چگونه OpenAI هوش مصنوعی GPT-2 را توسعه داد؟

امروز، سازمان ملل متحد خواستار کنارگذاشتهشدن فوری تمامی تسلیحات هستهای جهان شد.
حتما بهدنبال نویسنده این نقلقول هستید. تصور عموم این است که این جمله را نویسنده یا ویراستار یکی از وبسایتهای خبری نوشته باشد؛ درصورتیکه هیچ انسانی آن را ننوشته است. جملهای که خواندید، مدل زبانی GPT-2 نوشته است. هوش مصنوعی OpenAI با الگوریتم جدید مدلسازی زبان، این جمله را تنها با دراختیارداشتن کلیدواژهی «امروز» خلق کرده است.
جدا از نام فانتزی انتخابشده برای این فناوری، الگوریتم مدلسازی زبان GPT-2 قابلیت نسبی و تاحدودی منسجم در بخش معناشناسی دارد. این الگوریتم مدلسازی زبان از ویژگی زایایی برخوردار است؛ درحالیکه این ویژگی منحصر به زبان انسان است. زایایی زبان بهمعنای توانایی تولید صورتهای جدید زبانی براساس قواعد موجود در زبان است که یکی از ویژگیهای مهم آن بهشمار میرود. بیش از ۴۰ گیگابایت دادهی اینترنتی بههمراه چیزی نزدیک به ۱.۵ میلیارد پارامتر از ساختارهای متنی برای آموزش این مدل زبانی بهکار گرفته شده است.
بیش از ۴۰ گیگابایت دادهی اینترنتی بههمراه چیزی نزدیک به ۱.۵ میلیارد پارامتر از ساختارهای متنی برای آموزش زبان GPT-2 بهکار گرفته شده است
این مقادیر بسیار زیاد هستند؛ اما درواقع آنچه باعث ایجاد شگفتی در دنیای عظیم اینترنت میشود، نوشتن مقالاتی دربارهی حیوانات چهارشاخ و اسبهای تکشاخ در کوههای آند بهوسیلهی GPT-2 نیستند.

نمونهی تولید متنی از الگوریتم مدلسازی زبان OpenAI GPT-2
در این نوشته، قرار نیست بیش از این دربارهی مدلهای بهتر زبانی و پیامد و کاربردهای آنها صحبت کنیم. تا جایی که به بحث ما مربوط میشود، سعی بر آن است با نحوهی کار و چگونگی کدنویسی بزرگترین تولیدکننده الگوریتم متنی بیشتر آشنا شویم که تا بهحال بشر با آن روبهرو شده است.
توجه کنید مدل GPT-2 ساخت ما قرار نیست با تولید نقلقولهای جعلی از برگزیت (Brexit) کار خود را آغاز کند. پیشتر، نسخه GPT-2 چند نقلقول ساختگی از سازندگان خود تولید کرده و توانسته بود حین نگارش متن آزمایشی دربارهی برگزیت، نقلقولهایی جعلی از رهبر حزب کارگر انگلستان تولید کند. مدل اصلی GPT-2 ماهها است که آموزش میبیند و از پردازندههای گرافیکی بسیار قدرتتمند (100+ GPUs) استفاده میکند.
بعید بهنظر میرسد کاربری اینچنینی توان پردازشی را در خانهی خود داشته باشد؛ پس همینکهmini-GPT خانگی ما بتواند اصول دستوری مربوطبه فعلوفاعل را بهدرستی رعایت کند، خود قدم بزرگی است.
GPT-2 چیست؟
در تمام مقالات OpenAI دربارهی هوش مصنوعی و تحقیقات مربوطبه یادگیری عمیق، اصطلاحات فنی و تخصصی مانند ضرایب ماتریسها بهچشم میخورد. بهتر است قبل از شروع تخصصی بحث، مطالبی را روشن کنیم تا فهم مطالب آسانتر شود.
GPT-2 مخفف چه واژههایی است؟ حرف G مخفف واژه Generative بهمعنای «تولیدکننده یا زایا» و حرف P مخفف واژهی Pretrained بهمعنای «پیشآموزش دادهشده» و حرف T مخفف واژهی Transformer بهمعنای «مبدل» است.
