هوش مصنوعی آلفازیرو دیپ مایند در مسابقات شطرنج و شوگی پیروز شد

دیپمایند، زیرمجموعهی شرکت مادر گوگل یعنی آلفابت است که در بریتانیا و در حوزهی هوش مصنوعی فعالیت میکند. این شرکت سال گذشته خبر از طراحی و توسعهی هوشی برای کسب مهارت بازی شطرنج و شوگی داد. شوگی، نوعی بازی ژاپنی شبیه به شطرنج است. هدف دیپ مایند، طراحی هوشی با نام AlphaZero بود که با یادگیری شخصی، مهارت کافی را در بازیهای فکری کسب کند.
آلفازیرو بهگونهای طراحی شد تا بدون آموزش خارجی، خودش بهتنهایی بازیهای شطرنج، شوگی و بازی تختهای چینی به نام Go را بیاموزد. محصول جدید دیپمایند توانست در هر حوزه، قهرمانان آن را شکست دهد. موفقیت بهدستآمده، مرحلهای جدید از یادگیری بازیهای دونفره توسط کامپیوتر را نشان میدهد. منظور از این بازیهای دونفره، بازیهایی مانند شطرنج هستند که تصمیمگیری در آنها براساس اتفاقات رخداده در بازیهای قبلی، قابل یادگیری و پیشبینی باشد.
موفقیت دیپ مایند بسیار مهم و تأثیرگذار بود. البته کمی طول کشید تا منبعی معتبر، یک بررسی جامع از روند کار و موفقیت هوش مصنوعی انجام دهد. بههرحال شرکت در هفتهی گذشته اعلام کرد که مجلهی معتبر علمی Science این رخداد را تأیید کرد و تیتر روی جلد خود را به آن اختصاص داد.
دیوید سیلور محقق ارشد پروژهی آلفازیرو در کنفرانس خبری مراسم NeurIPS ۲۰۱۸ در مونترئال گفت:
چند سال پیش، برنامهی ما به نام AlphaGo توانست قهرمان ۱۸ دوره از مسابقات گو را با نتیجهی ۴ بر یک شکست دهد. این رخداد برای ما شروع یک مسیر بود. هدف اصلی ما، توسعهی سیستم یادگیری جامعی بود که بازیهای مختلف را تا سطح بسیار حرفهای بیاموزد.آلفازیرو، قدم بعدی ما در این مسیر محسوب میشود. هوش مصنوعی جدید، از ابتدا بازیها و قوانین آنها را آموخت و بدون هیچ آموزش دیگر، موفق شد تا قهرمانان جهان را در بازیهای شطرنج، گو و شوگی شکست دهد.

سیلور در ادامه توضیح داد که انتخاب بازیهای مذکور، بهخاطر پیچیدگی و همچنین تاریخچهی طولانیمدت آنها از لحاظ تلاش هوش مصنوعی برای شکست دادن انسانها، انتخاب شدند. او دربارهی این بازیها میگوید:
شطرنج، نشاندهندهی دستاوردی است که توسط انواع هوش مصنوعی سنتی قابل دستیابی بود. موفقیت در این بازی توسط نمونههای قبلی هوش مصنوعی و تلاش برای عالی کردن آنها بهدست آمد. ما میخواستیم توانایی هوش جدید را در دستیابی به موفقیتهای نمونههای پیچیدهی قبلی، تنها از راه یادگیری بررسی کنیم.دلیل انتخاب شوگی نیز دشواری یادگیری آن توسط برنامههای کامپیوتری بود. درواقع این بازی یکی از معدود بازیهای تختهای (بهجز بازی بسیار چالشی گو) است که یادگیری آن برای برنامههای خاص کامپیوتری هم دشوار است. تنها در یکی دو سال گذشته بود که آمارهایی از پیروزی برنامههای کامپیوتری بر قهرمانان شوگی منتشر شد.
محققان هوش مصنوعی برای چالشهای جدید، باید سراغ نسل جدید بازیها بروند
ماری کمپل یک محقق هوش مصنوعی در مرکز تحقیقات آیبیام واتسون در نگارش مقاله به تیم دیپمایند کمک کرده است. او اعتقاد دارد این دستاورد، پایانی بر تلاشهای چند دهه در حوزهی هوش مصنوعی بود. کمپل عضو تیم تحقیقاتی آیبیام در پروژهی دیپ بلو بود که در سال ۱۹۹۷، قهرمان شطرنج آن زمان یعنی گری کاسپاروف را شکست داد.
