استفاده از یادگیری ماشین برای ترجمه زبانهای فراموش شده

در سال ۱۸۸۶، باستانشناسی بریتانیایی بهنام آرتور اِونز، به سنگی باستانی برخورد که حامل حکاکیهایی جالب به زبانی ناشناخته بود. این سنگ متعلق به جزیرهی مدیترانهای کرت (Crete) بود و اونز برای یافتن شواهد بیشتر، بلافاصله به آنجا سفر کرد. طولی نکشید که او تعداد زیادی سنگ و لوح که همگی حکاکیهای مشابهی داشتند، پیدا کرد و آنها را متعلق به ۱۴۰۰ سال پیش از میلاد مسیح دانست.
این سنگنوشتهها حامل یکی از قدیمیترین خطهای کشفشده بودند. اونز عقیده داشت که فرم خطی این زبان، ریشه در تصاویر خطی دوران اولیهی هنر دارد؛ درنتیجه از اهمیت بسیار زیادی در تاریخ زبانشناسی برخوردار است.
او و چند دانشمند دیگر متوجهشدند که این سنگها و لوحها به دو زبان متفاوت نوشته شده بودند. زبان قدیمیتر که به آن «خطی الف (Linear A)» میگویند، مربوط به سالهای ۱۴۰۰ تا ۱۸۰۰ پیش از میلاد است؛ زمانی که جزیره تحت سلطهی تمدن مینوسی در دوران برنز بود.
زبان دیگر که «خطی ب (Linear B)» نام دارد، جدیدتر بوده و در سالهای پس از ۱۴۰۰ پیش از میلاد و در دوران سلطهی میکاییهای یونان، پدید آمده است.
اونز و همکارانش تلاش بسیاری کردند تا این زبانهای باستانی را رمزگشایی کنند ولی هیچیک از تلاشهای آنان به نتیجه نرسید. این مشکل حلنشده باقی ماند تا اینکه در سال ۱۹۵۳، یک زبانشناس تازهکار بهنام مایکل وِنتریس موفق شد زبان خطی ب را رمزگشایی کند.


زبان خطی الف در سمت چپ و زبان خطی ب در سمت راست
راهکار او مبتنی بر دو پیشرفت تعیینکننده بود. اول اینکه ونتریس حدس زد بخش زیادی از کلمات تکرارشده در زبان خطی ب، نام مکانهایی در جزیرهی کرت بود. حدس او درست بود.
پیشرفت دوم او این بود که فرض کرد این زبان، فرمی ابتدایی از زبان یونانی باستان بود. این دید باعث شد که او بتواند بهسرعت سایر زبان را هم رمزگشایی کند. طی این فرایند، ونتریس نشان داد که یونانی باستان، چندین قرن قبلتر از آنچه تصور میشد، بهشکل مکتوب درآمده بود.
کار ونتریس یک دستاورد بسیار بزرگ بود. ولی زبان قدیمیتر، خطی الف، هنوز هم یکی از بزرگترین مسائل روز زبانشناسی باقی مانده است.
دور از ذهن نیست که پیشرفتهای اخیر بشر در ترجمهی ماشینی، بتواند به پیشبرد این مسئله کمک کند.
تنها در چند سال اخیر، مطالعات زبانشناسی بهدلیل وجود پایگاههای دادهی تفسیری عظیم و روشهایی برای یادگیری ماشین از روی آنها، دگرگون شده است. درنتیجهی این امر، ترجمهی ماشینی یک زبان به زبان دیگر کار رایجی شده؛ هرچند نتایج بدوننقص نیست ولی این روشها، راههای کاملا جدیدی برای فهمیدن زبانها پیشروی انسان گذاشتهاند.