GPT-2 چگونه کار میکند؟
قبل از بحث دربارهی چگونگی کارکرد GPT-2، بهتر است بهطورخلاصه پیشرفت و نحوهی کار NLP را تا سال ۲۰۱۸ بررسی کنیم. در اینجا، مفاهیم پیشرفتهی ریاضی با استفاده از تصاویر توضیح داده شده است.
۲۰۱۸:
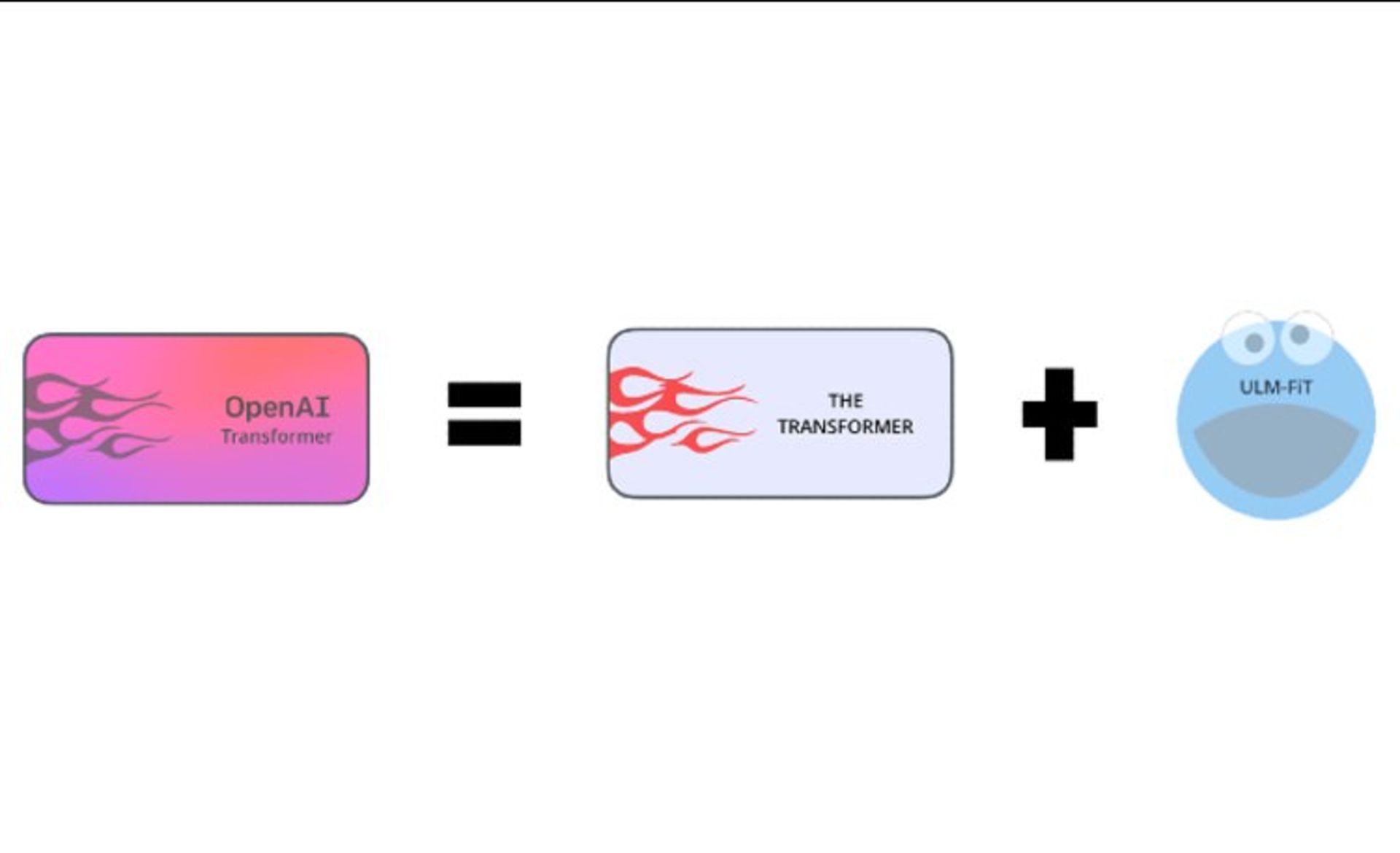
OpenAI Transformer v1 (aka GPT-1) = ULMFiT + Transformer
۲۰۱۹:
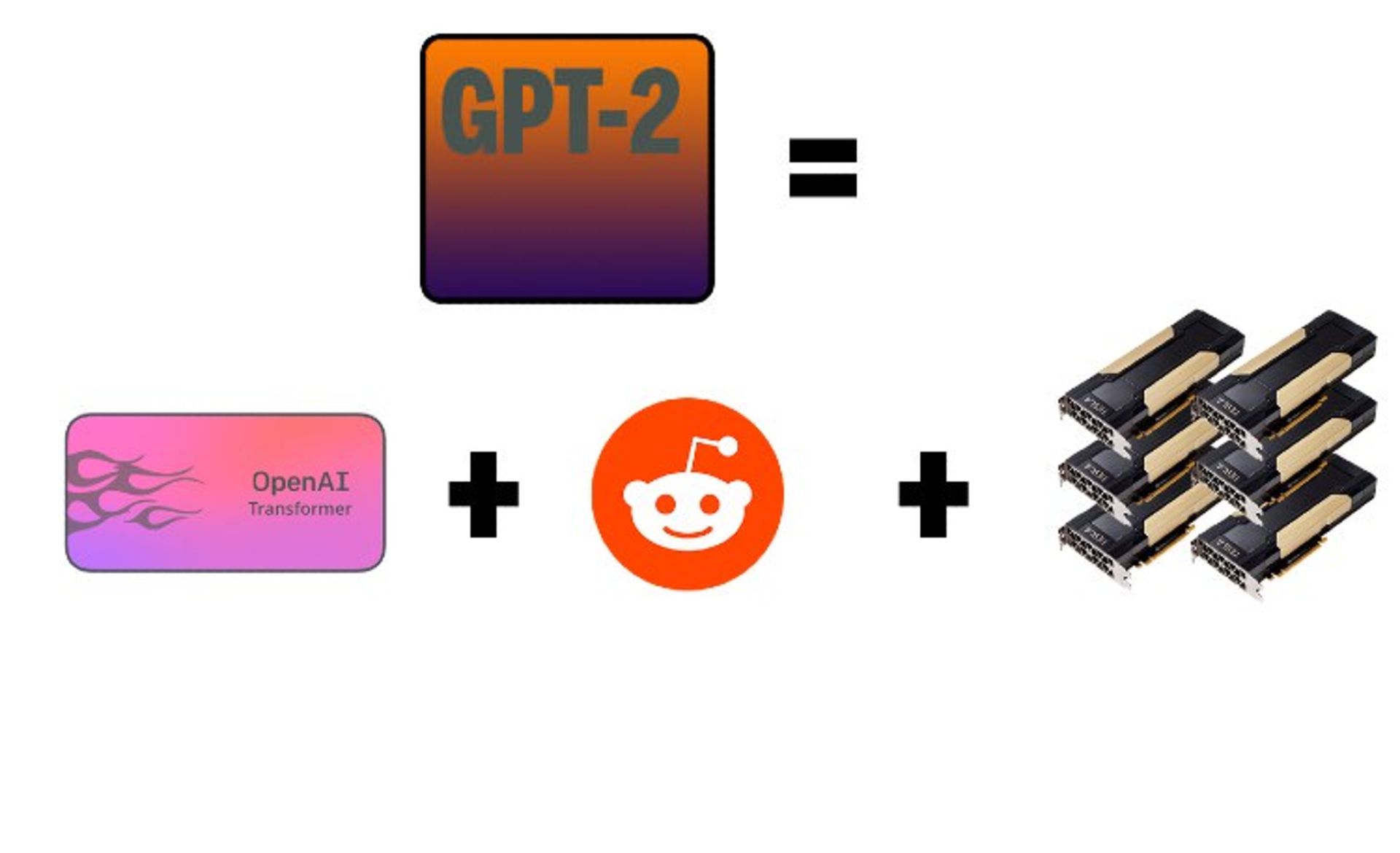
GPT-2 = GPT-1 + reddit + A lot of compute
اطلاعات ارائهشده در بالا نیازمند دانش و اطلاعات پیشزمینهای در این حوزه است؛ پس طبیعی است اگر فهم این مطالب برایتان دشوار باشد. یادآوری این نکته مهم است که ELMO و BERT دو مدلی بودند که باعث پیشرفت GPT-2 شدند. با توسعهی مدل ELMO، این مسئله برای پردازش زبان طبیعی محرز شد که بازنماییهای برداری حساس به بافت خیلی بهتر از بردارهایی مانند word2vec میتوانند در پردازش زبان مؤثر باشند.
