الگوریتم هوش مصنوعی؛ یک قدم بزرگ به سمت شبیهسازی کامل مغز
مغز انسان پیچیدهترین مکانیزم زنده است و حتی تعدادی از دانشمندان بر این باور هستند که دانش ما در مقایسه با ناشناختههای مغزمان بسیار اندک است. دانشمندان سالها است تلاش میکنند هوشی مصنوعی طراحی کنند که از هوش انسان قدرتمندتر باشد. اکنون این رؤیا تا حدودی به واقعیت تبدیل شده است و هوشهای مصنوعی بسیاری ساخته شدهاند که قابلیت شبیهسازی ذهن انسان را تا حد بالایی دارند و میتوانند محاسباتی انجام دهند که از توانایی انسان خارج است.

فیزیکدان معروف، دکتر ریچارد فاینمَن، میگوید:
چیزی را که نمیتوانم ایجاد کنم، نمیتوانم درک کنم. یاد بگیرید چگونه مسائل حلشده را خودتان حل کنید.
یک زیررشتهی قدرتمند و رو به افزایش از علوم اعصاب بر پایه و مبنای سخنان دکتر فاینمن ایجاد شده است. در تئوری دانشمندان علوم اعصاب، کلید درک این که هوش چگونه کار میکند این است که آن را در یک کامپیوتر از نو بسازیم. نورون به نورون. این روش دانشمندان را به بازسازی فرایندهای عصبی که منجر به تفکر، خاطره یا احساس میشود امیدوار میکند.
با مغز دیجیتال دانشمندان میتوانند تئوریهای معاصرِ مربوط به ادراک را تست کنند یا در پارامترهایی که منجر به عملکرد بد ذهن میشوند کاوش کنند. همانطور که نیک بوستروم، (فیلسوفی از دانشگاه اکسفورد) اثبات کرد، شبیهسازی ذهن بشر اگرچه پرزحمت است؛ اما میتواند یکی از نویدبخشترین روشهای بازسازی و حتی جلو افتادن از نبوغ بشری باشد.
مشکل این است که کامپیوترهای امروزی نمیتوانند ماهیت موازی و پیچیدهی مغز ما را مدیریت کنند. مغز انسان ۱۰۰ میلیارد نورون دارد که از طریق تریلیونها اتصال (سیناپس) با هم ارتباط برقرار میکنند. لایه بیرونی مغز (کورتِکس) وظیفه تشخیص بصری را بر عهده دارد و بخشهای دیگر عملکردهای محرک را کنترل میکنند.
حتی امروزه قدرتمندترین ابررایانهها هم برای این مقیاس بزرگ از مغز انسان پاسخگو نیستند
تاکنون ماشینهایی نظیر کامپیوتر K در مؤسسهی پیشرفتهی علوم محاسباتی در کوبه ژاپن میتواند عملکرد حداکثر ۱۰ درصد از نورونها و سیناپسهای بخش کورتکس را بر عهده بگیرد. این ناکارآمدی تا حدودی ناشی از نرمافزار است.
اما همینطور که سختافزارهای محاسباتی همواره به سرعتهای بالاتری دست مییابند، الگوریتمها نیز بهصورت افزایشی به محور اصلی شبیهسازی مجموعهی مغز تبدیل میشوند.
در ماه جاری میلادی، یک گروه بینالمللی، ساختار یک الگوریتم شبیهسازی محبوب را بهطور کامل بهروز کرد و تکنولوژی قدرتمندی را گسترش داد که بهصورت مهیجی زمان محاسبات و حافظهی مورد استفاده را کاهش میدهد.