کمپل اعتقاد دارد محققان هوش مصنوعی برای چالشهای جدید، دیگر باید به فکر نسل جدیدی از بازیها باشند. در بازیهای مورد نظر کمپل، برخلاف شطرنج، همهی اطلاعات لازم برای تصمیمگیری، بهصورت واضح وجود ندارند. بهعنوان مثال در بازیهای کارتی همچون پوکر، بازیکنان کارتها را نزدیک به خود نگه میدارند و تصمیمگیری، دشوارتر خواهد بود. بسیاری از بازیهای چندنفرهی آنلاین مانند StarCraft، Dota و Minecraft نیز در این دستهبندی قرار میگیرند.
ماری کمپل در مصاحبه با مجلهی Spectrum از مؤسسهی IEEE دربارهی چالش بازیهای نسل جدید میگوید:
بازیهای چندنفره، از بازی گو هم دشوارتر هستند اما آنچنان دشوار محسوب نمیشوند. درحالحاضر نیز یک گروه توانسته است بهترین بازیکنان Dota 2 را شکست دهد. البته، بازی آنها نسخهای محدود از بازی اصلی بود. استارکرافت مقداری دشوارتر بهنظر میرسد. البته بهنظر من هردو بازی از اهداف قابل دستیابی تا ۲ یا ۳ سال آینده خواهند بود.
مقالهی منتشرشده دربارهی مسیر موفقیت آلفازیرو، این هوش مصنوعی را با نمونههای دیگر متخصص در بازیهای شطرنج و شوگی مانند Stockfish، Elmo و محصول IBM یعنی Deep Blue بررسی میکند. درواقع آلفازیرو بهجای دیکته شدن قوانین بهصورت دستی، از یک شبکهی عصبی عمیق برای یادگیری بهره میبرد. شبکهی عصبی در بحث هوش مصنوعی، نشاندهندهی توابع ریاضیاتی لایهای است که عملکرد نورونهای مغز انسان را شبیهسازی میکند.

اساتید شطرنج، از نحوهی بازی آلفازیرو برای تحقیقات خود استفاده میکنند
روش پویای بازی آلفازیرو، استراتژیهای خلاقانه و غیرمعمولی را نتیجه میدهد. قهرمان دو دوره مسابقات شطرنج و استاد بزرگ رشته یعنی متیو سدلر و قهرمان مسابقات بینالمللی زنان در شطرنج یعنی ناتاشا رگان در کتاب آیندهی خود از روشهای آلفازیرو الهام گرفتهاند و به بررسی این هوش مصنوعی و هزار بار بازی آن پرداختهاند.
سدلر درمورد هوش مصنوعی آلفازیرو میگوید:
موتورهای هوش مصنوعی سنتی، بسیار قوی هستند و چند اشتباه واضح محدود در بازی انجام میدهند. البته در موقعیتهایی که هیچ راهکار قابلمحاسبهی مشخصی وجود نداشته باشد، این نمونههای سنتی دچار اشتباه میشوند. اما آلفازیرو با یک پیشرفت قابل ملاحظه، سبک بازی خود را در بازهی گستردهای از استراتژیها تغییر میدهد.در موقعیتهای غیرقابل پیشبینی، احساسات، بینش و شهود مورد نیاز هستند که آلفازیرو اینها را بهکار میگیرد. آلفازیرو مانند انسانی با اشتیاق بالا بازی میکند که سبکی بسیار زیبا محسوب میشود.

بهعنوان مثالی از روش کار آلفازیرو، هوش مصنوعی توانست اصولی مانند شروع بازی، حفاظت از پادشاه و استراتژی چینش مهرههای پیاده را بیاموزد. روش بازی بهاین صورت است که پادشاه حریف محاصره میشود، سپس حرکات حریف محدود شده و حرکات مهرههای هوش مصنوعی افزایش پیدا میکند. نکتهی جالب توجه دیگر آن است که آلفازیرو برخلاف انسان، از قربانی کردن مهرههای خود برای اهداف بلندمدت، ترسی ندارد.