این بردارها ویژگیهای بدون ناظری هستند که روی متن خام بسیار بزرگ بدون برچسب یاد گرفته میشوند و در مسائل مختلف پردازش زبان، بهصورت ویژگی کمکی به ردهبندی (معمولا شبکه عصبی) کمک میکنند. بعد از ELMO، مدلهای دیگری ازجمله BERT بهوجود آمدند که ازنظر محاسباتی پیچیدهتر، ولی ازنظر دقت عملی بسیار قویتر هستند. اگر تا به اینجای مطلب، اطلاعاتی درباره الگوریتمها و مدلها و فناوریهای GPT-2 دستگیرتان شده، باید به شما تبریک گفت؛ چراکه مفاهیم اولیهی مدل NLP را متوجه شدید.
Transformers

همانطورکه قبلا گفته شد، ترنسفورمرها معماری بینظیری از شبکههای عصبی هستند. آنها بهعنوان جعبهسیاه کار پردازش را انجام میدهند و درواقع، ساختاری برای انجام محاسبات در GPT-2 هستند؛ اگرچه در واقعیت ممکن است چیزی جز انتزاع بهنظر نرسند.
مدلهای پیشآموزشدیده زبانی
روند دیگری که NLP از سال ۲۰۱۸ پیش گرفت، استفاده از یادگیری انتقالی بود. از یادگیری انتقالی سالها است که در بینایی رایانهای ( استفاده میشود؛ اما اخیرا NLP برای استفاده در پروژههای خود از آن بهرهمند شده و آنقدر در کاربردش موفق بوده که تاکنون هنوز از آن استفاده میکند. یادگیری انتقالی (Transfer Learning) یکی از روشهای یادگیری در یادگیری ماشین (Machine Learning) است که بر ذخیرهسازی دانش کسبشده ضمن حل مسئله و اعمال آن بر مسائل متفاوت، ولی مرتبط دیگر متمرکز شده است.
یادگیری انتقالی به دو روش معمولا انجام میشود: روش مبتنیبر ویژگی (Feature-based) و روش مبتنیبر تنظیم دقت (Fine-tuning). مدل ELMO از روش مبتنیبر ویژگی استفاده میکند. در این روش اطلاعات محتوایی بردارهای متنی بهوسیلهی بردارهای حالت پنهان از مدلسازی زبان به بردار کلماتی موجود ایجاد میشوند. شایان ذکر است مدلهای BERT و GPT از روش مبتنیبر ویژگی استفاده نمیکنند. طبق تحقیقات سال ۲۰۱۸، این نتیجه حاصل شد که روش مبتنیبر تنظیم دقت کارآمدتر است؛ چراکه ازطریق شبکهی عصبی بازگشتی به مدل زبانی اجازهی اصلاح خواهد داد.
ترنسفورمرها و مدلهای زبانی پیشآموزشیافتهی
مدل جدیدی که OpenAI در هوش مصنوعی خود بهکار گرفته، مدلی از تیمی موفق است؛ ترکیبی که همهی اجزای آن مانند معماری فوقالعاده ترنسفورمرها و ویژگی Fine-tuning در مدل زبانی و مدلهای پیشآموزش زبانی همه دستبهدست هم داده تا مدل زبان موفقی بهوجود آورد. یکی از روشهای متداول حل مسئلهی بهینهسازی در شبکههای عصبی، قابلیت بازگشت به عقب (Back Propagation) است. GPT از دل روش بازگشت به عقب متولد شد. بااینحال، دستیابی به موفقیت GPT به این آسانی نبود و چندین مانع در این راه وجود داشت. نخستین مانع معماری ترنسفورمرها بود؛ زیرا معماری آنها آنقدر پیچیده و پیشرفته بود که اصلا مشخص نبود چگونه میتوان از این معماری برای مدلسازی زبان استفاده کرد. برای اینکه بهتر متوجه شوید، به نمودار زیر نگاه کنید.