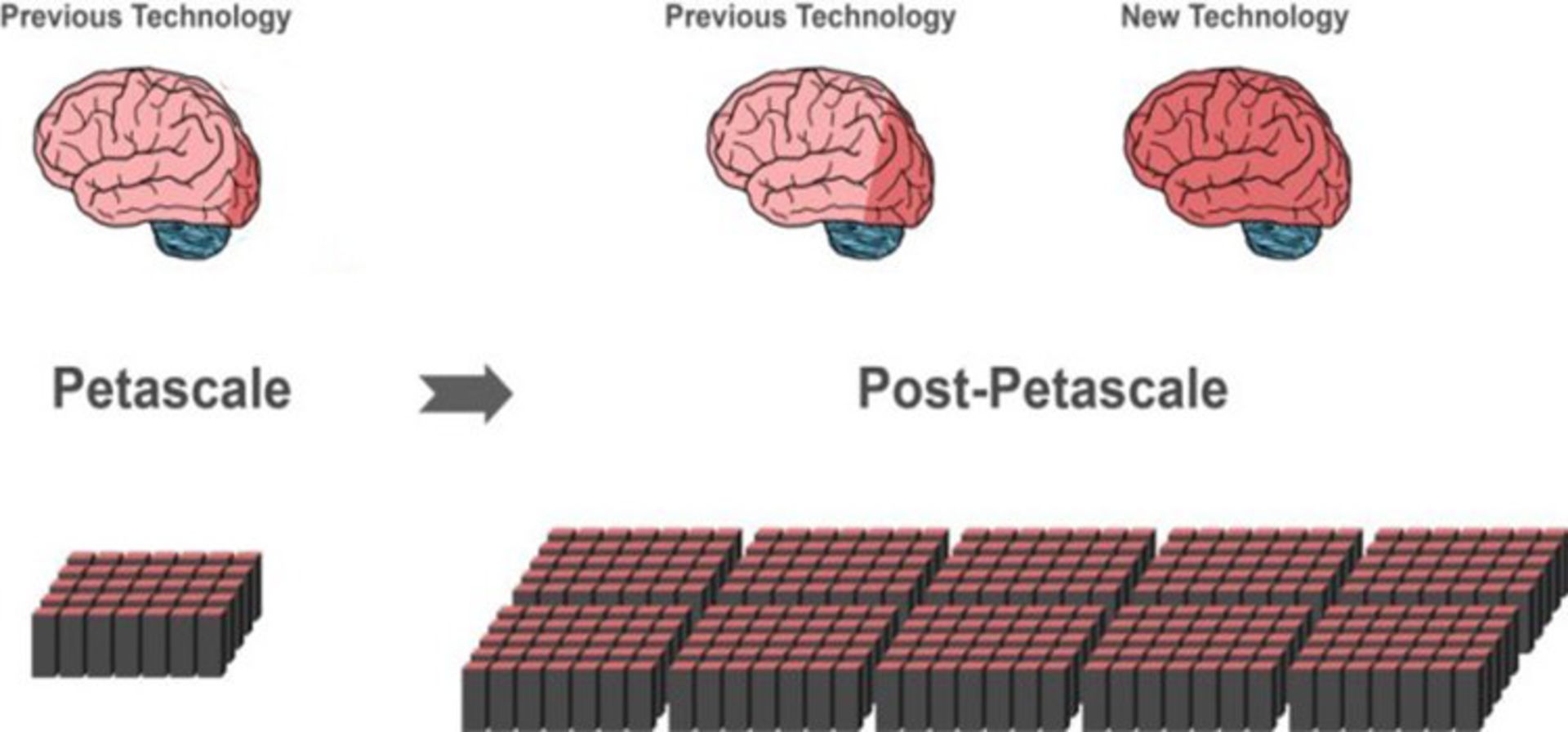
در علوم محاسباتی، Petascale ابررایانهای است که توان محاسباتی در مقیاس پتافلاپس ( معادل ۱۰۱۵ فلاپس) دارد. Petascale برای انجام محاسبات پیشرفته در زمینههای شبیهسازی مغز، شبیهسازی اتم و هسته و سایر موارد اینچنینی به کار میرود. با استفاده از الگوریتمهای شبیهسازی حال حاضر، نسل بعدی ابررایانهها تنها پیشرویهای کوچک (نواحی قرمز تیره در مغز مرکزی) در این زمینه ممکن خواهد بود؛ با این حال تکنولوژی جدید، محققان را قادر میسازد بخش بزرگتری از مغز را با استفاده از همان میزان حافظهی قبلی شبیهسازی کنند.
همین موضوع باعث میشود تکنولوژی جدید در استفادهی آیندهی ابررایانهها برای شبیهسازی در سطح کل مغز مناسب باشد. الگوریتم جدید با مجموعهای از سختافزارهای محاسباتی، از لپتاپ گرفته تا ابررایانهها، سازگار است. زمانی که ابررایانههای Exascale ( به گونهای برنامهریزی شدهاند که ۱۰ تا ۱۰۰ برابر قدرتمندتر از عملکنندههای امروزی باشند) در آینده به نمایش دربیایند، این الگوریتم میتواند روی این غولهای محاسباتی بهسرعت اجرا شود.
نویسندهی محقق ژاکوب جردن که در مرکز تحقیقاتی یولیش آلمان مقالات Frontiers in Neuroinformatics (مرزهای عصبشناسی) را راهاندازی کرد، در اینباره میگوید:
با تکنولوژی جدید، امروزه خیلی بهتر از گذشته میتوانیم در افزایش موازی ریزپردازندههای مدرن که در آینده اهمیت بیشتری در ابررایانههای Exascale پیدا خواهند کرد، کاوش کنیم. این یک گام قطعی در راستای خلق تکنولوژیِ دستیابی به شبیهسازی شبکهها در مقیاس مغز است.