یادگیری بازیهای فکری مذکور توسط آلفازیرو، نیازمند شبیهسازی میلیونها بازی در مقابل خودش بود. فرایند یادگیری بازی به این صورت با نام Reinforcement Learning شناخته میشود. در روش مذکور، سیستم جایزه و تنبیه، هوش مصنوعی را بهسمت اهداف مشخصی پیش میبرد. آلفازیرو ابتدا بهصورت تصادفی بازی میکرد اما پس از مدتی، پارامترها را بهنوعی تنظیم کرد تا علاوهبر فرار از شکست، سبک بازی اختصاصی خود را پیدا کند.
آلفازیرو تمامی الگوریتمهای قبلی را در بازیهای شطرنج، شوگی و گو شکست داد
زمان مورد نیاز برای آموزش آلفازیرو، به نوع بازی بستگی داشت. حداقل، ۷۰۰ هزار مرحلهی آموزشی (هر مرحله شامل ۴۰۹۶ موقعیت تخته) روی سیستمهای مجهز به ۵ هزار واحد پردازش تانسور (TPU) و ۱۶ تیپییو نسل دوم (مدارهای مجتمع اختصاصی گوگل برای یادگیری ماشین)، در مدت ۹ ساعت، ساخت و بازی کردن شطرنج را انجام داد. برای شوگی و گو نیز به ۱۲ ساعت و ۱۳ روز زمان نیاز بود.
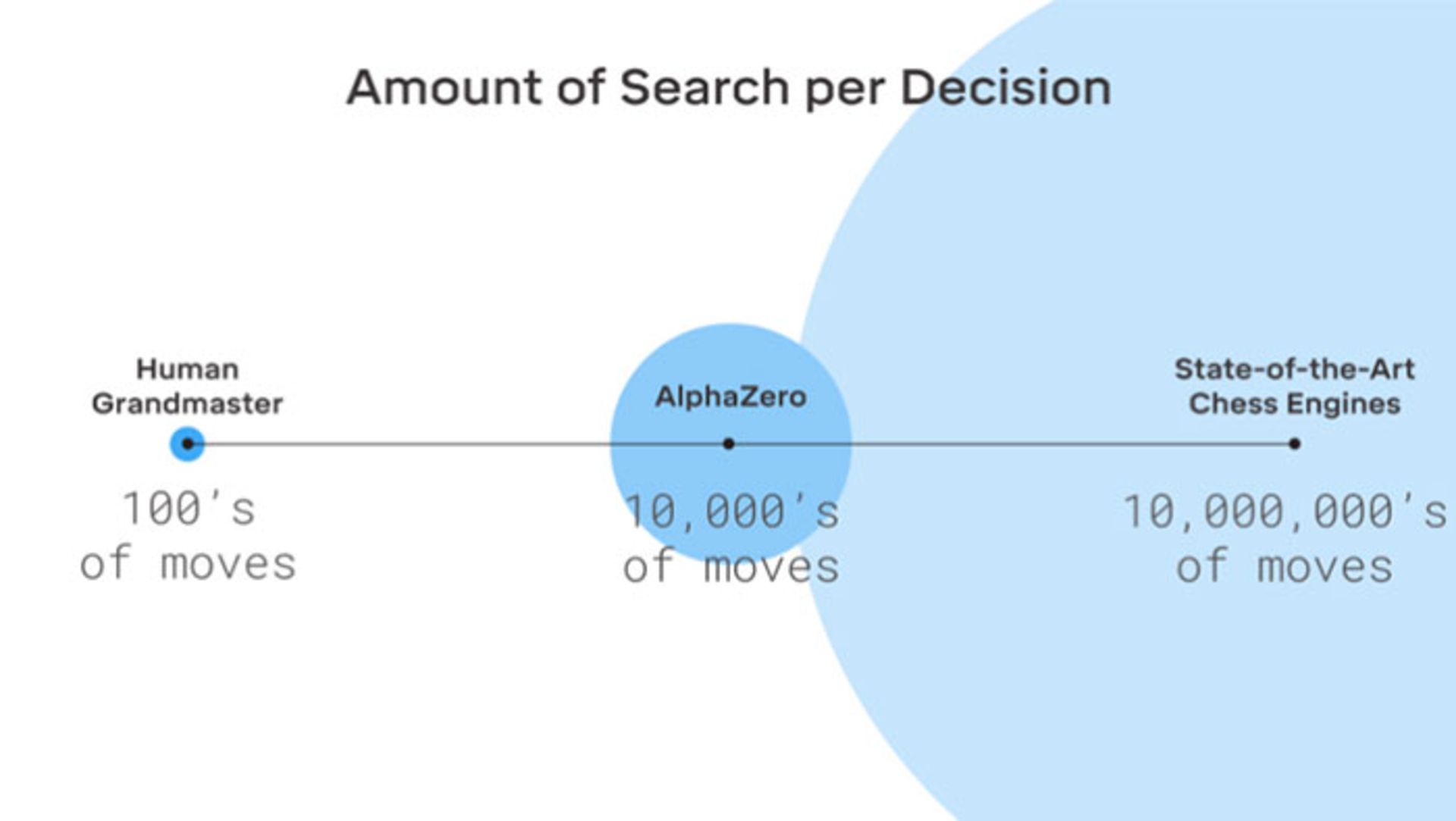
