۵۰۰ درصدی نسبت به سایر مدلهای زبانی فارسی بهصورت کاملا متنباز و رایگان در اختیار عموم جامعه فارسیزبان قرار گرفته است. طبق توضیحات لایفوب، این افزایش سرعت چشمگیر بدون فدا کردن دقت قابلتوجه انجام شده است.
ویژگیهای مدل زبانی جدید شرکت لایفوب
این دو مدل زبانی علاقهمندان این حوزه را از آموزش مدلهای فارسی از پایه بینیاز کرده و در بهبود و تدوین مدلهای تحلیل متن کمککننده است.
ویژگیهای مدلهای زبانی تهران و شیراز:
- تنوع و جامعیت موضوعی و لحن دیتاست
- آموزش بر روی ۱۱ میلیارد توکن (کلمه) فارسی
- بالاترین دقت در میان مدلهای موجود زبان فارسی (مدل تهران)
- بالاترین سرعت با حفظ دقت رقابتی در میان مدلهای زبان فارسی موجود (مدل شیراز)
مدل زبانی چیست؟
مدل زبانی ابزار زیربنایی مورد نیاز برای درک و پردازش زبان در سرویسهای هوش مصنوعی است. با استفاده از مدلهای زبانی انواع مختلفی از سرویسها شامل خوشهبندی، خلاصهسازی، پیشبینی کلمات و جملات، دستهبندی، جستوجوی معنایی، استخراج کلمات کلیدی و … قابل ارائه خواهد بود که بهعنوان نمونه سرویس تشخیص احساسات و یا تشخیص عواطف نمونههای عینی و کاربردی استفاده از مدلهای زبانی در لایفوب است.
سرویس تشخیص احساسات و یا تشخیص عواطف نمونههای عینی و کاربردی استفاده از مدلهای زبانی است
اولین مدل زبانی توسط شرکت گوگل در سال 2018 با نام BERT معرفی شد که پایه تدوین مدلهای زبانی بعدی قرار گرفت.
در زبان فارسی اولین مدل زبانی بر پایه BERT در سال ۲۰۲۰ ارائه شد و با نام ParsBERT در دسترس عموم قرار داده شد. آخرین مدل فارسی هم با نام AriaBERT در زمستان 2023 منتشر شد که مطابق بنچمارک منتشرشده بالاترین دقت را در میان مدلهای فارسی زبان دارد. هماکنون مدل تهران با معماری RoBERTa توانسته است AriaBERT را با دقتهایی تا ۷درصد بالاتر پشت سر بگذارد که نشاندهنده تنظیم دقیق پارامترها و کیفیت دیتاست مورداستفاده در فاز آموزش است.
نظرات