مشکل مقیاس
ابررایانههای فعلی از صدها هزار زیردامنه به نام گره تشکیل شدهاند. هر گره متشکل از چندین مرکز پردازشی است که میتواند تعداد انگشتشماری از نورونهای مجازی و اتصالات بین آنها را پشتیبانی کند.
مسئله اصلی در شبیهسازی مغز چگونگی نشان دادن میلیونها نورون و اتصالات آنها درون این مراکز پردازشی در راستای کاهش نیرو و زمان است
امروزه یکی از محبوبترین الگوریتمهای شبیهسازی مدل «استفاده از حافظه» است. قبل از اینکه دانشمندان تغییرات شبکهی عصبی را شبیهسازی کنند نیاز دارند که ابتدا همه نورونها و اتصالات میان آنها را با استفاده از الگوریتم در مغز مجازی ایجاد کنند. مشکل اینجا است که برای هر جفت عصبی (نورونی)، مدل مورد نظر باید همهی اطلاعات مربوط به اتصالات هر گره را که نورونهای دریافتی (نورونهای پُستسیناپتیک) در آن قرار دارند نگهداری کند.
به عبارت دیگر، چون نورون پریسیناپتیک که پالسهای الکتریکی خروجی را به بیرون ارسال میکند پاسخی دریافت نمیکند، الگوریتم باید صرفا از طریق مشاهدهی نورون گیرنده و دادهی ذخیرهشده در گرهی آن تعیین کند که یک پیام خاص از کجا آمده است.
این فرایند شبیه یک راهاندازی عجیبوغریب به نظر میرسد؛ اما مدل مورد نظر به همهی گرهها اجازه میدهد بخش خاصی از شبکهی عصبی خودشان را بهصورت موازی بسازند که بهطور چشمگیری زمان بوت شدن را کاهش میدهد و تقریبا به همین دلیل این الگوریتم خیلی محبوب است.
اما همانطور که احتمالا حدس زدهاید، با مشکلات متعددی در مقیاسگذاری مواجه است. گرهی عصبی فرستنده پیام خود را به همهی گرههای عصبی گیرنده همهپخشی میکند؛ به این معنی که هر گرهی گیرنده نیاز دارد بر اساس هر سیگنال پیام دریافتی در شبکه مرتب شود و این در مورد نورونهایی که در گرههای دیگر قرار دارند هم صدق میکند. به این مفهوم که بخش بزرگی از پیامها در هر گره کنار گذاشته میشوند؛ زیرا نورون مقصد در آن گره خاص حضور ندارد؛ برای درک بهتر تصور کنید کارمندان ادارهی پست که بیش از حد کار کردهاند همهی پستهای الکترونیکی یک کشور را بررسی میکنند تا آنهایی که متعلق به قوهی قضایی آنهاست پیدا کنند. این روش به طرز دیوانهواری کم بازده است؛ ولی تا حد زیادی در مدل «استفاده از حافظه» به کار میرود.
همانطور که اندازهی شبکهی عصبی شبیهسازیشده رشد میکند مشکل هم بزرگتر میشود. هر گره نیاز دارد فضایی از حافظه را به یک «دفترچه آدرس» اختصاص بدهد تا نورونها و ارتباطات آنها در آن فهرست شوند. در مقیاس میلیونها نورون، دفترچه آدرس به یک حافظهی بزرگ تبدیل میشود.
اندازه در برابر منبع
این تیم با اضافه کردن یک قطعه کد به الگوریتم، مشکل مورد نظر را رفع کرد. در اینجا به چگونگی عملکرد آن پرداخته میشود.
گرههای گیرنده دو بلوک اطلاعات را شامل میشوند:
اولین بلوک پایگاهدادهای است که دادههای مربوط به نورونهای فرستندهای که به هر گره متصل شدهاند نگهداری میکند. با توجه به اینکه سیناپسها در انواع و اندازههای متفاوتی هستند که باعث تفاوت مصارف حافظهی آنها میشود، این پایگاه داده اطلاعات خود را بر اساس انواع سیناپسهایی که توسط نورونهای درون گره شکل گرفتهاند مرتب میکند.
این تنظیمات در حال حاضر بهطور قابل توجهی با اجداد خود متفاوت است؛ زیرا در آن دیتای مربوط به اتصالات بر اساس منابع عصبی ورودی مرتب میشود، نه بر اساس انواع سیناپسها. به همین دلیل گرهی مورد نظر نباید بیشتر از این «دفترچه آدرس» خود را نگه دارد.
نویسندگان پژوهش میگویند:
چون دیتای مربوط به اتصالات بر اساس منابع عصبی ورودی مرتب میشود، نه بر اساس انواع سیناپسها؛ ساختار داده مستقل از تعداد کلی نورونهای موجود در شبکه است.