آلفازیروی حرفهای از الگوریتم جستجوی مونت کارلو (الگوریتم جستجوی ابتکاری برای فرایندهای تصمیمگیری) برای انتخاب هر حرکت استفاده میکند. این هوش مصنوعی جستجوها را بسیار سریع انجام میدهد. البته، هوش مصنوعی موقعیتهای بسیاری را در بازی بررسی میکند که نسبت به بررسیهای یک استاد بزرگ شطرنج، کارایی کمتری دارد؛ اما آلفازیرو در مقایسه با نمونههای دیگر موقعیتهای کمتری را بررسی میکند.
محققان دیپ مایند برای بررسی دقیقتر تواناییهای آلفازیرو، آن را در رقابت با الگوریتمهای دیگر همچون Stockfish و Elmo و همچنین نسل قبلی یعنی آلفاگوزیرو امتحان کردند. سختافزار مورد استفاده برای بازیها، سیستمی با ۴۴ هستهی پردازشی و ۴ عدد از نسل اول تیپییوهای مخصوص گوگل بود. این سختافزار، از لحاظ قدرت پردازش و استدلال با سیستمی مجهز به چندین کارت گرافیک انویدیا تایتان وی برابری میکند. آلفازیرو در رقابت با الگوریتمهای مذکور، بردهای متعدد و قابل توجهی را کسب کرد.
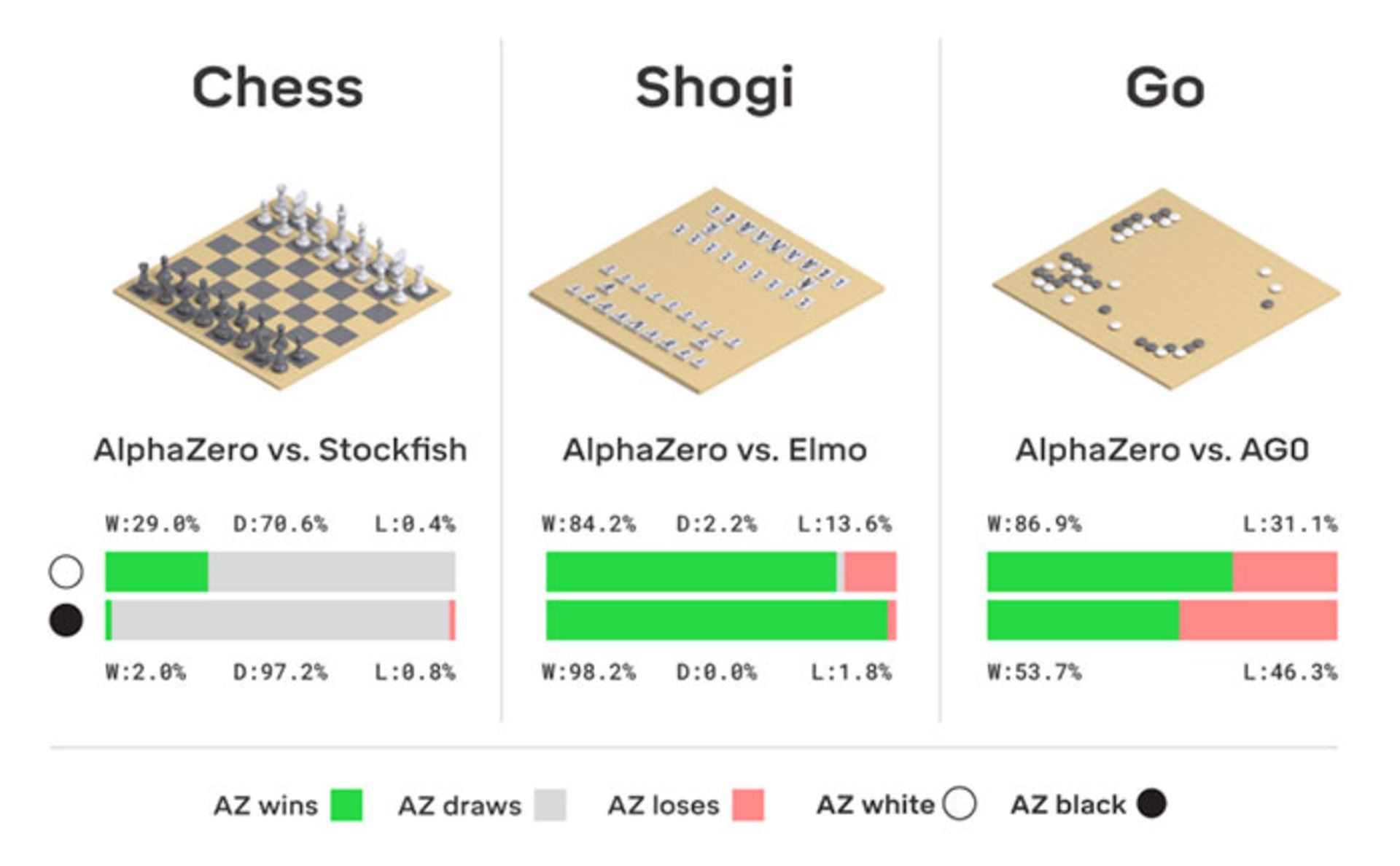
هوش مصنوعی آلفازیرو دربازی شطرنج، در هزار مسابقه با الگوریتم استاکفیش ۱۵۵ مسابقه را با برد به پایان رساند و تنها ۶ باخت ثبت کرد. بهعلاوه، هوش مصنوعی دیپ مایند در مسابقاتی که با استراتژیهای نزدیک به استراتژی انسانی شروع