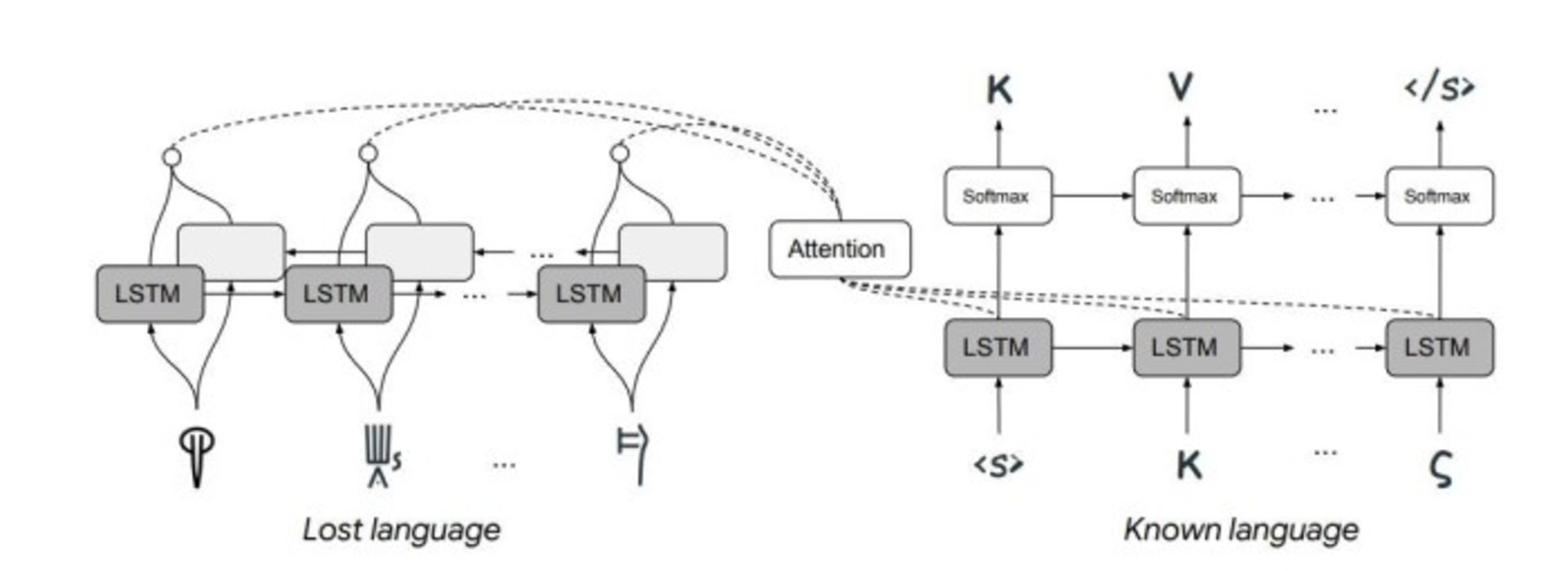
حال با جیامینگ لو و رجینا بارزیلی از دانشگاه MIT و یوآن کائو از آزمایشگاه هوشمصنوعی گوگل در کالیفرنیا آشنا شوید. این تیم موفق شده است تا یک سیستم یادگیری ماشینی طراحی کند که میتواند زبانهای فراموششده را رمزگشایی کند. آنها برای اثبات درستی سیستم خود، با کمک آن زبان خطی ب را (برای اولینبار بهصورت خودکار) رمزگشایی کردند. روش مورداستفادهی آنها با تکنیکهای معمول ترجمهی ماشینی بسیار متفاوت بود.
ابتدا لازم است کمی دربارهی نحوهی عملکرد ترجمهی ماشینی بدانیم. ایدهی بزرگی که ترجمهی ماشینی را امکانپذیر میکند، این است که کلمات، فارغ از زبان آنها، به شکلهای مشابهی با یکدیگر رابطه دارند.
ماشین در متون جستوجو میکند تا ببیند که هر کلمه، چقدر در کنار سایر کلمات دیده میشود
پس در آغاز فرایند، ابتدا این روابط در یک زبان مشخص به یکدیگر نگاشت داده میشوند. این کار نیازمند یک پایگاه دادهی عظیم از متون است. سپس یک ماشین در متون جستوجو میکند تا ببیند که هر کلمه، چقدر در کنار سایر کلمات دیده میشود. الگویی که از این مشاهدات استخراج میشود، نشانهی منحصربهفردی است که یک کلمه را در یک فضای پارامتری چندبعدی مشخص میکند. به عبارت دیگر، هر کلمه را در این فضا میتوان بهشکل یک بردار دید، و این بردار است که با اعمال محدودیتهای قوی، مشخص میکند یک کلمه در ترجمههای ارائهشده توسط این ماشین چگونه ظاهر شود.
این بردارها از چند قانون سادهی ریاضی پیروی میکنند. بهعنوان مثال: ملکه = زن + مرد - پادشاه. و یک جمله را در این فضا، میتوان بهشکل مجموعهای از بردارهای پشتسرهم دید که هر یک دیگری را دنبال میکند تا گونهای مسیر ایجاد شود.