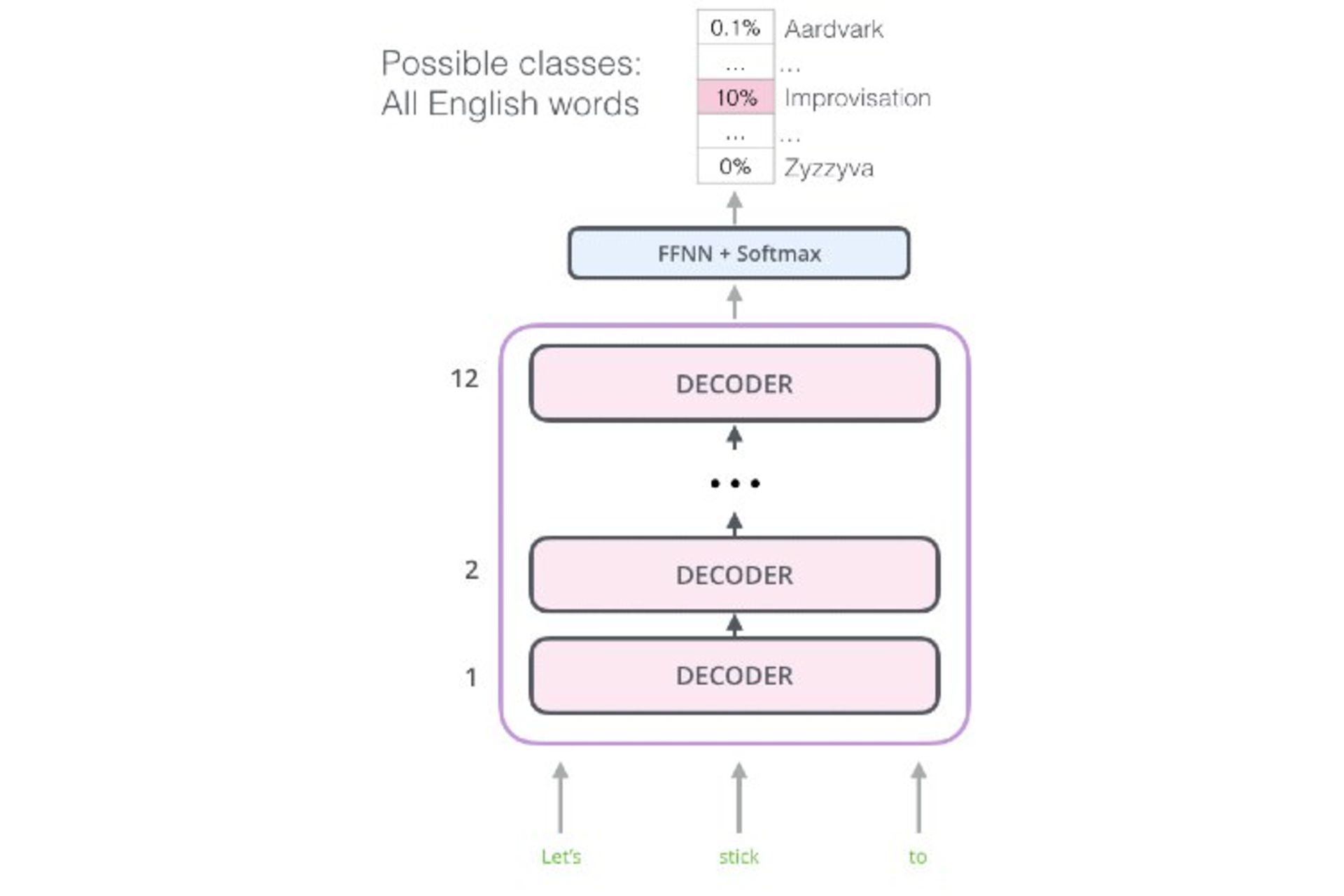
ترنسفورمر از الگوریتمی که به آن داده میشود، انتظار دارد جملهای کامل باشد. در اینجا مفهوم جمله بهمعنای توالی ثابتی از کلمات به طول ۵۱۲ کاراکتر است، نه جملهای در مفهوم رایج. سپس، این اطلاعات ورودی رمزگذاریشده با استفاده از رمزگشا (Decoder) تبدیل میشوند.
این عملکرد برای برنامههای مرحلهای دارای توالی، مانند ترجمهی ماشینی و سیستمهای مبتنیبر پرسشوپاسخ، بسیار مفید و کارآمد است؛ اما برای مدلسازی زبانی عملکرد مناسبی ندارد. مدل زبانی باید به قابلیت پیشبینی مجهز باشد؛ بهطوریکه بتواند واژهی بعدی در دنبالهی جمله را بهدرستی پیشبینی کند.