میشدند، بهترین نتیجهها را کسب کرد. استراتژیهای استفادهشده در مسابقات قهرمانی سال ۲۰۱۶ موتورهای پردازش شطرنج و بازیهایی با استفاده از آخرین نسخهی استاکفیش یعنی استاکفیش ۹ نیز در باربر آلفازیرو شکست خوردند. در برخی مسابقات نیز از نمونههای استاکفیش با تنظیمات مسابقات قهرمانی جهان از لحاظ کنترل زمان و شروع بازی استفاده شد که باز هم آلفازیرو پیروز میدان بود.
در مسابقهی شوگی، الگوریتم المو با تنظیمات مسابقات قهرمانی سال ۲۰۱۷، شرکت کرد. آلفازیرو، در ۹۱.۲ درصد از مسابقات پیروز شد. درمسابقات گو نیز الگوریتم آلفاگوزیرو مورد استفاده قرار گرفته که در ۶۱درصد از مسابقات، آلفازیرو برنده شد.
ترتیب حرکتهای آلفازیرو در مسابقات شطرنج و شوگی، درکنار مقالهی مذکور، منتشر شد. دمیس هاسابیس همبنیانگذار و مدیرعامل دیپمایند خبر انتشار حرکتها را اعلام کرد و به این نکته اشاره کرد که کمیتهی بینالمللی شطرنج درحال بررسی و استفاده از نحوهی بازی آلفازیرو است. کمیتهی شطرنج با استفاده از حرکات منتشرشده، مناظرهی رقابت را در مسابقهی قهرمانی جهان آتی بین مگنوس کارلسن و فابیانو کاروانا تشدید خواهد کرد.
