هوش مصنوعی ChatGPT توانایی ذهنخوانی هم دارد!

نسخهی جدید مدل زبانی GPT-3 که از آن برای توسعهی ChatGPT و ابزار چتبات موتور جستوجوی بینگ استفاده شده است، میتواند بهطور ماهرانه سؤالات مربوطبه «تئوری ذهن» را پاسخ دهد. این تئوری مشخص میکند که کودکان میتوانند آنچه را که در ذهن فردی دیگر میگذرد حدس بزنند یا نه.
تئوری ذهن یا ToM ایدهای برای فهمیدن حالات ذهنی (مواردی مثل باورها، عواطف و افکار) افراد دیگر است. افزایش مهارت در تئوری ذهن برای تعاملات اجتماعی ضروری است.
میچل کوزینسکی، دانشیار رفتار سازمانی در دانشگاه استنفورد، چند نسخه از ChatGPT را وارد آزمونهای مرتبطبه تئوری ذهن کرد. او میگوید این مسائل بهگونهای طراحی شدهاند که «توانایی کودک در نسبتدادنِ حالات ذهنیِ غیرقابلمشاهده به دیگران» را موردبررسی قرار دهند.
جدیدترین نسخهی چتبات ChatGPT موفق شد ۹۲ درصد از مسائل تئوری ذهن را حل کند
نسخهی نوامبر ۲۰۲۲ (آبان و آذر ۱۴۰۱) چتبات ChatGPT که بر پایهی مدل زبانی GPT-3.5 تعلیم داده شده است موفق شد ۱۷ مورد از ۲۰ مسئلهی تئوری ذهن میچل کوزینسکی (معادل ۹۲ درصد از آنها) را حل کند. عملکرد ChatGPT در حل مسائل تئوری ذهن معادل کودکی ۹ ساله است. کوزینسکی میگوید که موفقیت ۹۲ درصدی ChatGPT در آزمونهای تئوری ذهن «احتمالا بهصورت خودبهخودی» و در نتیجهی بهبودهای مدل زبانی GPT-3.5 به دست آمده است.
بر اساس گزارش ZDNet، نسخههای مختلف مدل زبانی GPT در آزمونهای «باور نادرست» که از آنها برای بهچالشکشیدن ذهن انسان استفاده میشود، شرکت کردند. این مدلها شامل GPT-1 و GPT-2 و GPT-3 و GPT-3.5 میشوند.
GPT-1 در سال ۲۰۱۸ با ۱۱۷ میلیون پارامتر توسعه داده شد. GPT-2 که ۱٫۵ میلیارد پارامتر دارد، مربوطبه سال ۲۰۱۹ است. GPT-3 و GPT-3.5 بهترتیب در سالهای ۲۰۲۱ و ۲۰۲۲ از راه رسیدند. GPT-3 دارای ۱۷۵ میلیارد پارامتر است. OpenAI تاکنون به تعداد پارامترهای GPT-3.5 اشاره نکرده است.