بلوک دوم دادههای مربوط به اتصالات واقعی بین گرهی گیرنده و فرستندگان آن را ذخیره میکند. مشابه بلوک اول، این بلوک داده را بر اساس انواع سیناپس سازماندهی میکند. به ازای هر نوع سیناپس، این بلوک دادهها را بر اساس منبع آنها (نورون فرستنده) جدا میکند.
به این ترتیب، الگوریتم بسیار دقیقتر از نمونههای پیشین است؛ بهجای مرتبسازی همهی اتصالات در هر گره، گرههای گیرنده تنها دادههای مربوط به نورونهای مجازی قرار گرفته در خودشان را ذخیره میکنند.
این تیم همچنین به هر نورون فرستنده یک «دفترچه آدرس هدف» اختصاص داده است. در حین انتقال دیتایی که به چند تکه شکسته شده، هر تکه حاوی قطعه کدی برای مرتبسازی است که آن را به گرههای گیرندهی صحیح هدایت میکند. در عوض پخش یک پیام در گسترهی کامپیوتر، در اینجا دیتا به نورونهای گیرنده که قرار است به آنها برسد محدود میشود.
سریع و هوشمند
اصلاحات مورد نظر اعمال شدند. در سریهای آزمایشی، الگوریتم جدید از نظر مقیاسپذیری و سرعت بسیار بهتر از سری قبل خودش اجرا شد. در ابررایانهی JUQUEEN در آلمان، به لطف طرح انتقال داده ساده و پر بازده، الگوریتم ۵۵ درصد سریعتر از مدلهای پیشین خود روی شبکههای عصبی تصادفی اجرا شد. به عنوان مثال، در شبکهای از نیم میلیون نورون، شبیهسازی نصف اتفاقات بیولوژیکی با استفاده از الگوریتم جدید، حدودا ۵ دقیقه از زمان اجرای JUQUEEN را میگیرد. مدل سابق ۶ برابر این زمان طول میکشید.
دکتر مارکوس دیسمان،نویسنده و محقق مرکز تحقیقاتی یولیش، میگوید:
این الگوریتم بهطور واقعی به بررسی عملکرد مغز میپردازد، مانند قالبپذیری و یادگیری که در طول چند دقیقه صورت میگیرد و اکنون ما به آن دسترسی داریم.
همانطور که انتظار میرفت، چندین آزمایش مقیاسپذیری که انجام شد نشان داد که الگوریتم جدید در مدیریت شبکههای بزرگ بسیار حرفهایتر است و زمانی که صرف میکند تا دهها هزار انتقال داده را پردازش کند تقریبا به یک سوم کاهش میدهد.
نویسندگان به این نتیجه رسیدند:
تکنولوژی جدید از ارسال تنها دادههای مربوط به هر فرایند سود میبرد. از آنجایی که امروزه حافظهی کامپیوتر از شبکه جدا شده است، این الگوریتم برای به عهدهگرفتن شبیهسازی گسترهی مغز توازن یافته است. اکنون تمرکز روی تسریع شبیهسازی در انواع شبکههای انعطافپذیر است.
با این رهیافت، مغز دیجیتال بشر نهایتا در دسترس خواهد بود.
درحالیکه یک انقلاب صورت گرفته است، تیم یادآوری میکند که خیلی کارهای دیگر باید انجام شود. برای نمونه، نگاشت ساختار شبکههای عصبی واقعی به توپولوژی گرههای کامپیوتر باید انتقال داده را آسانتر کند.
اما در آخر باید یادآور این نکته شویم که بسیاری از متفکران و دانشمندان معتقدند هوش مصنوعی میتواند همانند یک شمشیر دولبه برای موجودیت بشر باشد. از طرفی میتواند انسان را به قدرتمندترین موجود هستی تبدیل کند و از طرفی میتواند حیات او را به مخاطره بیندازد. پروفسور استیون هاوکینگ فیزیکدان برجسته انگلیسی که به تازگی درگذشت، چندی پیش هشدار داده بود که تلاش برای ساخت ماشینهای هوشمند و متفکر، تهدید جدی برای بشریت محسوب میشود و انسان که با تکامل زیستی کُند محدود شده است، قادر به رقابت با ماشینهای هوشمند نخواهد بود و در نهایت حذف خواهد شد. وی تنها دانشمندی نیست که درخصوص خطرات هوش مصنوعی هشدار داده؛ ایلان ماسک، بنیانگذار شرکت هوافضای اسپیسایکس، هوش مصنوعی را خطرناکتر از سلاح اتمی توصیف کرده و معتقد است که رباتها میتوانند نسل بشر را در آینده نابود کنند.