رگان دربارهی تحلیلهای آلفازیرو و سبک بازی آن میگوید:
تفاوت تحلیل و بازی آلفازیرو با دیگر الگوریتمهای شطرنج و سبک بازی اساتید بزرگ رشته، جذاب و قابلتوجه است. من ماههای زیادی به بررسی بازیهای آلفازیرو پرداختم. تصور میکنم درک من از بازی پس از بررسیها تغییر کرده و بهبود یافته است. آلفازیرو، تمام آنچه که ما بهعنوان انسان در بازی شطرنج آموختیم را با سوالاتی جدید روبهرو میکند. درواقع این هوش مصنوعی میتواند ابزاری مفید برای آموزش در کل جامعهی شطرنج باشد.
هاسابیس در ادامهی صحبتهایش دربارهی پروژهی آلفازیرو اعتقاد دارد هدف نهایی این پروژه، ساختن یک هوش قوی برای بازی شطرنج نیست. هدف، استفاده از روند یادگیری آلفازیرو برای توسعهی سیستمهایی است که مشکلات دشوار جامعه را حل کنند.
موفقیت در بازیهای دیگر، راه را برای حل چالشهای واقعی هموار میکند
دیپمایند درحالحاضر در پروژههای متعدد هوش مصنوعی مرتبط با سلامت فعالیت میکند. یکی از پروژهها، همکاری با دپارتمان امور مجروحان جنگی ایالات متحدهی آمریکا بود. این پروژه در جهت پیشبینی بدتر شدن شرایط بیماران در زمان استراحت در بیمارستان، فعالیت میکند. دیپمایند پیش از پروژه در آمریکا، با سرویس سلامت ملی بریتانیا همکاری کرد تا الگوریتمی برای جستجوی علائم اولیهی نابینایی توسعه دهد. از آخرین پروژههای دیپمایند در بخش سلامت نیز میتوان به سیستم هوش مصنوعی توانمند در دستهبندی تصاویر سیتی اسکن اشاره کرد. نتایج پروژه، در کنفرانس Medical Image Computing & Computer Assisted Intervention در ابتدای سال جاری میلادی، معرفی شد.

یکی دیگر از محصولات دیپمایند در حوزهی هوش مصنوعی و یادگیری عمیق، آلفافولد نام دارد. این پروژه برای پیشبینی ساختار پیچیدهی پروتئینها طراحی شده است. آلفالود در رقابت با ۹۸ الگوریتم دیگر در مسابقات پیشبینی ساختار پروتئین با نام CASP13 رتبهی اول را ازآن خود کرد.
مدیرعامل دیپمایند در پایان دربارهی آلفازیرو و ادامهی مسیر آن میگوید:
آلفازیرو برای همهی ما یک پله به سمت هوش مصنوعی بهمعنای عمومی محسوب میشود. دلیل بررسی و آزمایش این الگوریتم و خود ما، آن است که آنها مرحلهای اساسی برای توسعهی الگوریتمها هستند. ما در نهایت درحال کار روی الگوریتمهایی هستیم که برای رخدادهای دنیای واقعی قابل استفاده باشند و مشکلات اصلی آن را حل کنند. هدف اصلی، کمک کردن به متخصصان آن حوزهها است.
چالشهای زندگی واقعی، بهندرت تمامی اطلاعات لازم برای تصمیمگیری را به ما عرضه میکنند (برخلاف شطرنج و بازیهای مشابه). بههمین دلیل، هوش مصنوعی که بتواند مشکلات با اطلاعات کم را حل کند، راهکاری مفید در زندگی واقعی همچون پیشبینیها و مدلسازیهای مالی یا حتی جنگ، خواهد بود. درواقع قدم بعدی یعنی شکست دادن بازیهای چندنفرهی آنلاین، اولین قدم در مسیر خواهد بود. یک خودروی خودران مجهز به چنین هوش مصنوعی، میتواند درنهایت جادهها را در اختیار خود درآورد و برای شرکتی که این ایده را پیادهسازی کند، موفقیتهای بسیاری بههمراه داشته باشد. شاید Waymo، شعبهی آلفابت در حوزهی خودروهای خودران، در همکاری با دیپمایند بتواند به چنین دستاورد بزرگی دست پیدا کند.
نظر شما چیست؟ آیا هوش مصنوعی با این روند میتواند در حل مشکلات واقعی انسانها هم موفق شود؟