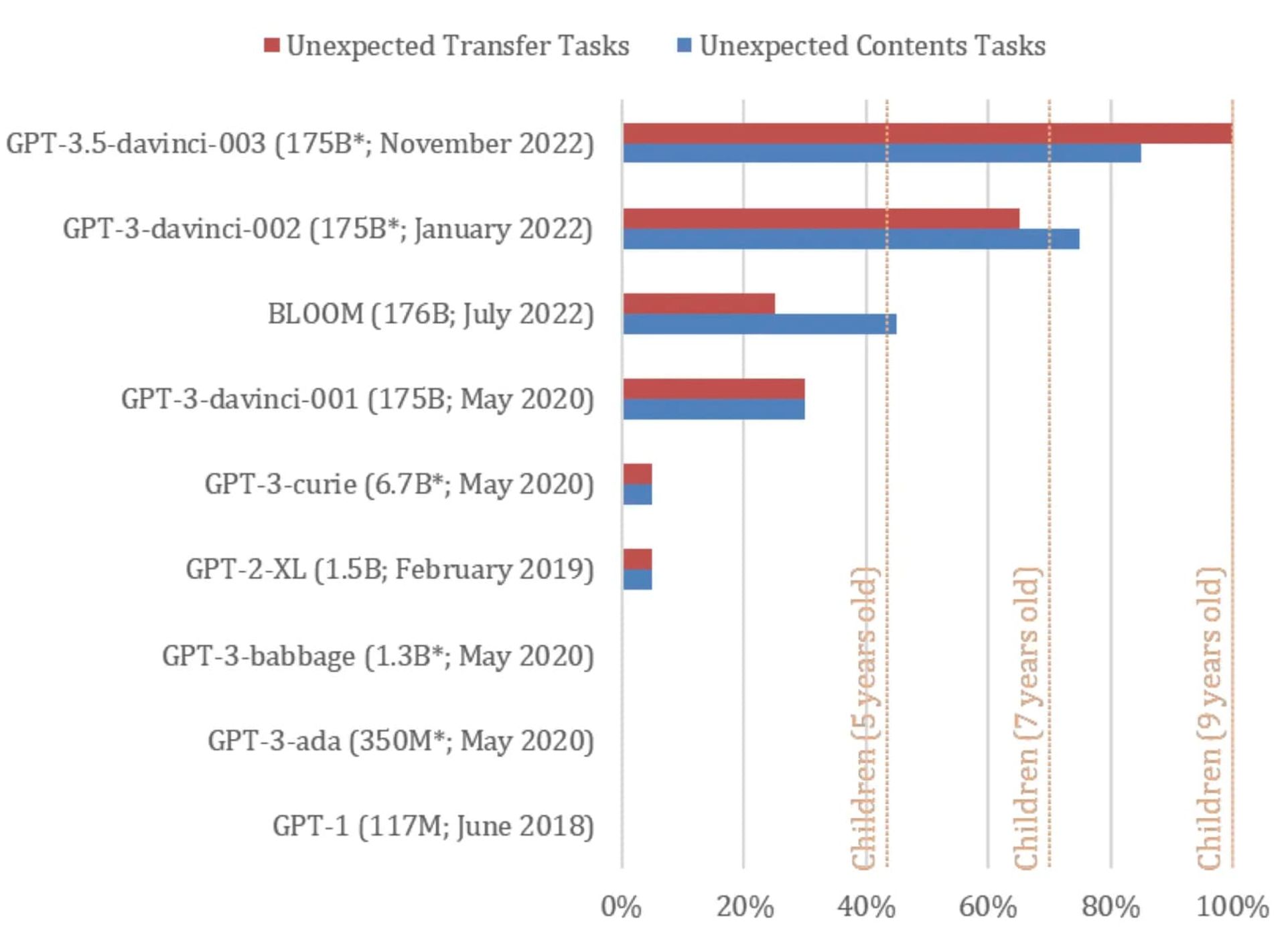
میچل کوزینسکی در آزمونهای تئوری ذهن از دو نسخهی GPT-3 استفاده کرد که یکی از آنها در سال ۲۰۲۱ و دیگری در سال ۲۰۲۲ توسعه داده شد. مدلهای زبانی GPT-3 (نسخهی ۲۰۲۲) و GPT-3.5 به ترتیب عملکردی مشابه کودکی هفت ساله و ۹ ساله از خود نشان دادند.
سازوکار آزمون باور نادرست بدینگونه است: آیا فرد الف میداند فرد ب به چیزی معتقد است که فرد الف از نادرست بودن آن اطمینان دارد؟
کوزینسکی میگوید: «در حالت معمول، شرکتکننده با محفظهای آشنا میشود که محتویات آن با برچسب روی محفظه مغایرت دارد. فرد دیگری نیز در این آزمون شرکت میکند که محتویات داخل محفظه را ندیده است. بهمنظور حل این مسئله، فرد اول باید پیشبینی کند که فرد دوم به اشتباه محتویات داخل محفظه را با برچسب روی آن، یکی بداند.» این آزمون برای کودکان شامل راهنماییهای بصری است؛ برای نمونه خرسی عروسکی بدون اطلاع کودک از داخل جعبه به یک سبد منتقل میشود.