خوشبختانه بخش رمزگشا در ترنسفورمر تاحدودی میتواند این کار را انجام دهد. دقت کنید بخش رمزگشا چگونه کار میکند. رمزگشا باتوجهبه بازنمایی رمزگذاریشدهی توالی، دنبالهی جدیدی را کلمهبهکلمه تولید میکند.
(wordt =Decoder(wordt−1,encoding
اگر فقط بخش رمزگذاری (encoding) را از فرمول بالا حذف کنیم، فرمول جدیدی بهدست میآید:
(wordt=Decoder(wordt−1
فرمول جدید دقیقا همان چیزی است که مدلسازی زبان باید انجام دهد. درنتیجه، باید بخش رمزگذاری در ترنسفورمر کنار گذاشته شود تا معماری نهایی مدلسازی زبان بهصورت زیر حاصل شود.
بهطورخلاصه، معماری GPT چیزی جز قابلیت بخش رمزگشای شبکهای منظم در ترنسفورمر با کنارگذاشتن بخش رمزگذاریشده نیست.
ویژگی Fine-tuning در GPT
آنچه تاکنون گفته شد، تنها نیمی از داستان است. GPT تنها بهدلیل نوآوری و خلاقیت ویژگی Fine-tuning قادر خواهد بود چندین تکلیف را بهطورهمزمان انجام دهد. تا به اینجا، مدل زبانی خوب و کارآمدی داریم که به پویایی زبان انگلیسی دست پیدا کرده است. این دستاورد حاصل ماهها آموزش با پیکرهی متنی بسیار بزرگ برگرفتهشده از اینترنت است.
تا اینجای کار، بهصورت نظری اگر یک یا دو تکلیف خاص را به مدل زبانی بدهیم، بهراحتی میتوان قابلیتهای ارتقایافته زبانشناختی را در این مدل زبانی مشاهده کرد؛ درحالیکه این مدل زبانی با تکالیف ارائهشده سازگاری دارد.
حال مشخص شده این قابلیت، تنها در مرحلهی نظری باقی نمانده و این روش بهطورعملی کار میکند. این مدل آنقدر کارآمد است که بهعنوان هنر بنچمارک در NLP شناخته شده است؛ آنقدر کارآمد که میتواند بهعنوان ImageNet در NLP تحسینبرانگیز باشد.
گام کوچکی برای انسان، جهش غولآسایی برای مدل زبانی
GPT عالی بود؛ اما نه برای همیشه. کمی بعد، رویکرد مشابه دیگری با نام BERT را تیم مدلسازی زبان گوگل پس از GPT منتشر کرد. طرفداران NLP مانند بچهای که در فروشگاه آبنبات خوشرنگتری دیدهاند، GPT را رها کردند؛ اگرچه این دوری چندان طول نکشید و OpenAI با ایدهای متحولکننده و انقلابی برای ارتقای مدل زبانی خود بازگشت.
عاملی که BERT را در آن زمان برتر جلوه داده بود، استفاده از مدل دوسویهی زبانی (Bidirectional Language Model) بود؛ درحالیکه GPT از مدل تکسویه (Unidirectional Language Model) زبانی استفاده میکرد. مدل دوسویه سازوکاری برای نگهداری سازگاری میان دو یا چند منبع اطلاعاتی مرتبط است. مزیت مدل دوسویه تضمین برقراری سازگاری بهوسیلهی ساختار زبان است. اگرچه در اینجا قرار نیست درباره این موضوع صحبت کنیم که کدامیک ارزشمندتر هستند.
میتوان تصور کرد احتمالا بحث شکلگرفته در هیئتمدیرهی OpenAI روزی که فناوری BERT در مقالهای منتشر شد، اینگونه بوده باشد:
مدیر:
بهنظر میرسد عملکرد BERT بهتر از ایدهی ما است. چگونه کار میکند؟
مهندس تصادفی ۱:
خُب، مثل اینکه نوعی مدلسازی زبان مخفی (Masked Language Modeling) است و درصد مشخصی از کلمات را مخفی میکند و با این کار مدل زبانی را آموزش میدهد که بتواند باقی کلمات را بهدرستی پیشبینی کند. آنها از مدلی دوسویه استفاده میکنند که عمیقا رمزگذاری میکند.
