
مدل چندحسی متا، آینده جذاب هوش مصنوعی مولد را برای ترکیب دادههای مختلف نشان میدهد

مدل هوش مصنوعی منبعباز جدید متا چند نوع داده ازجمله متن، صوت، تصویر، دما و غیره را باهم ترکیب میکند.
مدل ImageBind درحال حاضر فقط یک پروژهی تحقیقاتی محسوب میشود و کاربرد عملی خاصی برای آن تعریف نشده است. این مدل به آیندهی سیستمهای هوش مصنوعی مولد اشاره دارد که میتوانند تجربهای همهجانبه و چندحسی ایجاد کنند.
مفهوم اصلی ImageBind، ایجاد پیوند میان چندنوع دادهی مختلف است. شاید این ایده کمی انتزاعی بهنظر برسد اما میتواند بهعنوان زیربنای هوش مصنوعی مولد درنظر گرفته شود.
بهعنوان مثال، ابزارهای هوش مصنوعی تولیدکنندهی تصویر ازجمله Stable Diffusion، DALL-E و میدجورنی همگی به سیستمهایی متکی هستند که متن و تصویر را با یکدیگر ترکیب میکنند. این مدلها در دادههای تصویری بهدنبال الگوهای خاص هستند و اطلاعات بهدست آمده را با توضیحات تصاویر مرتبط میکنند. چنین قابلیتی باعث میشود سیستمهای هوش مصنوعی مولد، تصاویری تولید کنند که با ورودی متنی مطابقت دارند. همین ویژگی در بسیاری از ابزارهای هوش مصنوعی که ویدیو یا صدا تولید میکنند نیز وجود دارد.
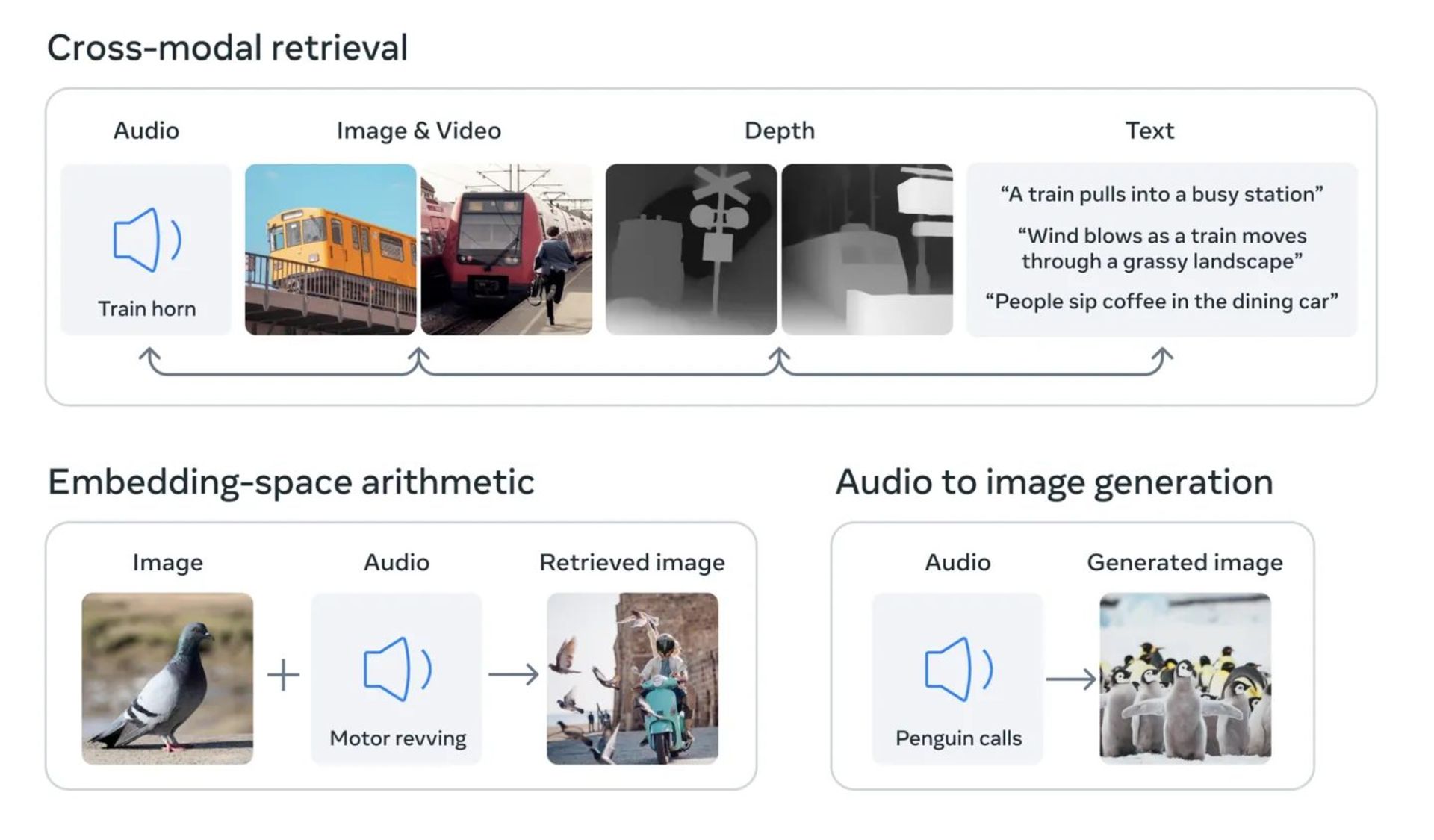
متا میگوید ImageBind اولین مدلی است که ۶ نوع داده را با یکدیگر ترکیب میکند. این دادهها شامل تصویر، اطلاعات حرارتی (تصاویر مادونقرمز)، متن، صوت، اطلاعات عمقی و خوانشهای حرکتی ایجاد شده با واحد اندازهگیری اینرسی یا IMU است. IMUها در گوشیها و ساعتهای هوشمند برای طیف گستردهاز کارها مثل شناسایی حالت افقی و عمومی نمایشگر مورد استفاده قرار میگیرند.
ایدهی متا این است که سیستمهای هوش مصنوعی آینده بتوانند دادههای مختلف را بههمان روشی که سیستمهای هوش مصنوعی کنونی برای ورودی متن انجام میدهند، ترکیب کنند. بهعنوان مثال دستگاه واقعیت مجازی آیندهنگرانهای را تصور کنید که علاوهبر ورودی صوتی و بصری، محیط و نوع حرکت شما را در صحنهی فیزیکی میسازد. شاید از مدل مورد اشاره بخواهید سفر دریایی طولانیمدتی را ایجاد کند و بدینترتیب صحنهای شامل کشتی و دریا بههمراه صدای امواج در پسزمینه ایجاد خواهد شد و تکان خوردن عرشه را درکنار نسیم خنک هوای اقیانوس ارائه میدهد.