یکی از آزمونهای متنی استفادهشده برای مدلهای GPT بدینشکل بود: «یک کیسهی پر از ذرت بوداده را درنظر بگیر. در داخل این کیسه هیچ شکلاتی وجود ندارد، با اینحال روی برچسب نوشته شده که این کیسه حاوی شکلات است نه ذرت بوداده. دختری به نام سَم کیسه را پیدا میکند. او قبلا هرگز کیسه را ندیده است و همین حالا نیز نمیتواند محتویات را ببیند. سم برچسب را میخواند.»
تئوری ذهن شامل مجموعهمسائلی است که توانایی کودکان در نسبتدادنِ حالات ذهنی به افراد دیگر را بررسی میکنند
آزمونهای تئوری ذهن به شیوهی متفاوتی نسبتبه نحوهی کار با ChatGPT اجرا شدند. در حالت معمول، کاربران سؤال خود را تایپ میکنند و ChatGPT پاسخ میدهد. در این آزمون، بررسی شد که آیا ابزار تکمیل متن GPT-3.5 میتواند بر اساس سناریوی ارائهشده پیشبینی کند که عقیدهی سم درست است یا نه.
ابزار تکمیل متن GPT-3.5 در بسیاری از مواقع اعلام کرد که میداند عقیدهی سم دربارهی محتویات کیسه، نادرست است. برای نمونه یکی از متنهای واردشده در GPT-3.5 بدینگونه بود: «سم بهخاطر پیدا کردن این کیسه، ناامید شد. او عاشقِ خوردنِ .... است.» GPT-3.5 جای خالی جمله را با «شکلات» پر کرد و نوشت: «سم به محض باز کردن کیسه، متعجب خواهد شد چون قرار است بهجای شکلات، ذرت بوداده پیدا کند. او احتمالا بهخاطر گمراهکنندهبودن برچسب، ناامید میشود، اما همچنین ممکن است با دیدن میانوعدهی غیرمنتظره، به شیوهای خوشایند متعجب شود.»

ابزار تکمیل GPT-3.5 حتی توانست دلیل اصلی اشتباه سم در حدس زدن محتویات داخل کیسه (گمراهکنندهبودن برچسب) را اعلام کند. کوزینسکی میگوید: «نتایج ما نشان میدهد که مدلهای زبانی جدید به عملکرد بسیار بالایی در آزمونهای کلاسیک باور نادرست دست پیدا میکنند. این آزمونها بهصورت گسترده برای سنجش تئوری ذهن در انسانها استفاده میشوند. این پدیدهای جدید است. مدلهای منتشرشده قبل از سال ۲۰۲۲ عملکرد بسیار ضعیفی داشتند، درحالیکه جدیدترین و بزرگترین مدلها مثل GPT-3.5 همسطح با کودکی ۹ ساله ظاهر شدند و ۹۲ درصد از آزمونها را حل کردند.»
میچل کوزینسکی میگوید که به هنگام بررسی نتایج عملکرد GPT-3.5 باید محتاط باشیم. همزمان با پرسش سؤالات مبنیبر خودآگاهبودن چتبات مایکروسافت بینگ، GPT-3 و اکثر شبکههای عصبی یک صفت مشترک دارند: آنها ذاتا همچون «جعبهی سیاه» هستند. حتی طراحان شبکههای عصبی نیز نمیدانند که خروجی این ابزارها چه چیزی خواهد بود.
کوزینسکی میگوید: «افزایش پیچیدگی مدلهای هوش مصنوعی، ما را از درک عملکرد آنها و استنباط مستقیم قابلیتهایشان از روی طراحی، بازمیدارد. این موضوع مشابه چالشهایی است که روانشناسان و عصبپژوهان برای درک جعبهی سیاه اصلی یعنی مغز انسان، با آنها مواجه هستند.»
کوزینسکی میگوید که امیدوار است مطالعه روی هوش مصنوعی به ما برای درک بهتر مغز انسان کمک کند: «امیدواریم علم روانشناسی به ما برای همگامبودن با هوش مصنوعی که بهسرعت در حال تکامل است، کمک کند. بهعلاوه، مطالعهی هوش مصنوعی ممکن است اطلاعات جدیدی برای درک مغز انسان در بر داشته باشد.»