مدیر:
شفافتر بگو، لطفا.
مهندس تصادفی ۱:
مدل آنها دقیقا شبیه مدل ما است، با این تفاوت که یک جفت چشم اضافی در پشتسرش هم دارد.
مدیر:
بنابراین سؤال مهم این است: چگونه میتوانیم با آنها مقابله کنیم؟
مهندس تصادفی ۲:
ما هم میتوانیم مدلی دوسویه آموزش دهیم؛ اما این فقط کپی کار آنها میشود. یا شاید ما بتوانیم به...
مهندس تصادفی ۱:
خیر، این دقیقا شبیه به چرخهای بیپایان است. اگر آنها امروز فناوری BERT را معرفی کردند، احتمالا در آینده مدل بهتری را جایگزینش میکنند. ما باید بهدنبال راهحلی منطقی و بلندمدت باشیم.
کارآموز:
میدانید، ما فقط باید GPUها و دادههای بیشتری به مدل خودمان اضافه کنیم.
همه آن سه نفر باهم:
تو نابغهای!
صفحهی اول اینترنت
درعوض تلاش برای شکست BERT، محققان OpenAI تصمیم گرفتند نسخهی جدیدی از GPT را با نام جدید GPT-2 معرفی کنند. ایجاد تغییر ماهیتی، رمز موفقیت آنها بود. بهبیانی ساده، BERT برای تکلیف زبانی جای خالی را پر کنید (Fill-in-the-blanks) مناسب بود؛ چون برای این کار آموزش دیده بود؛ درحالیکه هوش مصنوعی جدید GPT-2 در تکلیف زبانی نوشتن مقالات بسیار عالی عمل میکرد. محققان OpenAI تصمیم گرفتند نسخهی جدید را برای نوشتن مقالات زبانی بهتر آموزش دهند.
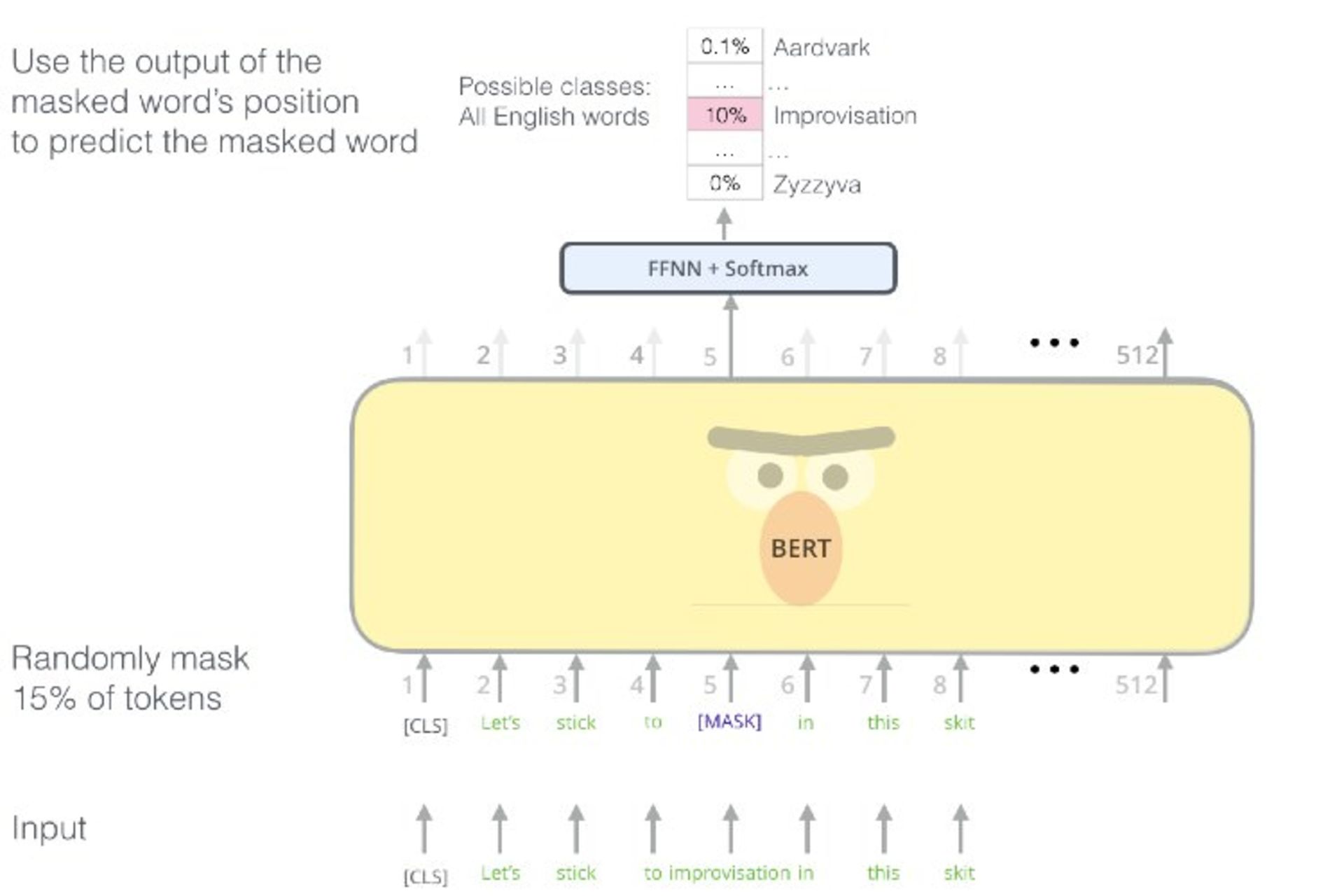
باید اعتراف کرد آنچه باعث شد GPT-2 باارزش شود، بیشک ابعاد بسیار عظیم این مدل است. BERT فقط ۳۴۰ میلیون پارامتر از ساختار متنی را دارد و GPT-2 درمجموع ۱.۵ میلیارد پارامتر.
کواک لی میگوید:
درنتیجهی تلاشهای ما در توسعهی یادگیری متوالی نیمهنظارتی (BERT ،(Semi-supervised Sequence و ELMO نشان دادند با اعمال تغییرات در الگوریتم، امکان دستیابی به دقتهای بالا وجود دارد. اکنون باتوجهبه این نتایج رضایتبخش در مدل زبانی Vanilla، مشخص شده بهبود عملکرد در مقیاس بزرگ نیز امکانپذیر است. این هیجانانگیز است!