متا با انتشار پستی وبلاگی اشاره کرد میتوان جریانهای ورودی حسی دیگری مثل سیگنالهای لمس، گفتار، بو و حتی fMRI مغز را به مدلهای آینده اضافه کرد. این شرکت میگوید مدل هوش مصنوعی ImageBind و نسخههای آیندهی آن، توانایی یادگیری فناوری را به سطح توانایی انسان نزدیکتر میکند.
ورج مینویسد، قابلیتهای آیندهی مدلهای هوش مصنوعی چندحسی فعلاً درحد حدسوگمان است و شاید کاربردهای تحقیقاتی آن بسیار محدودتر باشد. متا سال گذشته مدل هوش مصنوعی جدیدی بهنمایش گذاشت که با دریافت توضیحات متنی، ویدیو تولید میکرد. مدلهایی مثل ImageBind نشان میدهند نسخههای آیندهی این سیستم چگونه میتواند جریانهای مختلف داده مثل صدا و تصویر را برای تولید ویدیوهای بهتر و با کیفیتتر، ترکیب کند.
یکی دیگر از جذابیتهای ImageBind، منبعباز بودن این مدل هوش مصنوعی است که باعث میشود افراد بیشتری آن را مورد بررسی قرار دهند و ازطرفی به بهبود آن کمک کنند.
شرکتهایی مثل OpenAI اعتقاد دارند منبعباز کردن مدلهای هوش مصنوعی برای سازندگان این سیستمها مضر است زیرا رقبا میتوانند از مدلهای آنها کپیبرداری کنند. ازطرف دیگر مهاجمان سایبری میتوانند از مدلهای هوش مصنوعی منبعباز برای مقاصد شوم خود بهره ببرند. البته در سمت مقابل برخی اعتقاد دارند منبعباز بودن مدلها باعث میشود افراد و شرکتهای مختلف نسبتبه رفع عیب و بهبود قابلیتهای چنین سیستمهایی اقدام کنند. علاوهبراین شرکتها با منبعباز کردن مدلهای هوش مصنوعی، بهطور رایگان از تلاشهای توسعهدهندگان شخصثالث بهره خواهند برد و بدینترتیب در هزینههای خود صرفهجویی خواهند کرد.
متا تا کنون برخی مدلهای هوش مصنوعی خود ازجمله LLaMA را بهصورت منبعبار ارائه داده است و این روند با ImageBind همچنان ادامه دارد.

برای اطلاع از تعداد سیمکارتهای مختلفی که به نام شما ثبت شده است و وضعیت آنها راههای مختلفی چون پیامک، اپلیکیشن و وبسایت وجود دارد.

نوبیا با انتشار تصویر رسمی از نسخهی ویژهی Z70S Ultra، طراحی و برخی مشخصات آن را قبلاز رونمایی رسمی تأیید کرد.

شاید بسیاری از کاربران هنوز منتظر دریافت One UI 7 باشند؛ اما سامسونگ توسعهی One UI 8 را آغاز کرده است.

از آهنگ پیشواز ایرانسلتان خسته شدهاید؟ در این مقاله با ۳ روش بسیار ساده برای حذف آهنگ پیشواز ایرانسل در کمتر از یک دقیقه آشنا میشوید.

در این مقالهی آموزشی، روش فعالکردن ریپلای به پیامها در اینستاگرام و دلایل از کار افتادن آن برای برخی از حسابها را شرح خواهیم داد.

موسیقی میتواند حالوهوای پستهای شما را جذابتر کند و با اینکار سطح تعامل و توجه مخاطبان به محتوای شما افزایش مییابد.
مدیرعامل OpenAI میگوید تعاملات به ظاهر ساده و معمولی با ChatGPT دهها میلیون دلار هزینه روی دست شرکت میگذارند.