اما ایدهی کلیدی که ترجمهی ماشینی را ممکن میکند، این است که کلمات یک زبان، در زبان دیگر هم به همان نقاط مشابه در فضای پارامتری نظیر میشوند. این قضیه نگاشت یک-به-یک زبانی به زبان دیگر را امکانپذیر میکند.
بدین ترتیب، فرایند ترجمهی یک جمله، به فرایند یافتن مسیرهای مشابه هم در این دو فضا تبدیل میشود. ماشین حتی نیاز به دانستن این ندارد که جمله چه «معنایی» دارد.
فرایند یادشده، شدیدا به پایگاههای دادهی بزرگ وابسته است. اما چند سال پیش، تیمی متشکل از چند محقق آلمانی نشان داد که چگونه با کمک روشی مشابه و با استفاده از پایگاههای دادهی بسیار کوچکتر، میتوان زبانهای کمتر شناختهشده که دادهی متنی زیادی ندارند را هم ترجمه کرد. در این روش، برای اعمال محدودیت باید به روشی متفاوت که تکیهی زیادی بر داده ندارد، عمل کرد.
حال لو و همکارانش یک قدم فراتر رفتهاند تا نشان دهند که چگونه با کمک ترجمهی ماشینی، میتوان زبانهایی که کاملا فراموش شدهاند را رمزگشایی کرد. محدودیتهایی که آنها استفاده میکنند، براساس نحوهی تکامل زبانها در گذر زمان است.
ایدهی آنها چنین است که هر زبانی تنها بهشکلهای معینی تغییر میکند. مثلا در دو زبانی که بههم مرتبط هستند، علائم بهشکلهای مشابهی توزیع میشوند، کلمات مرتبط ترتیب حروف مشابهی دارند و... . با استفاده این قوانین در محدودیتهای ماشین، خیلی سادهتر میتوان یک زبان را رمزگشایی کرد. البته شرط آن، دانستن ریشهی زبان ناشناخته است.
لو و همکارانش این تکنیک را با دو زبان فراموششدهی خطی ب و اوگاریتی امتحان کردند. زبانشناسان میدانند که خطی ب از نسخههای ابتدایی یونانی باستان و اوگاریتی که در سال ۱۹۲۹ کشف شد، از نسخههای ابتدایی زبان عبری است.
با کمک این اطلاعات و محدودیتهای اعمالشده براساس تکامل زبانی، ماشین لو و همکارانش میتواند هردوی این زبانها را با دقت قابلتوجهی ترجمه کند. آنها میگویند: «ما موفقشدیم ۶۷/۳ درصد از نمونههای زبان خطی ب را در سناریوی رمزگشایی به معادل یونانی آنها ترجمه کنیم. تا جایی که میدانیم، تجربهی ما اولین تلاش برای ترجمهی خودکار زبان خطی ب است.»
کار تحسینبرانگیز لو و تیمش قطعا ترجمهی ماشینی را به سطح کاملا جدیدی ارتقا داده است. ولی سؤال جالبی درمورد سایر زبانهای فراموششده مطرح میشود؛ بهخصوص آنهایی که مانند خطی الف هیچگاه رمزگشایی نشدهاند.
در مقالهی این تیم، غیبت زبان خطی الف کاملا احساس میشود. لو و همکارانش حتی به آن اشاره هم نکردهاند؛ ولی قطعا ذهن آنها را مانند هزاران زبانشناس دیگر بهخود مشغول کرده است. با این حال پیشرفتهای قابلملاحظهای لازم است تا بتوان این زبان را توسط ماشین ترجمه کرد. بهطور مثال، هیچکس از ریشهی زبان خطی الف اطلاعی ندارد. تلاشهایی که برای ترجمهی آن به یونانی باستان صورت گرفته، همگی شکست خوردهاند. و این روش جدید بدون دانستن جد یک زبان کار نمیکند.
اما مزیت بزرگ روشهای مبتنیبرماشین این است که میتوان زبانها را یکی پس از دیگری و بدون خستگی امتحان کرد. درنتیجه ممکن است لو و همکارانش زبان خطی الف را با روشی فراگیر (Brute-Force) رمزگشایی کنند؛ یعنی تلاش کنند تا آن را به تمامی زبانهایی که در ترجمهی ماشینی شناخته شده است، ترجمه کنند. اگر موفق به انجام این کار بشوند، قطعا به دستاورد بزرگی رسیدهاند. دستاوردی که حتی مایکل ونتریس را هم شگفتزده خواهدکرد.