این دستاورد با دراختیار داشتن بخش بزرگی از دادههای ردیت (Reddit) امکانپذیر شد؛ چراکه محققان OpenAI به این نتیجه رسیدند که قطعا ردیت محل مناسبی برای بهدست آوردن متون باکیفیت است.
بهطورخاص، OpenAI هوش مصنوعی GPT-2 را برپایهی دادههای متنی دریافتشده از لینکهای Reddit آموزش داد که کاربران و نویسندگان ارسال میکردند. تمام دادههای گرفتهشده از لینکهای وب و... متن بودند؛ بههمیندلیل، به دیتاست بهدست آمده WebText گفته شد.
زمانیکه BERT روی تکالیف زبانی «جای خالی را پر کنید» متمرکز بود، کسی فکرش را هم نمیکرد که GPT-2 بتواند مانند شکسپیر بنویسد. درحقیقت، GPT-2 عملکرد بهتری در مدلسازی زبان دارد. بههرحال، بسیار فوقالعاده است که امروزه، الگوریتمی زبانی دراختیار داریم که میتواند متون تقریبا منسجمی را تولید کند.
هر دو مدل زبانی قصد دارند مدل زبانی پیشآموزشدیده و کارآمدی درزمینهی محتواییمتنی یادگیری انتقالی باشند؛ اما باید پذیرفت که GPT-2 قابلیتهایی ماورائی و البته پنهانی است که رسانههای امروزی با مشاهدهی مطالبی که از GPT-2 دربارهی حیوانات چهارشاخ و اسبهای تکشاخ در کوههای آند منتشر شده، انگشتبهدهان ماندند.
کلام آخر
بعد از خواندن این مطالب اگر احساس کردید چیز زیادی دستگیرتان نشده، جای نگرانی نیست. در اینجا، با اصطلاحات فنی و تخصصی فراوانی روبهرو شدید که هرکدام از آنها بهتنهایی دنیایی دارند. بنابراین، چنانچه علاقهمندید اطلاعات بیشتر و دقیقتری کسب کنید، بهتر است در آینده نیز در زومیت با ما همراه باشید.